论文全名:In-Storage Acceleration of Retrieval Augmented Generation as a Service
摘要
检索增强生成(RAG)服务正在企业环境中迅速普及,因为它们将信息检索系统(如数据库)与大语言模型(LLM)结合在一起,以增强响应生成并减少幻觉 。通过用实时信息检索来增强 LLM 固定的预训练知识,RAG 能够选择性地仅检索最相关的信息,从而有效地将模型的上下文扩展到大型知识库 。因此,RAG 实现了对 LLM 知识的动态更新效果,而无需进行昂贵且耗时的重新训练 。尽管一些部署将整个数据库保留在内存中,但 RAG 服务正越来越多地转向持久性存储,以适应不断增长的知识库、提升实用性并提高成本效益 。然而,这种转变从根本上重塑了系统的性能特征:实证分析表明,“搜索与检索”(Search & Retrieval)阶段成为了端到端延迟的主要来源 。该阶段通常涉及(1)运行较小的语言模型来生成查询嵌入;(2)在不同的数据结构上执行相似度和相关性检查;以及(3)对持久性存储执行频繁的、高延迟的访问 。为了应对这三重挑战,我们提出了一种可变形的存内加速器架构,该架构提供了必要的可编程性,以支持多样的 RAG 算法、动态数据结构和各种计算模式 。该架构还支持在存储内执行较小的语言模型以生成查询嵌入,而最终的 LLM 生成则在 DGX A100 系统上执行 。实验结果表明,与分别使用带 NVMe 存储的 Xeon CPU 和带 DRAM 的 A100 GPU 的传统检索管线相比,其端到端吞吐量分别提高了最高 4.3 倍和 1.5 倍 。
1.介绍
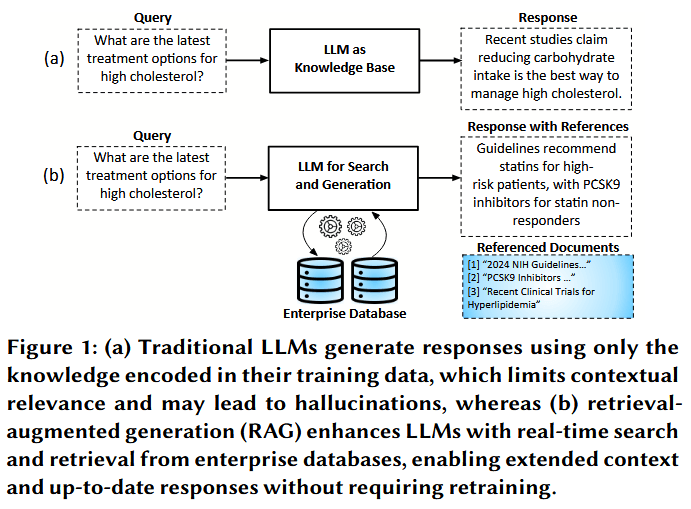
检索增强生成(RAG)将大型语言模型(LLM)的生成能力与信息检索系统(如数据库、知识库和网页)的精确性和上下文相关性结合在一起。因此,RAG 服务(简称 RAGs)使 LLM 能够提供带有数据库中特定来源引用的可验证响应,并降低了可能在企业应用中引发严重法律、财务和知识产权问题的幻觉风险。此外,RAGs 利用组织的内部数据库来增强 LLM,并通过为它们提供最新信息来帮助保持时效性,而无需承担微调或重新训练的高昂成本与挑战 。这些优势推动了 RAGs 在医疗保健、金融、法律和科学出版等领域的迅速普及,在这些领域,保持基于事实并与不断发展的信息保持同步是至关重要的。
从某种意义上说,检索增强生成(RAG)使大语言模型(LLM)能够有效扩展其上下文窗口,将完整数据库的内容纳入其中。上下文窗口是指大语言模型在生成响应时能够考虑的token范围。增加上下文窗口长度的成本很高,因为 Transformer 层(大语言模型的核心组件)的时间复杂度会随上下文窗口长度呈二次方增长(参考文献:1)。因此,仅通过扩展上下文窗口来适配整个数据库的内容,在计算上是不可行的。尽管近期的技术进展(例如谷歌的 Gemini 1.5 Pro)已将上下文长度扩展到了两百万个token,但长上下文大语言模型在上下文规模增大时,仍存在计算成本高、准确率下降的问题,这使其不适合对海量知识进行推理。因此,检索增强生成(RAG)在将外部知识整合到生成式应用中,依然扮演着关键角色。RAG 并非通过物理方式增大上下文窗口,而是对数据库进行检索,仅将相关信息注入上下文窗口,以构建增强后的查询。部分部署为了保证响应速度,会承担将整个数据库加载到内存中的高昂成本 。不过,RAG 正越来越多地转向采用持久化存储,以适应不断增长的知识库规模、增强实用性,并显著提升成本效益。
尽管近期的大量研究都聚焦于加速大语言模型推理,但我们对亚马逊云科技(Amazon Web Services)上端到端RAG的分析揭示了一个不同的瓶颈。基于使用 NVIDIA DGX A100 GPU 对PubMed 数据集(包含 500 万篇文献)进行的各类相似性指标和检索算法的实验,我们发现:平均而言,总运行时间的 61% 消耗在检索与重排阶段,而非大语言模型推理阶段。这一阶段通常包含以下环节:(1) 生成查询嵌入,供语言模型进行相关性评估;(2) 运用各类数据结构与算法执行相似度和相关性检查,这一过程在不同的数据中心部署中可能存在差异;(3) 频繁、高延迟的存储访问中穿插这些计算,这可能会主导整个 RAG 流水线的性能。
为应对这三重挑战,我们提出一种具有变革性的存内加速元架构,以提供必要的可编程性与动态性,从而支持各类 RAG 算法及其动态数据结构与数据形态。该架构不仅能运行嵌入生成(这一过程需要借助语言模型进行推理),同时还能严格遵守存储设备严苛的热功耗限制。我们将这种存内可编程加速方法称为RAGX(检索增强生成加速)。这一设计旨在服务于多种 RAG 场景,这些场景会采用不同的算法与数据结构来执行相似度校验。部分场景依赖各类距离计算,这些计算也以向量嵌入的形式存在于向量数据库中;另一些场景则会统计查询与条目之间关键词的出现频率,同时使用哈希表与倒排索引。此外,这些算法所需的数据结构具有数据依赖的特性,其动态形态会随查询内容而变化。为支持 RAG 中的动态指标,我们还提出了一种全新的元数据导航单元(Metadata Navigation Unit),该单元可直接将数据从存储设备的 NAND 阵列加载到加速器的片上存储器中。
在利用计算与数据的近位部署优势的同时,我们还基于五种不同的端到端 RAG 部署方案,对 RAGX 进行了评估,这些方案均采用了 LLAMA2(34B)模型。由于数据库内容与查询性质都会显著影响检索和响应质量,我们使用了一个包含 5000 万条文本片段和 3800 条 BioASQ 查询的真实 PubMed 数据集进行测试。相较于采用至强(Xeon)CPU 搭配 NVMe 存储用于检索、搜索和增强,并以 DGX A100 GPU 进行 LLM 推理的传统部署方案,RAGX 实现了高达 4.3 倍的端到端吞吐量提升。当把至强 CPU 替换为配备 DRAM 的 A100 GPU 时,RAGX 仍能提供 1.5 倍的端到端吞吐量提升。我们还针对将 LLM 从 LLAMA2(13B)更换为 LLAMA2(70B)的情况进行了严格的敏感性研究,并同时考虑了不同的数据库规模(0.5M、5M、50M 和 500M 条文本片段)。结果表明,即便在 LLM 规模最大的情况下,RAGX 带来的性能收益也会随着数据库规模的增大而提升。
2.RAG:从概念到数据中心部署
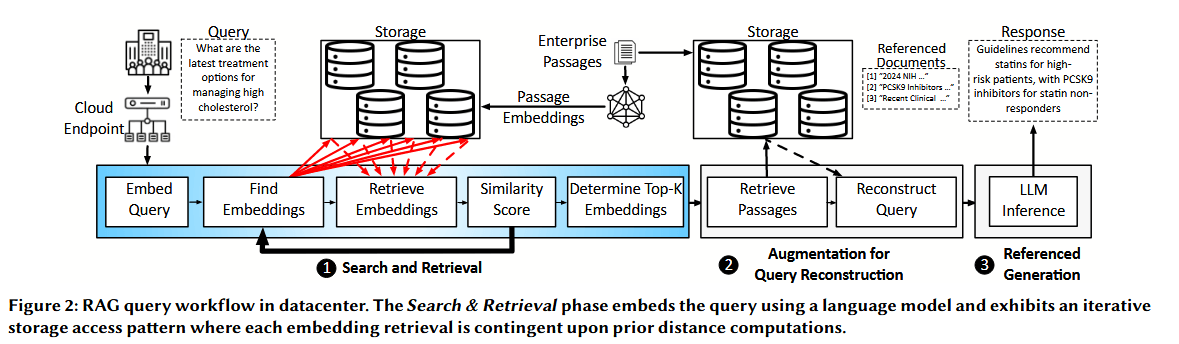
图2展示了亚马逊云科技(AWS)上典型的 RAG 流水线,它包含三个主要阶段:检索与重排、查询重构增强以及参考生成。为了用数据库中的具体信息生成响应,第一阶段会对数据库进行检索,以识别出最相关的条目,这些条目使用的相似度评分在不同的 RAG 部署和算法中存在差异。部分 RAG 算法类别会采用嵌入向量,而另一些则会利用关键词频率。图 2 展示了前者在 AWS 上的部署情况,后者的类别在执行过程中也存在一些差异,这些差异将在 2.3 节中讨论。在图中所示流水线的背景下,本节提供了一个直观的视角,说明迭代式存储访问与相似度评分计算之间的相互作用,如何影响解耦式数据中心内端到端 RAG 的执行过程与性能表现。
2.1 离线向量数据库生成
前提条件与元数据图:为高效执行相似度校验,检索增强生成(RAG)系统会为企业知识库中的文档生成向量数据库表示。这一离线过程仅执行一次,包括将数据库中的每篇文档分割为文本片段,并使用基于 Transformer 的神经网络(如 ColBERT或GTR)对其进行嵌入。这些嵌入将数据库中每条文本片段表示为高维稠密向量,保留了文本的语义信息,这对于相似度校验至关重要。这些嵌入存储在一个使用图结构来加速检索的向量数据库中。这些图(我们称之为元数据)由指向实际嵌入的顶点构成,并且通常存储在 DRAM 中以实现快速导航。虽然图中的每个顶点都指向一个嵌入,但边的存在则表示对应嵌入之间的语义邻近度。因此,在检索以识别与查询最相关、最相似的文本片段时,元数据图能够通过跳过无关部分并探索语义最相关的条目,实现对向量数据库的快速导航。
另一方面,嵌入本身在云环境中通常存储在低延迟的 NVMe 存储驱动器上。原始文本片段则存储在对象存储(如 Amazon S3)中,利用其成本效益来处理大规模非结构化数据。这种多层级方法在性能与成本之间取得了平衡,使检索增强生成(RAG)系统能够高效处理海量数据。向量数据库和元数据图是专门设计的算法技术,用于加速那些在处理查询时与频繁、迭代式存储访问交织在一起的相似度校验。
2.2 在线查询处理
如图 2 所示,部署在解耦式数据中心的 RAG 工作流,始于客户向数据中心网关提交查询,该网关作为整个系统的入口点。在执行基本完整性检查和负载均衡后,查询会被分发至专门的节点,用于执行检索与重排流程。
