论文全称:Flash-Cosmos: In-Flash Bulk Bitwise Operations Using Inherent Computation Capability of NAND Flash Memory
摘要
批量位运算(Bulk bitwise operations),即针对大型向量的位运算,在包括数据库、图处理、基因组分析、密码学和超维计算(hyper-dimensional computing)在内的众多重要应用领域中广泛存在。在传统系统中,批量位运算的性能和能效受到了计算单元(如 CPU 和 GPU)与存储层次结构之间数据迁移(Data movement)的瓶颈限制。闪存内处理(In-flash processing,即在 NAND 闪存芯片内部处理数据)具有加速批量位运算的巨大潜力,因为它能够从根本上减少贯穿整个存储层次结构的数据迁移,尤其是当所处理的数据量超出主存储器容量时。
我们发现了现有的闪存内批量位运算处理技术存在的两个关键局限性:(i) 它未能最大限度地利用 NAND 闪存独特的存储单元阵列结构和工作原理所能提供的位级并行性;(ii) 它是不可靠的,因为它在设计时未考虑到 NAND 闪存高度易错(error-prone)的特性。
我们提出了 Flash-Cosmos(基于单次多操作数感测的闪存计算),这是一种新型的闪存内处理技术,它在提供高可靠性的同时,显著提升了批量位运算的性能和能效。Flash-Cosmos 引入了两个可在现代 NAND 闪存芯片中轻松支持的关键机制:(i) 多字线感测(Multi-Wordline Sensing, MWS) ,其支持通过单次感测操作对大量(数十个)操作数进行批量位运算;(ii) 增强型 SLC 模式编程(Enhanced SLC-mode Programming, ESP) ,其实现了 NAND 闪存内部的可靠计算。我们通过对 160 颗真实的 3D NAND 闪存芯片进行测试,证明了在 Flash-Cosmos 中执行高可靠性批量位运算的可行性。我们的评估结果显示,在三个实际应用场景中,相比于最先进的闪存内处理技术和存储外处理技术,Flash-Cosmos 的平均性能分别提升了 3.5 倍和 32 倍,能效分别提升了 3.3 倍和 95 倍。
引言
许多数据密集型应用依赖于批量位运算(即对大型位向量执行的位运算)。因此,现代计算系统需支持高性能、高能效的批量位运算,这一点至关重要。在数据库与网络搜索领域,已有研究提出了多种技术,通过大量运用批量位运算来加速查询。批量位运算也广泛存在于其他重要应用领域,包括数据库与网络搜索、数据分析、图处理、基因组分析、密码学、集合运算以及高维计算。
在传统系统中,批量位运算的性能与能效会受限于计算单元(如 CPU 或 GPU)与存储层级间的数据迁移。要执行一次批量位运算,传统系统必须先将所有操作数传输至计算单元,最终再将运算结果写回存储层级。由于位运算本身的操作逻辑较为简单,这种数据迁移主导了批量位运算的执行时间与能耗。
在 NAND 闪存芯片内部处理数据(即闪存内处理,IFP),能够从根本上减少制约批量位运算执行效率的数据迁移问题。IFP 是 近数据处理(NDP) 的一种实现形式 —— 近数据处理是一种让计算更贴近数据的计算范式。当处理的数据量较大、无法存入主存时,IFP 通过在底层存储介质(即 NAND 闪存芯片)内部完成计算,仅在需要时将结果传输至主存和 CPU/GPU,大幅减少了整个存储层级间的数据迁移。正如我们在第 3 节中所讨论的:IFP 的性能显著优于存储外处理(ISP) 方案(即利用基于闪存的固态硬盘(SSD)内置加速器的方案),其核心优势在于减少了与 NAND 闪存芯片之间的数据往返迁移。
据我们所知,目前仅有一项近期研究(ParaBit)提出了针对批量位运算的闪存内处理技术,而我们发现 ParaBit 存在两大核心局限:
第一,ParaBit 远未充分挖掘 NAND 闪存的潜力,无法显著提升批量位运算的性能与能效。在数据密集型应用中,批量位运算常涉及两个以上的操作数(例如A⋅B⋅C),而 ParaBit 必须串行执行多次双操作数位运算(例如(A⋅B)⋅C)。这需要连续执行多次高延迟的传感操作,进而成为性能与能效的瓶颈。而在本研究中,我们观察到:NAND 闪存的单元阵列结构与 NAND/NOR 门的数字逻辑电路相似,因此它天然具备单次传感操作即可对大量(如数十个)操作数执行位运算的能力。
第二,ParaBit 仅适用于高容错场景,因为它并未考虑 NAND 闪存高误码的特性。为保障数据可靠性,现代基于 NAND 闪存的固态硬盘(SSD)通常采用(1)纠错码(ECC)和(2)数据随机化技术。但 ParaBit 无法利用这些广泛应用的技术 —— 因为它是直接在存储数据的单元上执行位运算;若用 ParaBit 对经 ECC 编码或随机化处理的数据执行位与、位或运算,会导致 ECC 解码和 / 或去随机化过程中出现错误结果。尽管减少每个单元存储的位数可降低 NAND 闪存的原始位误码率(RBER),但我们对 160 颗真实 3D NAND 闪存芯片的测试表明:“单单元存 1 位” 的低 RBER,仍不足以让 ParaBit 适用于各类广泛的应用场景。
我们的目标是在保障高可靠性(即闪存内位运算结果零误码)的同时,提升批量位运算的性能与能效。为此,我们提出Flash-Cosmos(单传感多操作数闪存计算)—— 一种新型闪存内批量位运算处理技术,通过两种核心思路实现该目标:(1)多字线传感(MWS),支持单次传感操作即可对多个(如数十个)操作数执行闪存内批量位运算;(2)增强型 SLC 模式编程(ESP),可有效实现闪存内批量位运算的零位误码。
MWS 利用 NAND 闪存的两种基础单元阵列结构,实现单次传感操作对大量操作数执行闪存内批量位运算:(1)若干闪存单元(如 24–176 个)串行连接形成 NAND 串(类似数字 NAND 逻辑);(2)数千个 NAND 串连接至同一位线(类似数字 NOR 逻辑)。在这种单元阵列结构下,同时传感多条字线会自动实现:(1)若这些字线位于同一 NAND 串,则结果为所有被传感字线的位与运算;(2)若位于不同 NAND 串,则结果为所有字线的位或运算。
ESP 通过更精准的编程电压控制有效避免了存储数据的原始位误码,闪存单元是通过其阈值电压(Vₜₕ)的电平来存储位数据的:若单元的 Vₜₕ电平偏移至对应其他位值的 Vₜₕ区间,读取时就会产生错误,这源于编程干扰、数据保持丢失、读取干扰、单元间干扰等多种因素;ESP 通过巧妙结合两种现有方案最大化了不同 Vₜₕ区间的间距,首先,在闪存内处理场景中,它采用单级单元(SLC)模式的编程方案,仅在固定 Vₜₕ窗口内划分 “1” 和 “0” 对应的两个 Vₜₕ区间,从而保证了较大的 Vₜₕ间距,其次,ESP 通过(i)更高的编程电压扩大两个 Vₜₕ区间的距离、(ii)更多编程步骤收窄高 Vₜₕ区间的范围,进一步增强了 SLC 模式编程方案;尽管已有不少研究也会优化 NAND 闪存的精准编程以提升可靠性,但我们的目标是实现计算结果的零位误码 —— 并通过结合构成 ESP 的这两种方案,证明在现代 NAND 闪存中这一目标是可以实现的。