① 检索与重排:这一阶段首先使用与离线阶段处理文本片段时相同的神经嵌入模型(如 ColBERT或 GTR),将查询转换为向量表示。这一转换至关重要,它使得查询与文本片段的表示能够通过向量距离计算函数(如余弦相似度、ℓ² 范数)进行直接比较。随后,相似度检索会利用存储在 DRAM 中的元数据图,高效遍历数据库并识别出与查询最相似的嵌入。借助元数据图,仅需从向量数据库中以迭代方式检索嵌入的一个子集。每次迭代都会从 NVMe 存储中检索一部分文本片段嵌入,并计算它们各自的相似度评分。然后,基于这些计算结果和图元数据的结构,确定下一批需要从存储中检索的嵌入。这一过程本质上是迭代式的,涉及多轮交替的图遍历、存储访问和评分计算。
在解耦式数据中心中,这些存储请求通过存储访问层进行管理。尽管采用了高性能 NVMe 存储(其提供了业界领先的低延迟本地存储),但每次访问仍会因 PCIe 接口传输和数据检索操作而产生延迟。这一过程的顺序性形成了关键瓶颈,因为每次迭代都依赖于前一次的结果,限制了并行化或预取的机会。这种迭代过程表现为一系列交替的存储访问和相似度计算。这些重复的顺序存储操作累积起来,会大幅增加整体系统延迟。因此,在生产环境中扩展至更大规模的数据库时,RAG 面临着显著挑战,这将在2.4中详细阐述。
② 查询重构增强:检索与重排阶段的目标是识别出与当前查询相似度评分最高的前 k 条文本片段。一旦确定,这 k 条文本片段的 ID 会通过网络发送至查询重构增强节点,在该节点中,主文档数据库(存放原始文档)会被查询,以获取对应的原始文本内容。原始文本通常存储在用于非结构化数据的键值存储中(例如 AWS S3)。尽管该存储层相比 NVMe 存储延迟更高,但这种最终检索在每次查询中仅发生一次,这与检索与重排阶段中对存储的迭代式访问形成了对比。检索到的多条文本片段被用于增强原始查询,以从数据库的上下文信息中创建一个新的查询。因此,通过这种基于相似度的检索与增强,RAG 旨在将大语言模型(LLM)的上下文有效扩展至整个数据库。
③ 参考生成:在 RAG 工作流的最后阶段,增强后的查询会通过网络发送至高性能服务器实例(例如 DGX A100 GPU 集群),该实例运行大语言模型(LLM)推理以生成响应。这一阶段利用 GPU 的计算能力,高效处理增强后的、上下文丰富的查询。生成的响应还会包含对数据库中源文档的具体引用。因此,响应可以被追溯和验证,这对于大多数无法容忍幻觉的企业级应用至关重要。
2.3 检索器中存储与计算的相互影响
在确立了解耦式数据中心中 RAG 的部署架构与工作流之后,我们将深入探讨检索器组件。检索器是利用元数据进行检索、识别出最相关文本片段以供查询增强的模块,这一过程涉及对存储的迭代式访问,因此会产生额外开销。RAG 中使用的检索器可大致分为两类:基于嵌入的检索器和基于关键词的检索器。尽管二者在算法上存在差异,但我们的分析表明,这两类检索器在实现过程中具有相似的结构模式,并且在存储访问与计算方面面临着可比的挑战。
为了更好地理解这两类检索器中的交互关系与瓶颈,我们将其操作概念化为三个层面:用于检索的表示层(位于NVMe 存储)、用于检索的元数据层(存储在 DRAM 中),以及用于检索与重排的计算层。这种概念上的分离使我们能够清晰地识别出在基于关键词和基于嵌入的检索系统中,存储访问瓶颈出现的位置和方式。
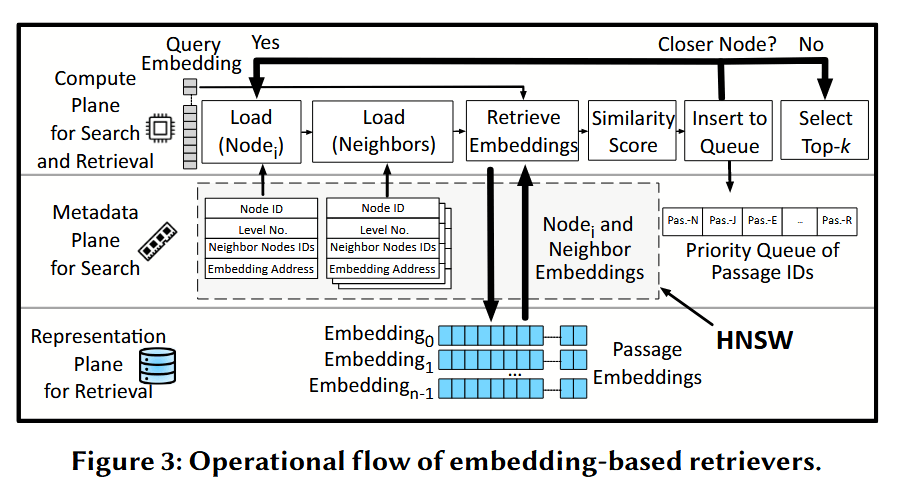
基于嵌入的检索器。这些神经网络,通常是大语言模型的编码器部分 ,它们将查询和文档块编码为能够捕捉语义特征的稠密向量表示(即嵌入) 。嵌入的使用使得系统能够根据概念相似性而非关键词重叠程度来匹配查询和文档,而关键词重叠正是基于关键词的检索器所采用的方法 。图 3 描绘了上述三个概念平面上的搜索与检索工作流 。文档嵌入存在于表示平面中(位于 NVMe 存储内) 。如果没有图元数据,搜索与检索阶段将需要穷举式地检索并对每个文档的嵌入进行相似度计算,这将导致巨大的开销 。在本文中,我们使用 HNSW 元数据图,这是目前最流行的选择之一 。如前所述,该元数据图是在离线一次性构建的,它捕捉了数据库中文档的语义相似性,并表示了它们之间的关系 。因此,这是一种旨在减少存储访问并支持使用图搜索算法的算法优化,以此实现对与查询高度相似文档的高效遍历和识别 。
检索过程始于查询到达并由相同的基于 Transformer 的编码器进行嵌入处理 。接着,从图中指定一个初始顶点作为当前顶点,作为搜索的起点 。从结构上看,HNSW 的设计使得邻近顶点在语义上最为相似 。如图 3 所示,每个顶点都包含一个指向其在 NVMe 存储设备表示平面中对应嵌入的指针 。计算平面利用这些指针从 NVMe 中获取当前顶点及其邻居的嵌入 。然后,它使用距离度量指标(如余弦相似度或 $l^{2}$ 范数)计算相似度得分,对所有邻居进行评分 。这些距离计算决定了查询与潜在匹配文档之间的相似性 。检索器随后选择距离最小(即相似度最高)的一组邻居子集以继续搜索 。相似度得分最高的邻居是图中探索起来最有希望的顶点 。现在,每个邻居都成为一个新的当前顶点,它们的邻居嵌入将从存储中被检索出来,并随后通过距离计算进行检查 。这种利用图进行交织的“存储-计算”搜索循环会不断重复,直到识别出与查询最相似的 top-k 个文档为止 。
如前所述,基于嵌入的检索器的搜索过程中的每一步都依赖于前一步,这引入了顺序依赖关系,使得嵌入的存储访问成为了一个显著的瓶颈 。这一特性使得基于嵌入的检索对存储访问延迟特别敏感,尤其是在处理包含大量文档的大型数据库时 。尽管图元数据防止了从存储中检索和检查每一个嵌入,使搜索更具样本效率,但搜索仍然包含具有计算顺序依赖性的迭代存储访问 。这一主要瓶颈亟需创新方案来管理存储访问开销,即使是在严谨地利用了本地 NVMe 和算法优化的前提下。
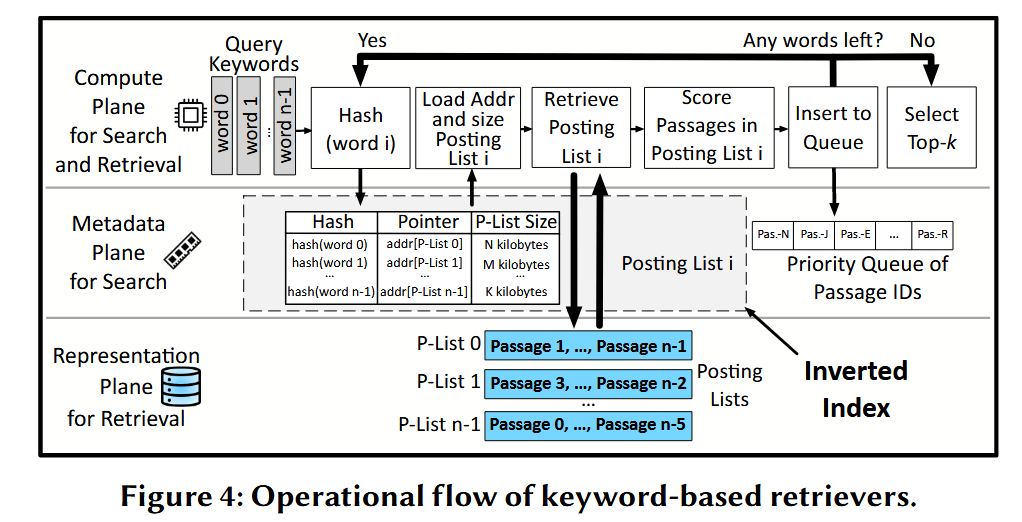
基于关键字的检索器。这些检索器将文档编码为稀疏向量,其中每个元素对应于特定关键字的存在 。这些向量用于将查询中的关键字与包含高频率该相同关键字的文档进行匹配 。图 4 展示了横跨计算、元数据(内存)和表示(存储)三个概念平面的“搜索与检索”工作流 。在驻留于存储中的表示平面里,每个关键字都被分配给一个倒排记录表(posting list) 。倒排记录表包含指向文档数据库中所有包含该关键字的文档的指针,并且还记录了该关键字在相应文档中出现的频率 。在元数据平面中,基于关键字的检索器利用倒排索引(inverted index),它是一个从关键字映射到其指针的哈希表,可用于从存储中检索其倒排记录表 。这种元数据能够实现在常数时间内查找给定关键字在数据库所有文档中的频率 。
搜索过程旨在寻找相关文档,并在查询到达并经历一个取决于检索算法的向量生成过程时开始 。一类较传统的算法(例如,BM25)将查询分词(tokenize)为独立的关键字 。另一类更现代的算法(例如,SPLADEv2 )则将查询传递给基于 Transformer 的编码器以生成嵌入 。这个嵌入向量不仅捕捉了查询中明确存在的关键字,还表示了未被明确提及但在语义上相关的关键字 。嵌入中的每个词(关键字或语义相关的词)随后被哈希映射到一个指针,该指针标识了存储中对应的倒排记录表 。来自标记化关键字或嵌入的指针哈希构成了倒排索引,这是用于“搜索与检索”并保留在内存中的元数据 。给定倒排索引后,关键字的倒排记录表会从表示平面中的 NVMe 存储中检索出来,其中包含了文档 ID 和关键字频率 。
对于查询中的每个关键字,检索器使用倒排索引来查找并定位所有包含这些关键字或其语义相关词的倒排记录表 。随后,倒排记录表中的每个文档会根据评分指标(如 TF-IDF,即词频-逆文档频率)进行评分,以计算哪些文档与查询具有最高的关键字重叠度 。这些分数随后根据它们的重叠得分被插入到优先队列中 。此过程会对查询中的每个关键字重复进行 。完成后,可以从优先队列的前端弹出在关键字重叠度方面得分最高的前 k(top-k)个文档 。尽管这种计算可以为每个关键字独立执行,但系统必须为每个关键字访问存储,并且访问延迟高于计算延迟 。也就是说,存储访问和计算延迟之间的差距使得存储成为了主要瓶颈,从而导致操作被序列化 。
结构相似性与面临的挑战 基于关键字的检索器和基于嵌入的检索器在存储访问模式和计算需求上展现出了结构上的相似性 。它们都高度依赖于迭代式的存储访问,以便从 NVMe 存储中检索数据表示(嵌入向量或倒排记录表)。这两类检索器也都利用一种元数据结构(图或倒排索引)来引导“搜索与检索”过程 。对于这两类检索器而言,关键挑战均在于存储与计算之间的相互依赖和交织执行 。此外,随着数据库规模的扩大,相应的元数据和数据表示(嵌入向量或倒排记录表)也会成比例地增长 。因此,寻找最相关的文本需要进行更大量的存储访问,从而使得这一瓶颈变得更加突出 。
2.4 数据中心中RAG的特征

为了实证量化检索增强生成(RAG)的性能特征和瓶颈,我们在 AWS 上使用五种采用不同检索算法的各异 RAG 进行了全面的实验(见表 1)。
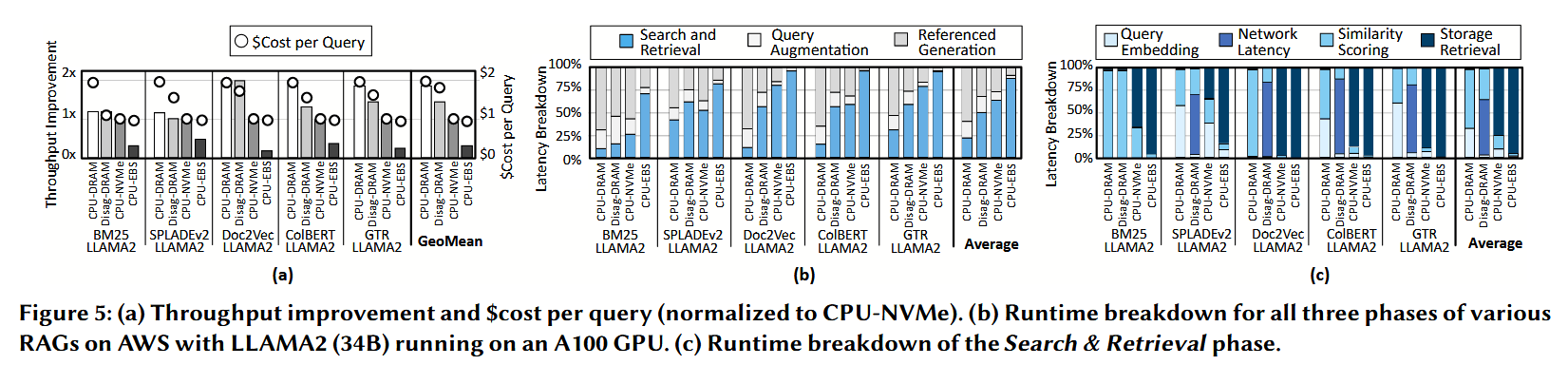
RAG 中的性能与成本权衡 图 5(a) 报告了使用 PubMed 数据集中 500 万个文本的各种检索配置相对于 CPU-NVMe 基线的归一化吞吐量和每次查询的成本($cost)。CPU-DRAM 配置将所有文本嵌入(embeddings)存储在 DRAM 中,并在 CPU 上执行查询嵌入,通过避免高延迟的存储访问,实现了最高的吞吐量——是基线的 1.9 倍。然而,这种性能提升导致每次查询的成本增加了 117%,使其在受成本约束的大规模部署中变得不切实际。这种权衡突显了工业界和学术界越来越多地采用基于 SSD 的存储来存放数据表示(representations)的趋势,旨在吞吐量与存储容量和运营成本之间寻求平衡。最近的研究,例如阿里巴巴的一项研究,强化了这一趋势,并强调基于 SSD 的二级存储对于高效处理现代服务(包括 RAG)中的大规模向量搜索是必不可少的。
搜索与检索(Search & Retrieval)是 RAG 的主要瓶颈 图 5(b) 展示了使用 500 万个文本以及两种 AWS 存储配置(本地 NVMe 和网络 EBS)的基准测试运行时间细分。虽然 AWS NVMe 设置使用的是直连的本地存储,但 AWS EBS 采用的是网络附加存储(network-attached storage)。与当前显示使用 GPU 有利于 LLM 推理而非检索和增强的部署和研究保持一致,我们在 Xeon CPU 上运行这些(检索和增强)阶段,而 LLAMA2 (34B) 则在 A100 GPU 上运行。即使使用本地 NVMe,“搜索与检索”平均也占总延迟的 61%,而当使用网络 EBS 存储时,这一比例会增加到 88%。
在当前系统中,从存储中检索数据主导了“搜索与检索”阶段。 深入探究“搜索与检索”阶段,我们发现从存储中检索数据表示的延迟是当前系统的主要瓶颈。图 5(c) 通过展示“搜索与检索”阶段的运行时间细分量化了这种影响。即使在本地 NVMe 配置中,也有 74% 的运行时间被存储访问所消耗,而使用网络 EBS 存储时这一比例增加到了 94%。使用 HNSW 元数据图在面对 500 万个文本和采用 ColBERT 基于嵌入的检索器的情况下,将存储访问次数减少到了 395 次。尽管如此,存储访问仍然是瓶颈所在。在三星 970 EVO NVMe SSD 上,每次存储访问平均会产生 155 微秒(μs)的延迟,这种延迟与“搜索与检索”阶段的迭代性质相互叠加复合(见第 2 节),进一步加剧了系统瓶颈。
将查询嵌入与“搜索与检索”协同定位(同址执行)是势在必行的。 考虑到像 ColBERT 和 Google 的 GTR(419.62 MB)这类嵌入模型的庞大体积,加速处理的潜力是显而易见的。人们可能会想到将需要使用语言模型进行推理的查询嵌入任务委托(卸载)给 GPU 来处理。然而,在解耦数据中心(disaggregated datacenters)中,这意味着要在单独的计算节点上执行查询嵌入,并为了获取该嵌入向量而产生额外的网络延迟(见第 5.2.5 节)。为了凸显使用解耦 GPU 进行嵌入卸载的局限性,我们分析了一个理想化的场景,在该场景中,所有嵌入向量都完全存储在 DRAM(内存)中。这种设置消除了存储访问的延迟,使我们能够隔离并突出仅由解耦 GPU 架构所引入的开销。如图 5(a) 所示,与非解耦的 CPU-DRAM 系统相比,对于包含 500 万个文本的数据集,这种 Disag-DRAM 系统导致吞吐量降低了 28%(对于 5000 万个文本的数据集则降低了 11%;见图 11)。这是由于网络开销对诸如 Disag-DRAM 之类的解耦设置产生了不利影响(在这种设置中,嵌入生成被卸载到了单独的 GPU 节点上)。我们的测量结果显示,在同一可用区(美国西部区)部署的两个 AWS EC2 实例之间的平均网络延迟为 86 毫秒(这是在一周的时间内随机抽测得出的结果)。如果使用 NVMe 来存储嵌入向量,将会进一步加剧上述结果(见图 11)。对于 500 万和 5000 万个文本的数据集,包含查询嵌入在内的“搜索与检索”阶段仍然分别占据了总运行时间的 24% 和 58%(见图 11)。这种额外的网络延迟完全抵消了通过消除存储开销所带来的性能提升。因此,为了消除网络开销并确保解耦数据中心中查询处理的高效性,消除存储访问瓶颈并将查询嵌入与“搜索与检索”任务协同定位(同址执行)是势在必行的 。
3.RAGX:存内RAG加速
如前所述,检索器频繁地访问 NVMe 存储,提取嵌入(embeddings)或倒排记录表(posting lists),并使用语言模型对查询进行嵌入处理。为了满足这些需求,我们提出了 RAGX,它将一个可编程加速器直接集成到了存储设备内部。这种集成使得该加速器能够使用语言模型执行查询嵌入,并在“搜索与检索”阶段直接从 NAND 闪存阵列中提取嵌入或倒排记录表。我们的目标是:(1)通过存内计算(in-storage computation)最大限度地减少数据移动;(2)在存储设备的功耗限制范围内,高效地支持各种嵌入生成和检索算法。由于散热和可靠性问题,存储设备受到严格的 15 瓦功耗预算的限制。为了解决后一个挑战,我们提出了一种能够“变形”的形态可变加速器,这将在第 4 节中进行讨论。如图 6 所示,本节重点讨论该加速器在 SSD 设备内部的存内集成方案。
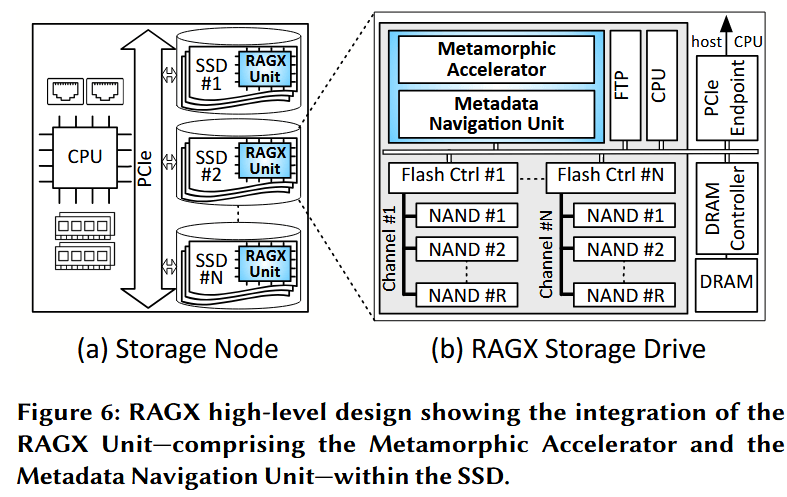
直接访问 NAND 阵列。 如图 6(b) 所示,我们将加速器集成在 SSD 的主控制器旁边。通过这种方式,加速器可以直接与闪存转换层(FTL)及闪存控制器进行交互,从而连接到 SSD 的高速内部总线。该加速器可以在 NAND 阵列与其片上内存(on-chip memory)之间直接传输数据,并在适当的情况下绕过 SSD 的主 DRAM 缓存。这款形态可变加速器内部包含了一个用于执行这些数据传输的 DMA(直接内存访问)引擎。这条直接传输路径通过避免不必要的数据搬运,显著降低了检索操作的延迟,并最大限度地减少了功耗。因此,RAGX 的形态可变加速器得益于更低延迟的数据访问以及与 NAND 阵列的高带宽通信。此外,这种存内集成还有效减轻了数据通过 PCIe 系统互连(总线)进行传输所带来的开销。
3.1 系统集成
为了充分发挥与 NAND 闪存共置的存内加速器的全部潜力,并应对日益庞大的数据库所带来的挑战,RAGX 引入了用于多存储加速的系统原语。这些原语促进了存储器与加速器之间的高效数据移动,管理硬件的动态重配置,并通过扩展的NVMe命令实现与主机系统及其他加速器的直接通信,同时保持与现有系统原语的兼容性。
主机接口(Host interface)。 为了向主机系统暴露 RAGX 的各项功能,我们使用自定义的管理(admin)和 I/O 命令扩展了 NVMe 命令集。这些命令允许主机将查询嵌入(query embedding)以及“搜索与检索”任务卸载(offload)给 RAGX 的形态可变加速器,配置其操作参数,并检索计算结果。扩展后的命令集向后兼容标准的 NVMe 操作,确保 SSD 能够正常运行。
固件集成(Firmware integration)。 我们扩展了 SSD 的固件,加入了一个 RAGX 驱动程序,用于管理主机、SSD 控制器与形态可变加速器之间的通信。该驱动程序负责 RAGX 的任务调度、资源分配和功耗管理,将其操作与 SSD 现有的固件无缝集成。
主机-设备通信(Host-device communication)。 形态可变加速器和闪存存储使用相同的 PCIe 链路与主机进行通信。计算存储(computational storage)内部的一个交换机(switch)会根据请求的类型,将请求路由(转发)到闪存存储设备或加速器。
设备到设备通信(Device-to-device communication)。 RAGX 支持多设备协同执行,以处理更大规模的数据集。正如稍后将讨论的,我们采用了一种数据放置策略,该策略在检索器执行期间避免了设备间和加速器间的通信。然而,在执行的初始化阶段,仍有配置数据需要在不同设备及其形态可变加速器之间进行传输。此外,在多设备执行场景中,我们使用单一的 RAGX 存储驱动器来生成查询嵌入,然后将该查询嵌入广播给其他 RAGX 存储驱动器。为了实现这一点,我们利用了存储设备之间的点对点(peer2peer)PCIe 连接,从而直接绕过了主机 CPU 的参与。
3.2 数据布局策略