在本文中,我们通过两种方式增强了基础 MWS 机制以提升其通用性:首先,我们结合(i)逆传感机制与(ii)内部异或逻辑(这两种功能已在多数 NAND 闪存芯片中得到支持),使 MWS 能够支持位与非 / 或非 / 异或 / 同或运算;其次,我们通过(i)存储每个操作数的逆数据、(ii)利用德摩根定律,放宽了 MWS 机制的数据位置约束(例如,原本仅不同 NAND 串中的字线才能执行位或 / 或非运算),举例而言,若用户存储了 A、B、C 的逆数据(即$\overline{A}$、$\overline{B}$、$\overline{C}$),即便这三者位于同一 NAND 串中,Flash-Cosmos 也可通过对$\overline{A}$、$\overline{B}$、$\overline{C}$执行位与运算来实现三条字线的位或运算,因为(A OR B OR C)=NOT ($\overline{A}$ AND $\overline{B}$ AND $\overline{C}$)
Flash-Cosmos 仅需对NAND闪存芯片的控制逻辑做少量修改,无需改动其单元阵列与传感电路;为实现高效的后制造测试与优化,现代多数 NAND 闪存芯片本就具备(i)同时传感多条字线的能力,以及(ii)以精细粒度调整编程步骤与电压的功能。因此,将 Flash-Cosmos 集成到现有 NAND 闪存芯片中,仅需修改芯片内的指令锁存电路与微控制器固件(见后面设计部分)
背景知识
NAND Flash Memory基础
组织结构
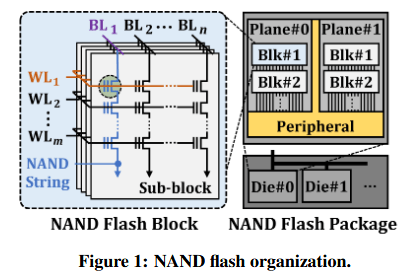
图 1 展示了 3D NAND 闪存的组织方式。若干垂直堆叠的闪存单元(如 24 至 176 个)串行连接,构成一个NAND 串。一个 NAND 串与一条位线(BL)相连,不同位线上的 NAND 串组成一个子块。子块中处于同一垂直位置的所有单元,其控制栅极均连接到同一条字线(WL),这使得这些单元能够并行操作。一个 NAND 闪存块(block)包含若干子块(如 4 个或 8 个),数千个块组成一个平面(plane)。同一平面内的块共享该平面的所有位线,这意味着单条位线会被数千个 NAND 串共用。在本文后续内容中,除非特别说明,我们将子块简称为块。一个 NAND 闪存芯片(或一个裸片Die)包含多个平面(如 2 个或 4 个)。一个 NAND 闪存封装内的多颗芯片可独立运行,但会以时分交织的方式共享封装的指令 / 数据总线(即通道channel)。
编程与擦除操作
闪存单元通过其阈值电压(Vₜₕ)电平存储数据,而该电平高度依赖单元电荷陷阱中的电荷量。编程操作会向单元中注入电子,从而提升单元的 Vₜₕ电平。由于多条闪存单元连接至同一条字线(WL),NAND 闪存以页page(如 16 KiB)为粒度写入数据,字线上的每个单元存储页中的 1 位数据。为降低已编程单元的 Vₜₕ电平,NAND 闪存会执行擦除操作 —— 将电子从单元中抽出。擦除操作的粒度是块block,这使得擦除延迟 tₑᵣₐₛₑ(如 3–5 ms)远长于编程延迟 tₚᵣₒ₉(如 200–700 μs)
读操作
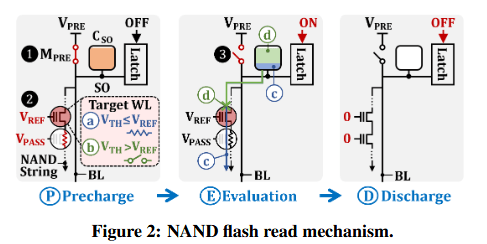
NAND 闪存通过感测相应 NAND 串的导通性(conductance)来确定单元的VTH电平(即单元的位数据)。图 2 展示了 NAND 闪存的读取机制,它由三个步骤组成:(i) 预充(precharge) 、(ii) 评估(evaluation) 以及 (iii) 放电(discharge)。
在预充阶段(P,见图 2 左侧) ,NAND 闪存芯片通过开启预充晶体管 MPRE ①,将所有目标位线(BL)及其感测输出(SO)电容(CSO)充电至预充电压VPRE。同时,芯片向目标字线(WL)施加读取参考电压VREF,并向同一块内的其他非目标字线施加更大的通过电压 VPASS ②。这样做使得每个目标单元的 VTH电平决定了相应 NAND 串的导通性:如果 VTH≤VREF(图 2 左侧的 ⓐ ),目标单元将起到电阻的作用;如果VTH>VREF(ⓑ ),目标单元则相当于一个断开的开关。由于 VPASS足够高(>6 V),足以开启任何闪存单元,无论其 VTH电平如何,因此同一 NAND 串中的所有非目标单元都将起到电阻的作用。