用于基于嵌入的多设备存内加速的私有、更小的 HNSW 图。 为了管理超过单个存储驱动器可用容量的数据表示数据库,RAGX 支持多设备存内加速。RAGX 处理的数据是嵌入向量的集合,以及用于基于嵌入的检索器的相关 HNSW 元数据图。HNSW 元数据驻留在 SSD的DRAM 中,但嵌入向量需要存储在 NAND 闪存中。对于多设备执行,需要合理分配嵌入向量和元数据,以保持计算的局部性并避免设备间的通信。因此,我们没有为所有数据使用一个跨多个设备共享的单一 HNSW 图,而是对文本嵌入进行分区(划分),并为每个设备生成一个专用的私有 HNSW 图,该图规模更小。这里的权衡在于,跨所有设备的累积计算量要大于使用单个较大 HNSW 图的情况。然而,在我们的设置下,不存在昂贵的设备到设备通信。此外,这些设备并行执行计算,无需处理中心化的 HNSW 图(这原本会成为一个瓶颈)。另外,由于每个设备都在与其他设备并行搜索一个更小的图,因此召回率(recall)保持不变,甚至可能会有所提高。另一方面,累积的计算量增加了,导致局部能耗上升。然而,总体能耗却是下降的。我们在第 5.2 节中进行了严谨的实证研究,以量化这种数据分区及其权衡的各个方面。
用于基于关键字的多设备存内加速的复制倒排索引。 对于基于关键字的检索器,尽管我们均匀地划分了倒排记录表(posting lists),但元数据(倒排索引)在所有设备之间进行了复制(即每个设备都持有一份完整的倒排索引副本)。主机 CPU 也持有一份倒排索引的副本,并负责识别哪些设备需要处理哪些关键字。CPU 使用其关键字列表来初始化相应的设备。如第 2.3 节所述,在使用基于关键字的检索器时,每个关键字的计算与其他关键字是独立的。因此,参与计算的存储设备在执行期间无需进行通信。在处理完分配给它们的关键字后,所有设备将结果发回给主机 CPU,由 CPU 执行 top-k 选择以用于后续的增强和生成。总体而言,每个驱动器执行局部的相似度搜索,然后在 CPU 上汇总结果以进行 top-k 选择。这一过程确保了对于给定的查询,数据表示数据库能够得到充分的探索,同时充分利用了每个驱动器上局部处理的速度优势。
4.存内RAG的形变加速器
我们的目标是提供一个单一的可编程加速器,该加速器既能支持基于嵌入的检索器,也能支持基于关键字的检索器,同时还要遵守存储设备的散热和功耗限制。对于基于嵌入的检索器,必须将查询转换为嵌入,这一过程涉及运行神经网络(如 ColBERT或 GTR等语言模型)。除了运行此类语言模型外,RAGX 的存内加速器还需要支持高吞吐量的相似度得分计算:对于基于嵌入的检索器,是对高维嵌入进行计算(例如余弦相似度或 $l^{2}$ 范数);对于基于关键字的检索器,则是使用 TF-IDF或 BM25等指标对倒排记录表进行计算。此外,诸如 SPLADEv2等现代基于关键字的检索器采用的是基于嵌入和基于关键字相结合的评分方法。
该加速器架构需要既支持运行基于 Transformer 的语言模型,又支持用于相似度评分的各种形式的数据遍历和计算。基于嵌入的检索器依赖 HNSW 图来识别每个顶点及其邻居的嵌入,而基于关键字的检索器则使用倒排索引来定位查询关键字的倒排记录表。如第 2 节所述,从存储中获取的数据的大小和位置是根据查询动态决定的。对于基于嵌入的检索器,数据大小取决于嵌入的维度以及 HNSW 图中当前顶点的邻居数量。对于基于关键字的检索器,数据大小则对应于查询关键字的倒排记录表中的文本数量。这种动态的、依赖于查询的特性亟需一种机制来高效地解释元数据、获取数据表示(嵌入或倒排记录表),并管理随后的计算工作。
4.1 形态可变加速器
为了应对这些挑战,我们提出了一种变形架构,它能够从基于脉动阵列(systolic-based)的神经加速器“变形”(shape-shifts)为一组并行的 SIMD(单指令多数据流)单元。这是因为各种距离度量指标无法有效地利用二维脉动阵列,而更适合一维的向量执行方式。幸运的是,这些计算是在互不重叠(不相交)的阶段执行的,这就为我们提供了一个机会,能够针对不同形式的执行去重新配置同一个架构。
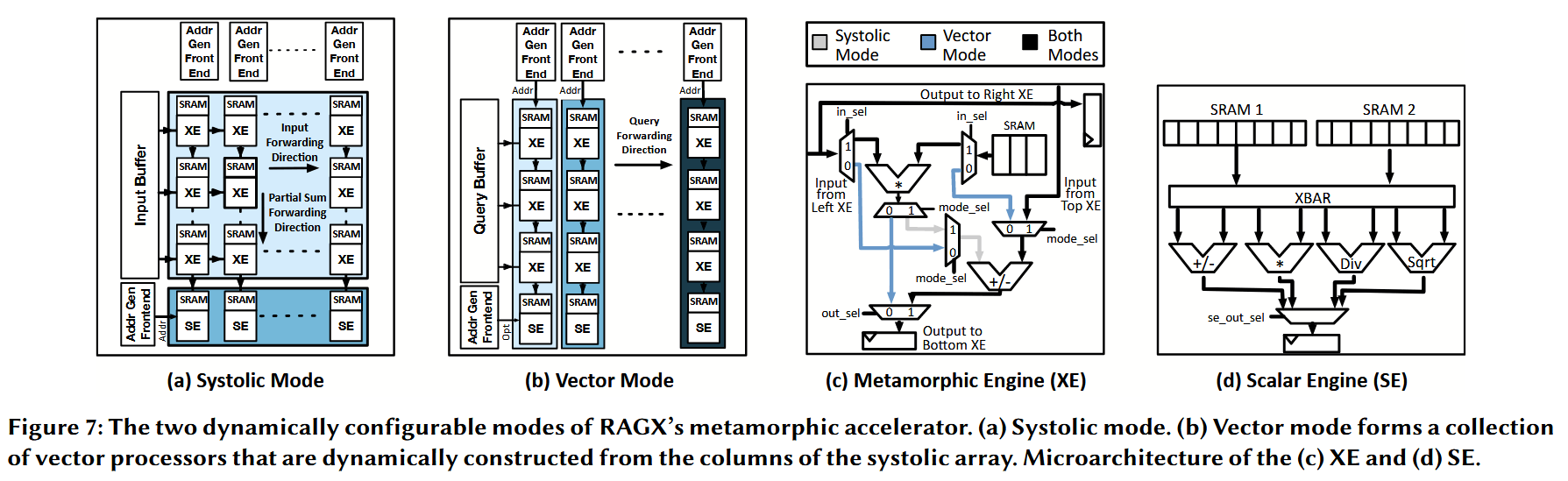
为此,如图7所示的形态可变加速器通过有限的修改,将脉动神经加速器中的“列”(columns)转换成了一组向量处理器(vector processors)。这种动态的形态改变也契合了一个深刻的见解:无论是对于基于关键字还是基于嵌入的检索方法,RAG(检索增强生成)中的距离计算都可以分解为以下两个阶段:
- 一系列简单的逐元素(element-wise)向量操作,这些操作可以被高效地映射到二维脉动单元上。
- 一系列复杂操作,例如归一化(normalization),这些操作可以由一组向量单元来处理。
这一见解使我们能够在处理绝大部分计算时保持二维脉动阵列的高效性,同时引入有针对性的增强设计,以支持全方位的 RAG 操作。为了高效地支持这两种模式(脉动模式和向量模式),处理单元(processing element, PE)被系统性地扩充了额外的算术单元和控制逻辑。
4.2 可变加速器的微结构
如图7所示,该架构支持一种可变形的执行模型,能够动态重新配置由形态可变执行引擎(XE)组成的脉动阵列,以及位于该阵列下方的一组标量引擎(SE)。 脉动阵列的每一列都在 XE 的上方配备了一个向量处理器前端。当架构转换到向量执行模式时,该前端便会被激活。这种变形设计建立在传统的脉动和向量执行范式之上。脉动模式针对通用矩阵乘法(GeMM)进行了优化,而向量模式则针对非 GeMM 计算(例如检索工作负载中的距离函数)。我们观察到,只需对处理单元(PE)的微架构进行极少量的修改,就能将距离函数高效地映射到该架构上(见图 7(c))。在脉动模式下,每个 XE 作为传统的 PE 运行。内部的多路复用器(控制路径设置为 1)被配置为启用脉动执行中典型的操作数和部分和转发路径。每个 PE 包含一个融合乘加(MAC)单元、一个本地权重缓冲区、输入/输出寄存器,以及用于沿着脉动波前传播数据的转发逻辑。
当转换到向量模式时,控制逻辑重新配置多路复用器,以通过垂直的操作数流水线重新路由数据。 每一列 XE 被动态地重新解释为一个向量引擎,其中每个 XE 实现一个流水线阶段。在这种设置下,该架构利用细粒度的垂直流水线来实现向量并行性。每列顶部的向量处理器前端负责获取指令、生成地址并分发控制信号。操作数被存储在每个 XE 内的便笺式存储器(scratchpads)中(这是由脉动模式下使用的权重缓冲区重新用途而来)。相邻 XE 之间的垂直寄存器被增强以充当流水线锁存器,负责将数据和元数据(例如地址)传递到下一个阶段。一列中的所有 XE 都执行相同的操作,该操作由当前的向量指令定义。然而,每一列通过其前端独立运行,维护着自己的程序计数器和指令流。这种设计允许不同的向量引擎并发地执行不同的向量内核。
形态可变执行引擎(XEs)。 每个 XE 支持两种执行模式:在脉动模式下作为 PE 运行,或者在向量模式下作为流水线阶段运行。如图 7(c) 所示,XE 的核心组件包括用于 GeMM 操作的 MAC 单元、在向量模式下用作便笺式存储器的本地缓冲区,以及一组输入/输出寄存器。变形功能是通过由全局执行控制器设置的模式配置位所控制的多路复用器网络来实现的。这些增强功能使得 XE 能够在数据流(脉动)操作和流水线(向量)操作之间切换,同时只需极小的面积开销,并最大程度地复用了现有的 PE 微架构。
标量引擎(SEs)。 为了支持 RAG 所需的复杂标量操作,每一列都在 XE 流水线下方包含了一个 SE。如图 7(d) 所示,这些标量引擎实现了检索评分函数中经常使用的高延迟、资源密集型函数,如除法、平方根和对数操作。例如,SE 可计算 $l_2$-norm(L2 范数)的平方根,或 BM25 评分的对数。在向量模式下,每个 SE 作为其对应向量引擎的扩展来运行,执行伴随向量指令的标量指令。具体而言,每个向量引擎执行形式为 ⟨vector, scalar⟩ 的指令对,其中标量指令通常跟随在向量操作之后,以完成最终的计算步骤。在脉动模式下,SE 被集体重新配置以形成一个独立的水平向量处理器。该处理器的前端单元位于阵列的左下方,如图 7(a) 所示。这种水平向量引擎在神经网络推理期间对脉动阵列进行补充,特别是用于处理需要 GeMM 之外的向量操作(如归一化、偏置加法)的嵌入计算。
此外,在基于嵌入的 HNSW 检索中,SE 在图遍历中发挥着关键作用,即在每次迭代后对顶点得分进行排序。排序后的结果随后被写入驻留在 DRAM 中的优先队列,以此来指导选择下一个要评估的节点。
4.3 元数据导航单元