随后,芯片通过断开位线与 VPRE的连接 ③ 并启用锁存电路 ④,开始对目标单元进行评估阶段(E,见图 2 中间部分) 。如果目标单元的 VTH电平低于VREF,则 CSO中的电荷会迅速流过 NAND 串(ⓒ ),这被感测为“1”。如果 VTH>VREF,CSO的电容(电荷)几乎不发生变化(ⓓ ),因为目标单元阻断了位线的放电电流,这被感测为“0”。
最后,芯片对位线进行放电阶段(D,见图 2 右侧部分) ,使 NAND 串恢复到其初始稳定状态(即预充发生前的状态),以便进行后续操作。
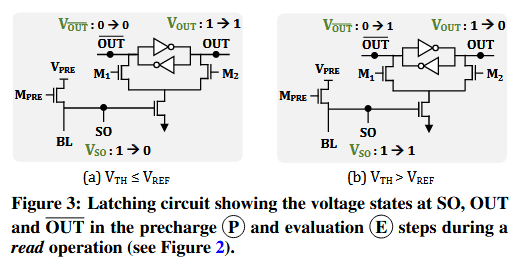
图 3 描绘了 NAND 闪存如何利用其锁存电路(latching circuit)感测位线(BL)的导通性。图 3(a) 和 3(b) 分别描述了当闪存单元的阈值电压VTH低于和高于读取参考电压 VREF时,锁存电路的操作情况。我们展示了从预充步骤(图 2 中的 P)进入评估步骤(图 2 中的 E)时,三个节点(SO/OUT/$\overline{OUT}$)中每一个的电压状态转变。
在预充期间,NAND 闪存芯片为位线充电,使 VSO=1。在评估步骤之前,芯片通过仅激活晶体管 M1来初始化锁存电路,导致 V$\overline{OUT}$=0,从而使 VOUT=1。评估步骤会禁用 MPRE和 M1,同时启用 M2。在图 3(a) 中,由于 VTH≤VREF,CSO中的电荷迅速流过 NAND 串,评估步骤使 VSO=0,从而导致 VOUT=1(图 2 中的 E)。由于 CSO的电荷保持能力较低 ,闪存单元的位值会立即存储在锁存电路中。在图 3(b) 中,当VTH>VREF 时,闪存单元充当断开的开关,评估步骤导致VSO=1且VOUT=0。
反向读取
现代 NAND 闪存芯片通常支持反向读取模式,用于读取存储数据的反向(即逻辑非)结果。支持反向读取不需要对图3所示的锁存电路进行任何硬件改动。我们用 ISO、IOUT 和 I$\overline{OUT}$ 来表示反向读取操作期间三个节点(SO/OUT/$\overline{OUT}$)的电压状态。芯片通过简单地改变 M1和M2的激活顺序来执行反向读取。与普通读取操作不同,反向读取在评估步骤之前先激活M2来初始化锁存电路。这导致 IOUT=0,从而使 I$\overline{OUT}$=1。在评估步骤期间,M1被激活,而 MPRE和M2被禁用。这使得评估步骤后存储在锁存电路中的值成为普通读取模式下所存值的反向。
NAND闪存的可靠性
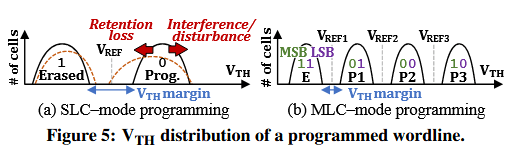
现代 NAND 闪存由于各种错误源 而非常容易出错,例如编程干扰(program interference)、数据保持损耗(data retention loss)、读取打扰(read disturbance)以及单元间干扰(cell-to-cell interference)。图 5 展示了字线(WL)分别在 (a) 单层单元(SLC)模式和 (b) 多层单元(MLC)模式下编程(分别存储每单元 1 位和 2 位数据)时的VTH分布情况。对某条字线进行读取或编程操作会增加其他单元的VTH电平,从而影响同一块(block)内其他字线的VTH分布(即如图 5(a) 所示的干扰和打扰)。闪存单元还会随着时间的推移发生电荷泄漏,导致其VTH电平降低(即如图 5(a) 所示的保持损耗)。如果单元的VTH电平移动超出了读取参考电压 VREFVREF(即进入了对应不同数值的VTH范围),感测该单元时就会得到与原始存储数据不同的值,从而引入位错误(bit error)。
有两个主要因素会显著增加 NAND 闪存的原始(即纠错前)位错误率(RBER)。第一,随着编程和擦除(P/E)周期次数的增加,闪存单元更容易出错。这是因为编程和擦除操作中使用的高电压会损坏单元,使其电荷更容易发生泄漏。第二,每个单元存储的位数越多,RBER 越高。这是因为为了在同一电压窗口内装入更多的阈值电压(VTH)状态,必须缩小相邻VTH范围之间的裕量(margin),如图 5(b) 所示。
纠错码(ECC) :为了确保所存储数据的完整性,现代 SSD 通常采用 ECC。ECC 通过存储冗余信息来检测并纠正位错误。为了应对现代 NAND 闪存极高的 RBER,必须使用复杂的纠错码(例如低密度奇偶校验 (LDPC) 码),这会增加 ECC 引擎的性能开销和面积开销。
数据随机化(Data Randomization) :在现代 SSD 中,通常会对存储的数据值进行随机化处理,以降低出现“最坏情况数据模式”的概率,因为这些模式会加剧编程打扰(program disturbance)。例如,当一个NAND串中有许多连续的擦除单元时,对同一NAND串的下一个单元进行编程会显著提高那些连续单元的VTH电平,从而可能引入位错误。数据随机化通过在 NAND 串上随机分布VTH状态(无论原始存储值为何),将此类情况发生的概率降至极低。在读取操作期间,存储的数据会进行去随机化处理,以正确读出随机化之前的原始存储值。
动机
闪存内批量位操作
许多先前的研究针对大批量位操作(bulk bitwise operations)探索了近数据处理(NDP)解决方案,主要基于两个原因。首先,大批量位操作被广泛应用于各种重要应用中。其次 ,大批量位操作可以显著受益于 NDP。由于位操作本身的简单特性,在传统系统中,批量位操作的性能和能效瓶颈在于计算单元与存储层次结构之间的数据移动。NDP 通过在存储设备附近或内部以极高的并发水平支持简单的批量位操作,从而能以较低成本有效缓解此类数据移动。
在众多现有的 NDP 解决方案中,只有近期的一项工作 ParaBit 提出了一种在 NAND 闪存芯片内部执行大批量位操作的闪存内处理(in-flash processing)技术。ParaBit 利用了现代 NAND 闪存芯片中普遍采用的锁存电路 (见后续)。现有的 NAND 闪存芯片支持一种名为“缓存读取(cache read)”的命令,其目的是通过在感测后续读取操作的同时,并行地将数据从NAND闪存芯片传输到闪存控制器,从而提高读取操作的性能。为了实现缓存读取,现有芯片除了感测锁存器(sensing latch)外,还包含一个缓存锁存器(cache latch)。我们将描述该缓存锁存器的操作与实现,因为它对 ParaBit 至关重要且被其采用。
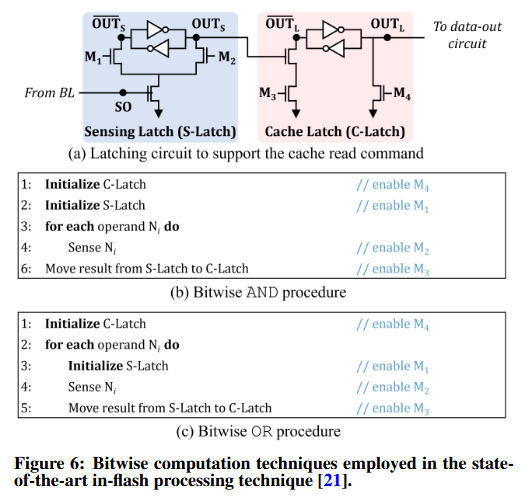
图 6(a) 展示了现代 NAND 闪存芯片中常见的锁存电路,除了图 3 中描述的感测锁存器(左侧部分)外,该电路还配备了一个缓存锁存器(cache latch,右侧部分)。在预充步骤中,NAND 闪存芯片通过激活M4来初始化缓存锁存器,这会拉低 OUTL节点,从而使 $\overline{OUTL}$=1。在开启M3之前,感测锁存器(即 OUTS节点处的值)无法影响缓存锁存器中存储的数据。这一特性使得芯片能够在将缓存锁存器中先前读取的数据传输至闪存控制器的同时,读取新数据(进入感测锁存器)。
图 6(b) 和 6(c) 分别描述了 ParaBit 如何通过智能地控制图 6(a) 所示的锁存电路,来执行闪存内(in-flash)位与(AND)和位或(OR)操作。