除了执行计算之外,还需要一个专门的单元将适当的数据提供给形态可变加速器。该单元需要导航元数据(metadata),对于基于嵌入的检索器来说,元数据是 HNSW 图;对于基于关键字的检索器来说,则是倒排索引。重要的一点是,在接收到查询并访问这些元数据结构之前,数据向量的精确大小及其存储位置都是未知的。因此,我们需要一个能够首先遍历元数据的单元。在基于 HNSW 的情况下,它需要确定相邻嵌入的数量及其在存储中的位置,然后将适当的数据从存储器的 NAND 阵列直接加载到片上内存(on-chip memory)中,或者在必要时加载到 DRAM 中。对于基于关键字的检索器也需要采取类似的步骤,只是涉及的对象变成了倒排索引和倒排记录表(posting lists)。请注意,这只是“搜索与检索”迭代过程中的一个步骤。在确定了数据大小之后,才能正确配置形态可变加速器以执行计算。
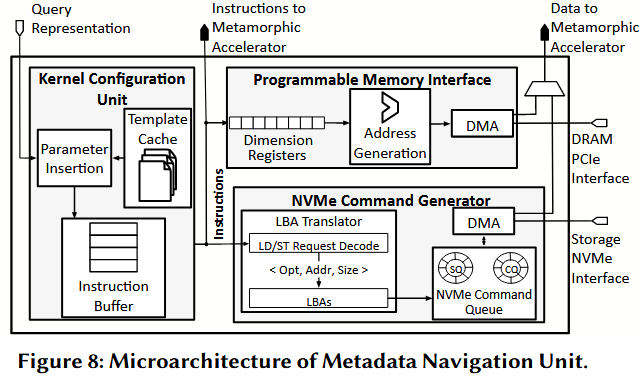
为了满足形态可变加速器这种依赖于数据的配置和设置需求,我们引入了元数据导航单元(MNU),如图 8 所示。MNU 集成了为应对上述挑战而量身定制的三项核心功能:
- 它获取存储在 DRAM 中的元数据,以确定需要从存储器中检索的数据表示的地址和大小。
- MNU 通过其内部集成的 NVMe 命令生成器,生成用于检索所需数据表示的 NVMe 命令。这些命令使数据能够高效地搬运到所提出加速器的片上便笺式存储器中以进行计算。
- MNU 使用参数化的预编译内核模板(kernel templates)来调度计算。在运行时,MNU 会填充内核模板的参数(例如嵌入向量的形状或倒排记录表的大小),从而根据查询要求从模板中生成定制的内核。这种灵活的方法既避免了完整的运行时编译开销,又能适应基于嵌入和基于关键字检索器的多样化工作负载。
以下是 MNU 各个关键模块的具体说明:
元数据解释 (Metadata interpretation)。 MNU 的首要任务是定位并确定存储在 NVMe 中依赖于查询的数据表示的大小。元数据从 DRAM 中获取,并根据检索方法的不同而有所差异。对于基于嵌入的检索器,元数据标识了在图遍历中与当前顶点相关的嵌入,以及其在元数据图中的邻居。相应嵌入的大小计算为:嵌入大小 × 邻居数量。对于基于关键字的检索器,元数据将关键字链接到倒排索引中对应的倒排记录表。此时,倒排记录表的大小取决于包含每个关键字的段落数量。通过确定数据表示的大小,MNU 确保内存访问请求是针对查询的具体需求量身定制的,从而优化了检索效率。
特定于检索器的内核模板 (Retriever-specific kernel templates)。 接下来,为了处理各种检索算法,MNU 利用了特定于检索器的内核模板。这些模板对基于嵌入和基于关键字的代码高级结构进行了编码,并为数据大小和维度等参数留出了占位符。在基于嵌入的检索中,模板指定了参数化分片(parametric tiling)以及嵌入到计算单元的映射方式,这些都将根据运行时的数据大小来决定。对于基于关键字的检索,模板描述了用于优先级队列管理的评分操作。通过在离线状态下预编译这些模板并在运行时实例化它们,MNU 避免了即时编译的开销并保持了执行效率。
内核配置单元 (Kernel configuration unit)。 在特定于检索器的内核模板基础上,MNU 结合了一个内核配置单元,该单元使用从元数据中获取的参数来动态创建这些模板的实例。该单元包含三个关键组件:模板缓存、参数插入逻辑和指令缓冲区。模板缓存存储了用于常见检索任务的预编译模板。参数插入逻辑使用运行时值(如嵌入维度、邻居数量或倒排记录表大小)来替换模板中的占位符。随后,指令缓冲区对实例化的指令进行组装,并启用指令级并行性以优化执行。例如,在基于嵌入的检索中,该单元获取指定相邻顶点数量和嵌入维度的元数据,将这些参数填充到相应的内核模板中,然后将其分发给计算单元。
可编程内存接口 (Programmable memory interface, PMI)。 为了处理基于嵌入和基于关键字的数据表示的动态且可变维度,MNU 引入了一个支持多维内存访问模式(具有可配置的边界和步长)的可编程内存接口。PMI 包含三个关键组件:维度寄存器、步长计算器和地址生成单元。维度寄存器存储运行时确定的数据大小,例如倒排记录表的长度或嵌入维度。步长计算器计算用于访问多维数据布局的内存步长,而地址生成单元则针对嵌套循环和不规则数据结构发出内存获取命令。对于基于嵌入的检索器,PMI 会动态地访问与可变数量邻居相对应的嵌入;对于基于关键字的检索器,它则遍历长度各异的倒排记录表,从而以最小的开销确保高吞吐量的数据访问。
NVMe 命令生成 (NVMe command generation)。 为了将内部获取请求转换为标准的 NVMe 读取命令,MNU 内部集成了一个 NVMe 命令生成器。该模块由三个关键元素组成:命令队列、LBA(逻辑块地址)转换器和 DMA 引擎。命令队列负责管理挂起的 NVMe 请求,以最大化存储带宽的利用率。LBA 转换器将从元数据推导出的逻辑地址转换为 NVMe 存储的物理逻辑块地址。DMA 引擎支持分散-聚集(scatter-gather)操作,能够将不连续的数据区域高效地传输到内部缓冲区中。通过利用存储设备的内部带宽并绕过传统的 PCIe 接口,NVMe 命令生成器有效降低了数据传输延迟和功耗。例如,在为基于关键字的检索器获取倒排记录表时,DMA 引擎会将所需的存储区域合并到一个连续的片上缓冲区中,从而优化数据移动。
将模板映射到加速器 (Mapping templates to the accelerator)。 MNU 会根据检索类型和查询的特定参数,决定如何将数据表示映射到形态可变加速器上。对于基于嵌入的检索器,系统会获取大小为 D 的查询向量及其 K 个邻居的嵌入,并按如下方式映射:查询嵌入被展开并分配到每个 XE(执行引擎)的 N 个向量通道(vector lanes)上,而 K 个邻居的嵌入则分布在 N 个向量处理器上,其中每个 XE 负责处理嵌入维度的一个特定片段。对于基于关键字的检索器,系统获取长度为 L 的倒排记录表并进行映射,使得特定于词项的元素(如词频、文档长度归一化)跨向量通道进行向量化,而倒排记录表中的多个文档则分布在 N 个向量处理器上。这种分层映射机制确保了形态可变加速器中的所有 XE 都能被基于嵌入和基于关键字的工作负载高效利用,同时能够动态适应数据的物理布局和查询特征。
编译器支持 (Compiler support)。 对于通过语言模型进行的查询嵌入,我们依赖于先前的工作,该工作提供了一个用于端到端神经网络加速的开源编译器。之所以可行,是因为在脉动模式(systolic mode)下,形态可变加速器的运作方式类似于传统的神经加速器。该编译器还提供了对向量执行的支持,我们对其进行了利用和修改,以便在“搜索与检索”阶段为相似度检查生成参数化内核。同时,我们为 MNU 专门开发了一个自定义的编译模块,以支持 HNSW 图和倒排索引结构。
5.实验评估
5.1 实验方法
基准测试 (Benchmarks)。 表 1 总结了五个端到端的 RAG 基准测试,它们代表了图 2 所示的 RAG 流水线。 我们使用了 RAGGED 基准测试套件,并加入了额外的基准测试以扩大评估范围。在“搜索与检索”阶段,我们使用未修改的默认版本 Pyserini 来实现 BM25,使用官方 GitHub 仓库实现 SPLADEv2,并使用 Faiss 的 HNSW 实现基于嵌入的检索器,同时启用了所有默认优化和多线程。对于“参考生成”阶段,我们使用部署在两张 A100 GPU 上的 Meta LLAMA2 (34B) 模型,并结合了 TensorRT-LLM 和张量并行技术。输入平均包含 850 个 token,最大上下文长度为 4096 个 token,批处理大小(batch size)为 1(在敏感性研究中最高可达 256)。查询数据集指定 54 个输出 token 作为黄金标准答案(golden answer),这与先前研究建议的检索输出 $\le 64$ 个 token 以保持高召回率的结论一致。在敏感性研究中,我们将其扩展到 512 个输出 token。在所有评估中,我们将 Top-k 设置为 100。