ParaBit 中的位与(Bitwise AND)操作:为执行位与操作,ParaBit 会在既不开启M3也不重新初始化感测锁存器(sensing latch)的情况下,串行读取共享同一条位线的操作数(图 6(b) 中的第 3 行和第 4 行)。这样做可以使 ParaBit 将串行读取操作数的位与结果保留在感测锁存器(OUTS节点)中。如果读取的存储单元存储的是“0”(即 SO 节点的值为“1”),那么仅开启M2就会导致 OUTS=0,无论OUTS节点的当前值为何。而当存储单元存储的是“1”(即 SO=0)时,感测该单元并不会改变OUTS节点的值。
换句话说,感测新数据N仅在N和OUTS 节点的当前值均为“1”时,才会使 OUTS=1;这等同于执行了 OUTS=(N AND OUTS)。在串行读取了共享同一条位线的所有操作数(其结果是所有操作数的位与结果都保留在OUTS节点)之后,ParaBit 开启M3,将结果从感测锁存器移动到缓存锁存器(第 5 行)。
ParaBit 中的位或(Bitwise OR)操作:为执行位或操作,ParaBit 同样会串行读取共享同一条位线的操作数(图 6(c) 中的第 2 至 5 行),这与位与(AND)操作类似。但在感测每次读取之前,它都会重新初始化感测锁存器(第 3 行),并在感测完每个操作数后激活 M3(第 5 行,即将结果从感测锁存器移动到缓存锁存器)。这样做可以将共享同一条位线的已读操作数的位或结果保留在缓存锁存器(节点 OUTL)中。
如果感测锁存器中新读取的数据 N(即 OUTS=N)为“1”,那么开启M3会导致 OUTL=1,无论节点 OUTL的当前值为何。而当 N=OUTS=“0”时,激活M3不会改变节点OUTL的值。因此,将新数据N锁存至缓存锁存器时,只有当新数据N与OUTL的当前值均为“0”时,才会导致 OUTL=0,这等同于执行了OUTL=(N OR OUTL)。
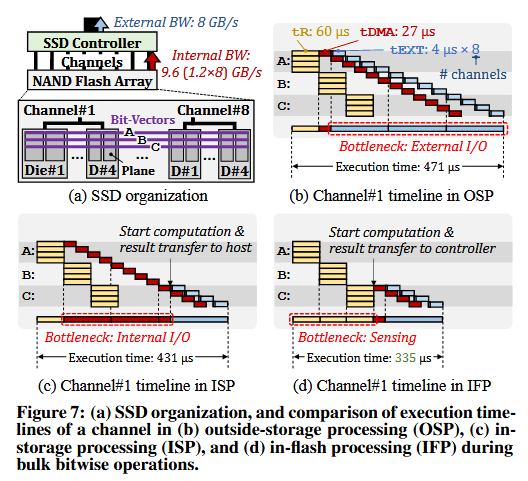
闪存内处理(In-Flash Processing)的优势。 图 7 展示了一个示例,说明类 ParaBit 的闪存内处理(IFP)如何比传统的存储外处理(OSP)和存储内处理(ISP)更具优势;其中 OSP 和 ISP 分别使用主机 CPU/GPU 及 SSD 内部的计算单元来处理数据。图 7(a) 描绘了本示例中所考虑的目标 SSD。该 SSD 拥有 8 条通道,每条通道由 4 个双面晶粒(2-plane dies)共享(即总共 64 个 plane),页大小为 16-KiB。我们假设页面读取延迟(tR)为 60 µs,通道与 SSD 控制器之间的通道带宽为 1.2 GB/s ,主机与 SSD 之间的外部 I/O 带宽为 8 GB/s(4 通道 PCIe Gen4)。图 7(b)、7(c) 和 7(d) 分别显示了当应用程序使用 OSP、ISP 或 IFP 对三个1-MiB(2个plane×16-KiB页×8通道×1个通道4个Die)的位向量 A、B 和 C 执行大批量位或(OR)操作(即 A OR B OR C)时,某条通道的执行时间线。我们假设每个位向量都分布在图 7(a) 所示的 SSD 所有 64 个 plane 上。
图 7(b) 展示了 OSP(存储外处理)模式下八个通道之一执行大批量位运算的时间线。为了在 OSP 模式下获得最高性能,主机必须针对每个操作数在各 NAND 闪存晶粒(die)上执行并发的多面(multi-plane)读取。操作数本身是按序读取的(如图 7(b) 中操作数 A、B和 C 的tR过程)。一旦某个操作数被读入感测锁存器,它可以被传输至 SSD 控制器(tDMA),继而传输至主机(tEXT),与此同时,下一个操作数的读取工作也在同步进行。根据闪存通道和外部 I/O 带宽,每个晶粒将 32-KiB 数据(2 面 × 16-KiB 页)传输至 SSD控制器需tDMA=27µs,传输至主机需 tEXT=4µs,尽管单晶粒的tEXT低于tR和tDMA,但主机与 SSD 之间的数据传输(图 7(b) 中称为“外部 I/O”)仍构成了性能瓶颈,因为 SSD 必须通过外部 I/O 接口串行传输来自所有八个通道的位向量,以供主机 CPU 进行计算。
图 7(c) 展示了 ISP(存储内处理)方法下某条通道的执行时间线。ISP 可以利用每通道加速器,通过在 SSD 控制器中执行计算并仅将计算结果传输给主机系统,从而减少外部数据迁移。然而,SSD 控制器与 NAND 闪存晶粒之间的 SSD 内部数据迁移(在图 7(c) 中称为内部 I/O)成了 ISP 新的性能和能耗瓶颈。这是因为内部数据迁移必须通过由各 NAND 闪存晶粒所共享的通道进行串行传输,而连接到该通道的各晶粒本可以并发地执行页面读取。
图 7(d) 展示了最先进的 IFP(闪存内处理)方法 ParaBit 的通道执行时间线。ParaBit 通过在 NAND 闪存芯片内读取操作数的同时执行计算,并且仅将计算结果传输给 SSD 控制器和主机,从而有效地减少了内部和外部数据迁移,进而显著提高了性能和能效。在最先进的 IFP 中,SSD 控制器与 NAND 闪存晶粒(die)之间的内部数据迁移不再是瓶颈,但正如图 7(d) 所示,数据感测过程成为了新的瓶颈。
ParaBit局限性
我们确立了 ParaBit 的两个关键局限性。ParaBit 是目前用于大批量位运算(bulk bitwise operations)的最先进闪存内处理(IFP)技术。
IFP 能力中未被挖掘的潜力。 尽管 ParaBit 相比其他处理方法具有优势,但我们发现它仍未充分挖掘 IFP 在显著提升大批量位运算性能和能效方面的巨大潜力。正如第 3.1 节所述,ParaBit 会从位线上串行读取每个操作数(如图 7(d) 中的tR过程所示)。在 ParaBit中,每次读取操作数都需要进行一次代价高昂(即缓慢)的感测操作。当需要在两个以上的操作数之间执行运算时,这种对每个操作数的串行读取就成了严重的瓶颈。
我们发现,由于 (i) 其独特的单元阵列(cell-array)结构和 (ii) 闪存单元的工作原理,NAND 闪存具有固有的能力,可以一次性(即仅通过单次感测操作)对大量操作数(如数十个)执行大批量位运算。首先,正如第 2.1 节所述,在 NAND 闪存中,数十个甚至一百多个闪存单元被串联在一起(类似于数字与非门),而数千个 NAND 串(string)连接到同一条位线 BL(类似于数字或非门)。其次,闪存单元在结构和工作原理上类似于数字逻辑门的基本组件——普通 MOS 晶体管。这些观察促使我们开发了一种全新的 IFP 技术(详见第 4 节),它解决了现有技术的感测瓶颈:我们的新技术仅需单次感测操作即可在多个操作数上执行大批量位运算。
适用性受限。 ParaBit 的适用性仅限于高度容错的应用,因为它在设计上未考虑 NAND 闪存极易出错的特性。正如第 2.2 节所述,鉴于 NAND 闪存的易错性,使用纠错码(ECC)和数据随机化对于确保存储数据的可靠性至关重要。然而,由于 ParaBit 在读取操作数的同时执行大批量位运算,它无法利用任何当前广泛使用的 ECC 和随机化技术。在经过 ECC 编码或随机化的数据上进行按位与(AND)或按位或(OR)运算,极易导致 ECC 解码或去随机化过程产生错误结果。尽管与先进的 MLC 技术(如 TLC 或 QLC 技术)相比,减少单单元存储位数可以降低 RBER,但 ParaBit 只有在应用能够容忍 NAND 闪存芯片 RBER(纠错前错误率)的情况下才能使用
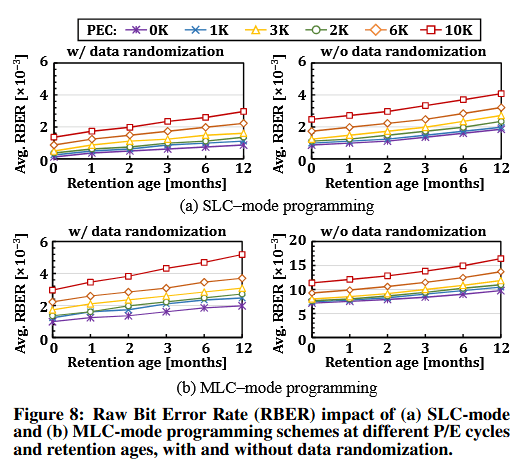