数据集与数据库生成 (Dataset and database generation)。 我们使用 PubMed 生物医学数据库,包含四种数据集规模:5 亿(500M)、5000 万(50M)、500 万(5M)和 50 万(0.5M)个文本分块。为了适应 5 亿文本分块的数据集,我们使用随机生成的嵌入对 PubMed 的 5000 万个段落进行了数据增强。对于基于嵌入的检索,嵌入由 GPU 生成,而 HNSW 索引(Faiss,$M = 32$,$ef_construction = 100$)则在 CPU 上构建。按照先前的工作,我们将 0.5M、5M、50M 和 500M 段落的 $ef_search$ 分别设置为 375、750、1500 和 3000,以在数据集规模扩展时保持一致的召回率。对于基于关键字的检索器,BM25 使用 Pyserini 构建倒排索引,而 SPLADEv2 在生成索引之前对段落进行嵌入。基于嵌入的检索的向量数据库大小计算公式为 $P \times D \times T$,其中 $P$ 是文本分块数,$D$ 是嵌入维度,$T$ 是数据类型大小(4 字节)。例如,对于 0.5M 规模,ColBERT 需要 $500K \times 128 \times 4 = 256\text{ MB}$;对于 500M 规模,需要 $500M \times 128 \times 4 = 256\text{ GB}$。而 GTR 则分别需要 $500K \times 768 \times 4 = 1.5\text{ GB}$ 和 $500M \times 768 \times 4 = 1.5\text{ TB}$。对于基于关键字的检索,存储空间取决于唯一 token 的数量和索引结构。BM25 在 0.5M 规模下需要 0.36 GB,在 500M 规模下需要 320 GB。SPLADEv2 在 0.5M 规模下需要 0.18 GB,在 500M 规模下需要 178 GB。我们使用 3800 个 BioASQ 查询进行评估,以确保所有系统之间的公平比较。
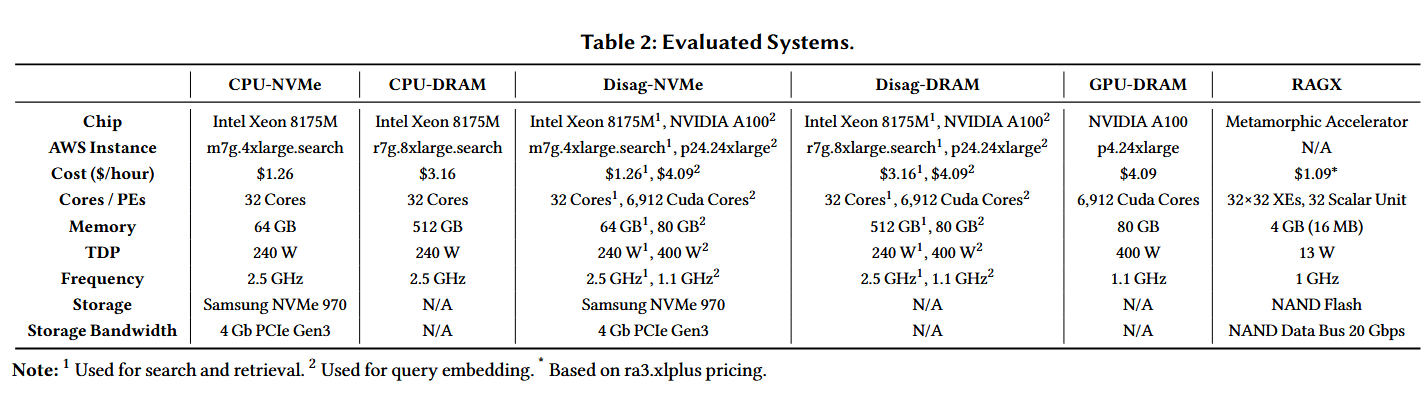
基准系统 (Baseline systems)。 我们将 RAGX 与以下系统进行了比较。表 2 详细列出了每个系统“搜索与检索”阶段的规格参数。
- CPU-NVMe(基准):在 CPU 上对查询进行嵌入,数据表示(嵌入/倒排记录表)存储在直连的 NVMe SSD 上,元数据(HNSW/倒排索引)缓存在 DRAM 中,并由同一个 CPU 执行检索。
- CPU-DRAM:在 CPU 上对查询进行嵌入,数据表示和元数据都缓存在 DRAM 中,由同一个 CPU 执行检索。
- Disag-NVMe:在 GPU 上对查询进行嵌入,嵌入通过网络(100 GbE 以太网)传输到 CPU 节点,该 CPU 节点执行“搜索与检索”,数据表示存储在 NVMe SSD 上,元数据缓存在 DRAM 中。
- Disag-DRAM:在 GPU 上对查询进行嵌入,嵌入通过网络传输到 CPU 节点,该 CPU 节点执行“搜索与检索”,数据表示和元数据均存储/缓存在 DRAM 中。
- GPU-DRAM:查询嵌入和检索均在同一个 GPU 上执行,所有数据表示和元数据都缓存在 GPU 显存中(代表理想化的零延迟网络通信)。
对于所有系统(包括 RAGX),我们使用表 2 中的 EC2 实例进行“搜索与检索”阶段,文本块存储在 AWS S3 上;并在 DGX-A100 集群(AWS p4.24xlarge 实例)上执行“参考生成”,分别使用 1 张、2 张和 4 张 A100 GPU 来运行 LLAMA2 (13B)、LLAMA2 (34B) 和 LLAMA2 (70B)。
基准测量 (Baseline measurements)。 我们参考 AWS 博客和示例代码,在 AWS SageMaker 上部署了我们的基准测试。这种设置允许我们处理自定义数据集(PubMed),生成向量数据库,并将数据表示存储在 NVMe、DRAM 或 EBS 上。在“搜索与检索”阶段,我们配置了 EC2 实例(见表 2),这些实例从 AWS S3 获取 Top-k 段落,并将它们发送到 AWS p4.24xlarge GPU 实例以进行“参考生成”。我们通过运行 BioASQ 的 3800 个查询来执行实际测量,其中每个查询都会遍历 §2.2 中描述的整个 RAG 流水线。对于每个阶段,我们使用集成到代码中的计时器来测量运行时间,以确保测量的精度和准确性。所有结果均基于 3800 个查询的延迟中位数,以保证评估的准确性。
RTL 实现与原型设计 (RTL implementation and prototyping)。 形态可变加速器(metamorphic accelerator)使用 Verilog 实现,并使用 Synopsys Design Compiler 2023.09 结合 FreePDK 45 nm 标准单元库进行综合,实现了 1 GHz 的时钟频率。
形态可变加速器模拟器 (Metamorphic accelerator simulator)。 我们为 RAGX 加速器开发了一个周期级(cycle-level)模拟器,以评估其性能和能耗。 我们的模拟器对所提出加速器(§4)的所有部分进行了建模,并考虑了所有关键组件:NVMe 闪存阵列读取、内核调度的控制逻辑、处理单元上的执行时间、使用 MNU 从 DRAM 进行的元数据遍历,以及在各阶段之间传输数据的网络延迟(因为 RAG 部署在解耦的数据中心环境中)。对于基于嵌入的检索,我们使用 §4.3 中描述的编译器来编译嵌入模型。为了模拟整个“搜索与检索”阶段,我们从基准运行中生成追踪数据(traces),这些数据捕获了系统如何遍历 HNSW 图(基于嵌入)或倒排索引(基于关键字)。这些追踪数据包含了基于嵌入检索的顶点评分序列,以及基于关键字检索的倒排记录表访问情况。我们使用这些追踪数据在模拟加速器上调度指令,并用实际的元数据值实例化模板内核。NVMe SSD 的访问延迟使用一个开源模拟器(参考文献:2)进行建模。这种方法使我们能够准确测量从数据访问到计算的每一项操作的性能和能耗,从而在各种场景下对 RAGX 的能力提供全面的评估。
RAGX 性能测量 (RAGX performance measurement)。 目前,在云端实际部署研究型芯片是不可行的。我们遵循云端加速器研究的标准方法,即将实际测量与严谨系统的模拟相结合。为了保留解耦数据中心的开销,我们系统地将嵌入、搜索和检索时间替换为 AWS 上 CPU-NVMe 基准测试中的相应操作,以确保涵盖来自其他阶段的网络延迟和可变性(例如 S3 访问、用于查询重建的增强操作以及参考生成)。我们对所有 3800 个 BioASQ 查询重复此过程,并报告延迟中位数,以便捕捉到异常值的影响。
5.2 实验结果
5.2.1 吞吐量与成本分析
吞吐量测量方法: 为了进行吞吐量测量,我们获取了数据集中所有 3,800 个 BioASQ 查询在每个基准测试下的延迟。基准系统在 AWS 上运行;而对于 RAGX,我们通过模拟获得“搜索与检索”阶段的延迟,并从 AWS 实际测量中获取“查询重建增强”和“参考生成”阶段的延迟。随后,我们为每个基准测试生成追踪数据(traces),通过在所有系统中使用一致的随机种子,模拟符合泊松分布(Poisson-distributed) 的查询到达过程。我们开发了一个分析模型来衡量吞吐量,将查询到达率 $\lambda$ 从每秒 1 个请求逐步增加到 100 个(步长为 0.1),并对每个实验重复 10 次。我们报告的结果针对 CPU-NVMe(基准)进行了归一化,此处吞吐量定义为:在系统处理查询且不产生队列堆积或延迟显著增加的情况下的最高 $\lambda$ 值。
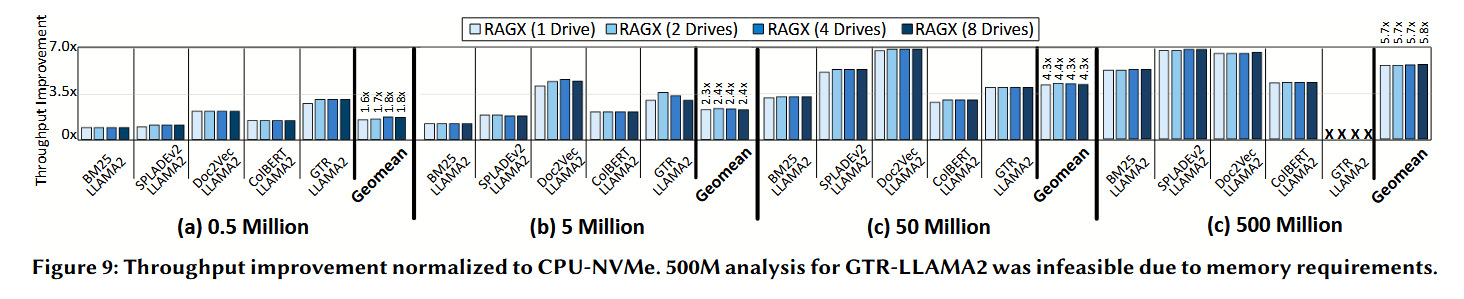
图 9 展示了 RAGX 与 CPU-NVMe 相比在不同数据集规模、检索器类型和驱动器(SSD)数量下的吞吐量提升。 平均而言,对于包含 0.5M、5M、50M 和 500M 段落的数据集,RAGX 分别实现了 1.6 倍、2.3 倍、4.3 倍和 5.7 倍的吞吐量增长。随着数据集规模的扩大,RAGX 的性能优势愈发显著(500M 相比 0.5M 平均提升了 3.6 倍),证明了其在大规模数据库处理中的高效性。对于基于嵌入(embedding-based)的检索,其提升比基于关键字的检索更为显著,因为 RAGX 降低了存储访问延迟,并加速了相似度评分和查询嵌入生成。例如,当数据集从 0.5M 扩展到 500M 时,GTR-LLAMA2 相比 BM25-LLAMA2 的性能提升从 1.9 倍增长到 2.7 倍。此外,随着驱动器数量从 1 个增加到 8 个,RAGX 始终保持了稳定的吞吐量提升,展现了在横向扩展(scale-out) 配置下的效率。为了探究 RAGX 性能提升的来源,我们在图 10 中进行了详细的运行时间分解分析。
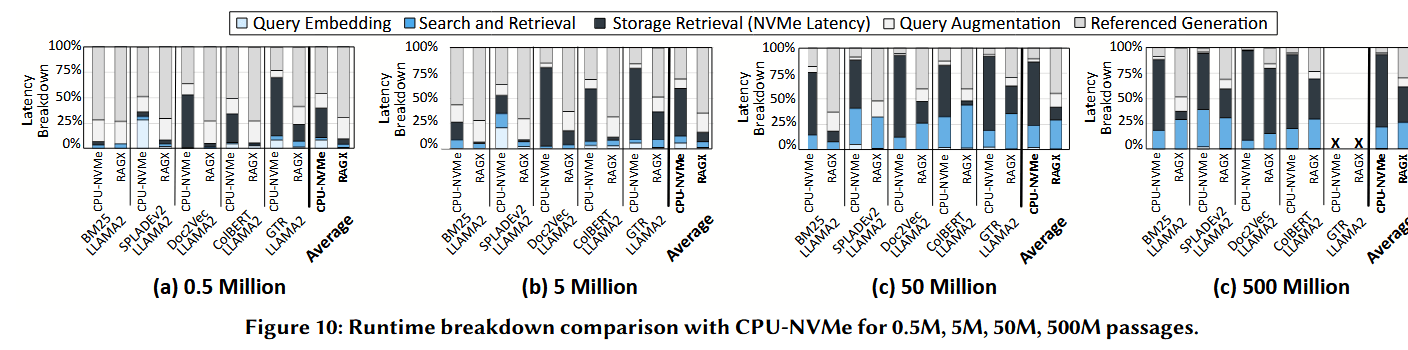
NVMe 检索延迟的降低 与 CPU-NVMe 将 26.6%、47.7%、63.2% 和 75% 的运行时间耗费在存储访问上相比,RAGX 显著降低了 NVMe 读取延迟,将该比例分别降至 4.1%、6.7%、12.8% 和 40%(对应 0.5M 到 500M 规模)。RAGX 中剩余的存储访问延迟主要源于 NAND 阵列本身的物理读取时间。
- 对于 GTR-LLAMA2(50M 数据集),NVMe 延迟占比从 72% 降至 27%,带来了 2.9 倍的加速。
- ColBERT-LLAMA2 在所有基于嵌入的检索器中降幅最大,这得益于其较小的嵌入尺寸。
- 对于 BM25-LLAMA2 等基于关键字的检索器,其影响随数据集规模增加而增大。在 50M 段落规模下,RAGX 通过消除 PCIe 延迟,将 BM25-LLAMA2 的 NVMe 延迟占比从 60.9% 降至 10.3%。
随数据集规模增长的性能表现
RAGX 展示了随数据集规模增长而递增的性能优势,能够高效处理搜索大规模数据库所需的更高频次的存储访问。
- 例如,GTR-LLAMA2 在 0.5M 规模下平均每查询触发 347 次存储访问,在 50M 下增至 1493 次,而 RAGX 的归一化吞吐量在此扩展过程中提升了 1.5 倍。
- 同样,ColBERT-LLAMA2 的存储访问次数从 0.5M 的 393 次增加到 500M 的 3023 次,RAGX 为其提供了 2.9 倍的吞吐量提升。这突显了 RAGX 在缓解存储开销和加速大库检索方面的有效性。
跨检索器的性能表现
随着数据集规模增长,RAGX 在各类检索器上均表现出更佳性能,尤其在基于嵌入的检索器上提升显著。
- 对于 GTR(5M 数据集),与 CPU-NVMe 相比,RAGX 将嵌入生成时间缩短了 12 倍,相似度计算时间缩短了 37.6 倍,从而实现了 3.1 倍的吞吐量提升。
- 这种性能增益也延伸到了 SPLADEv2 等基于关键字的检索器。在 0.5M 数据集上,“搜索与检索”占端到端时间的 32%,其中 82% 耗费在查询嵌入上。随着规模增长(50M),NVMe 访问和相似度评分占据主导,使“搜索与检索”占比升至 93%。随着运行时间占比的这种偏移,RAGX 为 SPLADEv2 提供的加速比从 0.5M 的 1.1 倍增长到 500M 的 6.8 倍。
多存储驱动器下的性能趋势
当将数据表示(representations)分布在多个驱动器上时,RAGX 保持了稳定的性能。在 50M 规模下,RAGX 使用 2 个驱动器实现了 4.4 倍提升,使用 4 或 8 个驱动器实现了 4.3 倍提升(相对于 CPU-NVMe)。
- 所提出的数据放置策略对关键字和嵌入基准测试均有效:使用 8 个驱动器时,BM25-LLAMA2 提升 3.2 倍,GTR-LLAMA2 提升 4.1 倍。
- 这种性能源于 RAGX 的并行执行策略:在每个驱动器中并发执行计算,并在增强服务器的 CPU 上汇总 Top-k 结果。基于嵌入的检索器在性能上的微小波动是由图结构和遍历模式的变化引起的。
查询嵌入与检索协同部署(Co-location)的收益
在解耦数据中心(disaggregated datacenters)中,将查询嵌入(query embedding)任务卸载到独立节点会引入额外的网络延迟(平均 86 毫秒),用于将嵌入向量传输至检索节点。
- 尽管 GPU 能够将 50M 规模下的嵌入生成时间降至仅占总运行时间的 1%,但由于网络传输开销,Disag-NVMe 相比 CPU-NVMe 仍增加了 11% 的额外开销。
- 通过将嵌入与检索协同部署,RAGX 消除了这一开销。其专门设计的形态可变加速器通过复用硬件资源,同时加速了查询嵌入和相似度搜索,使 RAGX 在 50M 规模下的性能达到 Disag-NVMe 的 4.3 倍。
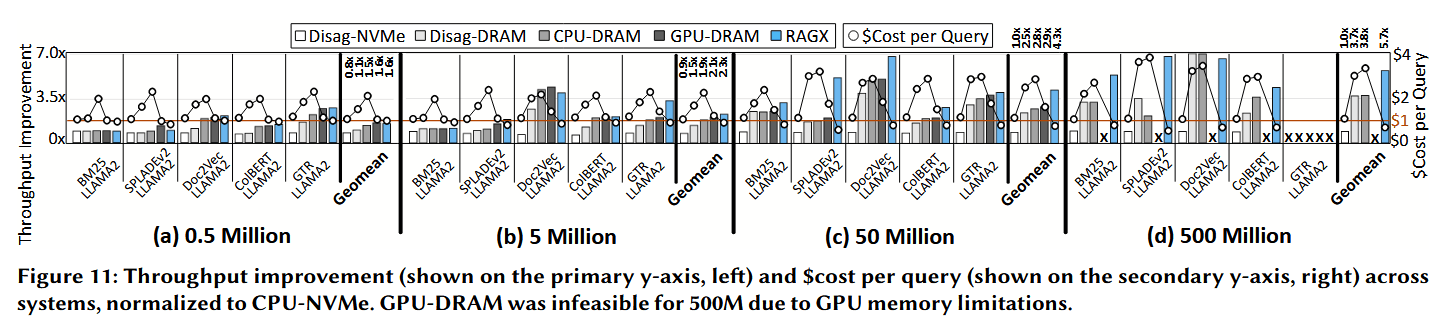
与更多基准系统的对比 (Comparison with additional baselines)。 图 11 展示了以 CPU-NVMe 为基准归一化后,RAGX、CPU-DRAM、Disag-NVMe、Disag-DRAM 和 GPU-DRAM 的吞吐量提升情况。
- 在 50M(5000 万)段落规模下,RAGX 的平均吞吐量分别比 CPU-DRAM、Disag-NVMe 和 Disag-DRAM 提升了 1.5 倍、4.3 倍和 1.7 倍。
- 此外,在 50M 规模下,RAGX 提供了 1.4 倍的加速,而 GPU-DRAM 的单次查询成本则高出 119%。
- 由于 500M 数据集的嵌入向量超出了 A100 GPU 的显存(DRAM)容量,因此无法获得 GPU-DRAM 在该规模下的结果。
- 在 50M 数据集上,RAGX 的性能比 CPU-DRAM 高出 1.5 倍,而 CPU-DRAM 的单次查询成本高出 266%。当规模达到 500M 时,成本差异扩大到 391%,而加速比为 1.6 倍。这些结果进一步证明了使用直连 NVMe (direct-attached NVMe) 存储数据表示(representations)具有显著的成本优势。
成本分析 (Cost analysis)。 遵循前人的研究工作,我们通过累加执行流水线中每个阶段的成本来计算“单次查询成本($cost per query)”。
- 计算方法:每个阶段的成本等于该阶段的运行时间与 AWS 实例租赁成本的乘积(见表 2)。
- RAGX 成本估算:由于 RAGX 目前无法在云平台直接获取,我们使用 AWS ra3.xlplus 实例来估算其成本。该实例提供存储内数据库加速并集成了存储成本,根据先前的研究 ,这可以作为一个有效的替代方案(proxy)。我们忽略了数据传输成本。
- 结果分析:如图 11 所示,RAGX 不仅提供了显著的吞吐量提升,而且在所有评估系统中实现了最低的成本。随着数据集规模从 0.5M 增长到 500M 段落,我们的结果表明,CPU-DRAM 检索的单次查询成本比 RAGX 高出 119% 至 391%。这种成本权衡(cost trade-off)与 §2.4 中讨论的行业和研究趋势相一致。
5.2.2 能效分析
我们使用 Intel 的 RAPL 工具测量 CPU 的功耗,使用 NVIDIA 的 SMI 工具测量 GPU 的功耗;对于 RAGX,我们利用 RTL 综合出的功率结果,并结合 CACTI 模型对片上内存(On-chip Memory)的能耗进行建模。此外,我们采用 1.93 pJ/bit 作为通过 PCIe 进行存储访问的能耗标准,且在计算中未计入网络能耗。我们将每个组件测得的平均功率与其在对应系统配置下的运行时间相乘,从而计算出总能耗。
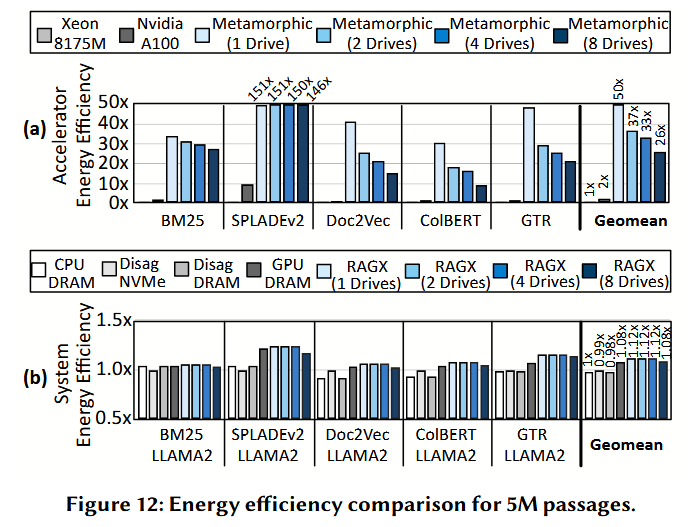
系统与加速器能效 (System and accelerator energy efficiency)。 图 12(b) 展示了在不同配置下(5M 段落规模),归一化为 CPU-NVMe 的系统级 能效对比。
- 搭载单驱动器的 RAGX 比 CPU-NVMe 实现了 1.12 倍的能效提升;相比之下,CPU-DRAM 没有明显的提升,而 GPU-DRAM 则有 1.08 倍的提升。
- RAGX 整体增益有限的主因:在“参考生成”阶段使用的两块 NVIDIA A100 GPU(每块 TDP 达 400 W)占据了绝大部分能耗,掩盖了前端的优化。
然而,若将焦点集中在“搜索与检索”阶段,RAGX 的形态可变加速器展现出了显著的改进,如图 12(a) 所示。 - 该加速器相比 CPU-NVMe 实现了平均 50 倍的能效提升,而 GPU-DRAM 的提升仅为 2 倍。
- SPLADEv2 受益最深,由于 RAGX 同时加速了嵌入生成和评分过程,其能效提升高达 150 倍。
- 值得注意的是,即便在连接 8 个驱动器的情况下,RAGX 依然保持了 26 倍的能效改进。
5.2.3 召回率和端到端准确率
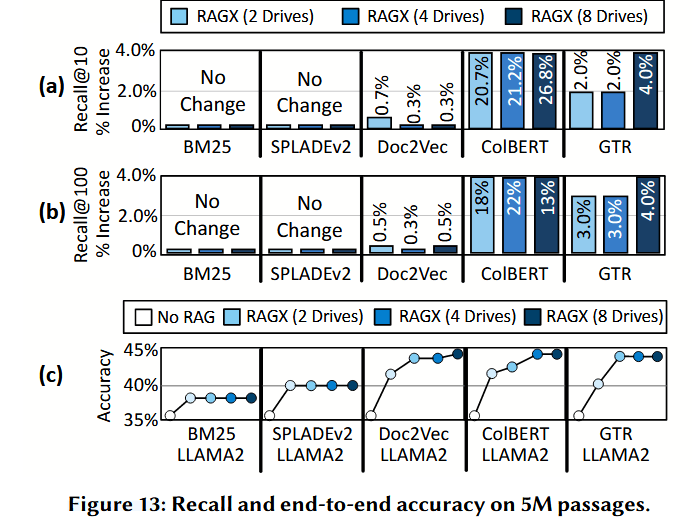
检索质量与 RAG 准确性分析。 图 13(a) 和图 13(b) 分别展示了 RAGX 在配置两个、四个和八个存储驱动器时的 Recall@10(前 10 名召回率)和 Recall@100(前 100 名召回率)。
- 基于关键字的检索器:其召回率保持稳定。这是因为数据表示数据库(representations database)保持不变,只是被复制到各个驱动器上并进行并行查询。
- 基于嵌入的检索器:采用了所提出的数据放置策略(见 §3.2),该策略对嵌入向量进行分区,并为每个驱动器分配一个规模更小、私有的 HNSW 图。尽管索引结构发生了变化,但基于嵌入的检索器并未出现性能退化;在 8 个驱动器配置下,ColBERT 和 GTR 的 Recall@100 分别提升了 13% 和 4%。
- 提升原因:这种改进源于在较小规模图上的局部化计算,以及从多个驱动器汇总候选结果的操作,这在客观上扩大了有效的搜索空间。
图 13(c) 展示了召回率提升对 RAGX 端到端 RAG 准确性(Unigram F1 分数) 的影响。
- 提升原因:这种改进源于在较小规模图上的局部化计算,以及从多个驱动器汇总候选结果的操作,这在客观上扩大了有效的搜索空间。
- 基准准确性与前人研究成果一致。
- 当驱动器数量从 1 个扩展到 8 个时,基于关键字的检索器在准确性上没有变化。
- 基于嵌入的检索器则观察到了 2%–3% 的准确性提升(具体取决于所使用的检索器类型)。
5.2.4 与替代性向量数据库的对比

我们将 RAGX 与一种非图结构的向量数据库——倒排排队文件 (IVF, Inverted Vector File) 进行了对比。
- 技术差异:与依赖贪婪遍历(greedy traversal)的图结构数据库不同,IVF 采用的是一种扁平索引 (Flat Index)。它通过 K-Means 算法对向量空间进行分区,并将每个向量分配给与其最近的质心(centroid)。查询时,系统计算查询向量与所有质心的距离,并仅探测(probe)一小部分聚类,从而以牺牲召回率为代价减少计算量。
- 评估设置:我们将 IVF 的对比限制在基于嵌入的基准测试(ColBERT, Doc2Vec, GTR)中,因为这些测试与其扁平索引结构相契合。为了确保公平性,我们仅使用单个 RAGX 加速器进行对比;然而,考虑到 RAGX 能在多个设备间高效扩展,这是一个保守的基准设定。
- IVF 的两种配置:
- CPU-DRAM:完整的向量索引全部缓存在 DRAM 中。
- CPU-NVMe:向量存储在 NVMe 中,仅质心缓存在 DRAM 中。 按照前人研究 ,我们将聚类数量设置为语料库大小的平方根,且每次查询检索 0.1% 的数据。
实验结果分析: 图 14 展示了以 CPU-NVMe 为基准归一化后的吞吐量情况。
- 随规模增长的优势:随着数据集规模从 0.5M 增长到 500M,RAGX 的性能从领先 CPU-NVMe 20% 扩大到 7.9 倍。这是因为 IVF 在大规模下产生的 I/O 开销不断增加,而 RAGX 通过存储内加速 (In-storage Acceleration) 缓解了这一问题。
- 对比内存系统:即便面对 CPU-DRAM(全内存模式),RAGX 依然实现了 12% 到 51% 的更高吞吐量。这得益于其形态可变加速器能够极其高效地执行相似度搜索任务。
5.2.5 敏感性分析

LLM 推理配置。 图 15 展示了系统及 LLM 设置的变化对运行时间分解(Runtime Breakdown)和吞吐量提升的影响。
- 基准设置:搜索与检索阶段使用 CPU-NVMe,参考生成阶段使用两块 A100 GPU。
- GPU 数量的影响:将 A100 GPU 数量减少到一会使运行时间更多地向“参考生成”阶段偏移,从而将 RAGX 的加速收益从 4.3 倍降低到 3.0 倍。相比之下,使用四块 A100 GPU 或两块 H100 GPU 可分别将提升幅度拉升至 4.3 倍和 4.6 倍。
- 输出长度与软件优化:在配备两块 A100 的机器上,如果输出长度为 512 个 token,收益可能会降至 1.2 倍。然而,通过应用 FlashAttention-2(一种软件优化技术),收益可回升至 1.9 倍。 这些趋势说明,“搜索与检索”在特定配置下确实是性能瓶颈,这与“参考生成总是占据主导地位”的假设相反,且这一结论与先前研究一致。推理阶段的软硬件改进都将有助于放大 RAG 加速及 RAGX 带来的收益。
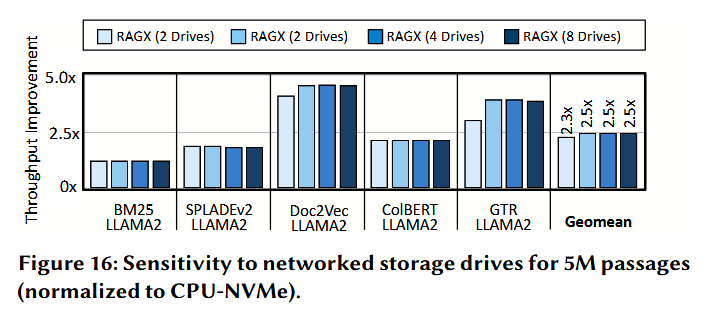
网络存储驱动器。 图 16 展示了 RAGX 在数据表示分布于通过以太网连接的存储驱动器时的性能表现。对于 8 个驱动器的配置,RAGX 保持了 2.5 倍的吞吐量提升,与 PCIe 接口设置下的表现一致。这种稳定性源于 RAGX 消除了存储驱动器之间的通信,并在每个设备上执行独立的计算任务。
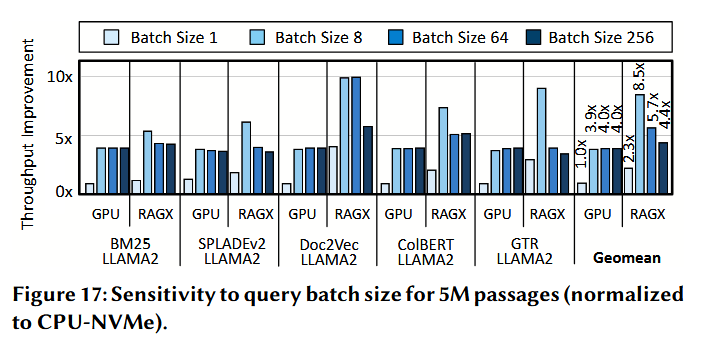
批处理大小 (Batch size)。 RAGX 通过批处理支持并发查询处理。 - 模式切换:在脉动模式 (Systolic mode) 下,批处理按常规方式执行。在向量模式 (Vector mode) 下,向量引擎的列在并发的批处理查询之间进行多路复用。
- 实验对比:图 17 对比了在批处理大小为 8、64 和 256 时,RAGX 与 GPU-DRAM 相对于 CPU-NVMe 的性能表现。
- 加速表现:在小批处理量下,RAGX 实现了 8.5 倍的强劲加速(对比 GPU-NVMe 的 3.9 倍);在大批处理量下,加速比为 4.4 倍(对比 GPU-DRAM 的 4.0 倍)。
- 趋势分析:随着批处理大小的增加,参考生成阶段开始主导运行时间(例如在批处理大小为 256 时占比达 73%),这限制了 RAGX 的收益空间。尽管如此,RAGX 依然通过加速批处理嵌入生成和减少读取数据表示的 NVMe 访问时间来提供性能增益。
6.相关工作
RAG 系统 (Systems for RAG)。 先前关于“搜索与检索”的研究主要集中在:通过算法改进来加速相似度搜索过程、通过并行化提高运行效率,以及近内存计算加速。这些工作都假设所有数据表示(representations)都驻留在 DRAM(内存)中。另一些研究为了解决内存容量限制,通过压缩或选择性地在 DRAM 中存储部分数据,而将完整的数据库存储在硬盘中。然而,由于数据表示仍需从硬盘中提取,这种架构极易产生显著的存储访问开销。对于“参考生成”阶段,先前的工作重点在于通过系统框架、模型并行、量化以及硬件优化来加速大语言模型(LLM)的推理。尽管这些研究加速了 RAG 的单个组件,但却忽视了“搜索与检索”阶段,而存储访问正是该阶段的关键瓶颈。为了全面加速搜索与检索,RAGX 采用了一种存储内加速器(in-storage accelerator),它不仅显著降低了存储访问开销,还能同时执行相似度搜索和针对语言模型的嵌入生成任务。
存储内加速 (In-storage acceleration)。 存储内加速已应用于多个领域,包括基因组学、数据库操作和深度学习。尽管取得了这些进展,但只有极少数研究探索了针对近似最近邻搜索(ANN) 的存储内加速。这些具有启发性的工作大多是针对特定问题的“点解决方案(point solutions)”,使用定制硬件进行图遍历或双调排序(bitonic sorting)。这些方案未能提供一个能够支持多样化(包括基于嵌入和基于关键字)的 RAG 系统、或执行端到端 RAG 流水线的可编程加速器。此外,它们也缺乏对嵌入生成(embedding generation)的支持,而嵌入生成是 RAG 的核心组件——它依赖于 ColBERT(206 MB)或 GTR(419.62 MB)等语言模型将查询映射到与数据库条目相同的表示空间中。RAGX 提出了一种全新的形态可变加速器(metamorphic accelerator),用于数据中心内端到端 RAG 执行的存储内加速;它同时支持基于关键字和基于嵌入的数据表示,并解决了加速语言模型进行查询嵌入的必要需求。
7.结论
检索增强生成 (RAG) 在企业级应用中正日益受到青睐,因为它能够将大语言模型(LLM)与来自数据库的实时信息检索相结合。随着部署方案向持久化存储转型以应对更大规模的数据库,“搜索与检索”阶段(而非 LLM 推理)已成为端到端延迟的主要来源。为了解决这一问题,我们提出了一种形态可变(shape-shifting metamorphic)的存储内架构,它支持多种 RAG 算法、动态数据结构,并在存储内部实现查询嵌入生成。评估结果显示,RAGX 在吞吐量上相比基于 CPU 和 GPU 的检索流水线分别实现了高达 4.3 倍和 1.5 倍的提升。这些结果表明,考虑到企业应用中大语言模型的端到端执行(如 RAG),需要进行跨系统与架构的创新。
参考文献
1.Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In NeurIPS.
2.Nika Mansouri Ghiasi, Jisung Park, Harun Mustafa, Jeremie Kim, Ataberk Olgun, Arvid Gollwitzer, Damla Senol Cali, Can Firtina, Haiyu Mao, Nour Almadhoun Alserr, Rachata Ausavarungnirun, Nandita Vijaykumar, Mohammed Alser, and Onur Mutlu. 2022. GenStore: A High-Performance in-Storage Processing System for Genome Sequence Analysis. In ASPLOS.