为了更好地理解 NAND 闪存可靠性对 IFP(闪存内处理)适用性的影响,我们使用 160 个 TLC NAND 闪存芯片进行了实机表征。图 8 展示了针对所分析的 160 个 NAND 芯片中随机选取的 3,686,400 条字线(WL)的平均 RBER(原始比特错误率)。在不同的 P/E 周期次数(PEC)和留存期(retention ages)下,我们测量了每个 WL 在以下情况下的 RBER(未应用纠错码 ECC):(i) 分别以 (a) SLC 模式和 (b) MLC 模式编程时;以及 (ii) 开启(左图)和关闭(右图)数据随机化时。
我们得出了三个关键观察结论。第一,即使使用带数据随机化的 SLC 模式编程(图 8(a) 左图),其平均 RBER 仍显著高于 SSD 的不可纠正比特错误率(UBER)要求(例如 <10−15至10−16),高出约 12 个数量级。第二,禁用数据随机化(图 8(a) 和 8(b) 的右图)会使 SLC 模式和 MLC 模式下存储数据的 RBER 分别显著增加 1.91 倍和 4.92 倍。第三,正如预期的那样,使用 MLC 模式编程(图 8(b) 中的图表)会显著降低存储数据的可靠性,导致 RBER 高达 SLC 模式编程的 4 倍。
我们在本项工作中的目标是开发一种新型的闪存内处理技术,该技术能够:(i) 通过充分挖掘 NAND 闪存固有的计算能力,实现仅需单次感测操作的多操作数计算,从而最大限度地提高性能和能效;以及 (ii) 提供高数据可靠性(即计算结果实现零比特错误),使其能够适用于广泛的非容错(error-intolerant)应用。
Flash-Cosmos关键机制
多字线感知(MWS)
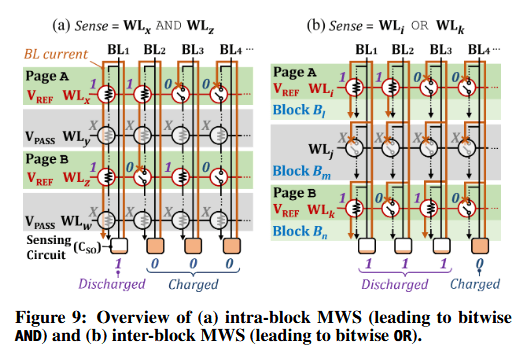
核心思想。 MWS 基于我们的关键发现:在 NAND 闪存中同时读取多条字线(WL)会产生这些 WL 的按位与(AND)或按位或(OR)运算结果。图 9 展示了 MWS 如何使 NAND 闪存芯片仅需一次感测操作即可对两个操作数执行大批量 (a) 按位与和 (b) 按位或运算。虽然图 9 仅展示了对两个操作数的大批量位运算,但 Flash-Cosmos 可以支持针对数十个操作数的多操作数大批量位运算。
对于按位与(AND) ,NAND 闪存芯片同时对同一个块(block)内包含大批量位运算源操作数的多条目标 WL(如图 9(a) 中的WLx和WLz)施加VREF,我们称之为块内 MWS (intra-block MWS) 。如果芯片像常规读取一样对所有非目标 WL(如WLy 和WLw)施加 VPASS,则仅当相应 NAND 串(string)中的所有目标单元都处于擦除状态(即 VTH<VREF)时,位线(BL)才会被感测为放电。换句话说,感测电路只有在所有目标单元都存储“1”时(图 9(a) 中的BL1)才将 BL 读作“1”;而如果任何一个目标单元存储“0”(图 9(a) 中的 BL2,BL3,BL4),则读作“0”,这等同于按位与运算。通过对两条以上的字线施加 VREF,块内 MWS 运算可以很容易地扩展到两个以上的操作数,从而仅需单次感测操作即可计算所有这些字线的按位与结果。
对于按位或(OR) ,我们引入了块间 MWS (inter-block MWS) ,即芯片同时对不同块的多条 WL(如图 9(b) 中的WLi和WLk)施加 VREF,同时对这些块中的所有非目标 WL 施加 VPASS。这样做会导致只要相应NAND串中至少有一个目标单元处于擦除状态,BL 就会放电。换句话说,感测电路只有在各 BL 对应的所有目标单元都存储“0”时(图 9(b) 中的 BL4)才将 BL 读作“0”;而如果任何一个目标单元存储“1”(图 9(b) 中的BL1,BL2,BL3),则读作“1”,这等同于按位或运算。通过对多条字线(每条位于不同的块)施加 VREF,块间 MWS 运算可以很容易地扩展到两个以上的操作数,从而仅需单次感测操作即可完成跨不同块的所有这些字线的按位或运算。
正如上文所述,两种类型的MWS都能仅通过单次感测操作执行针对两个以上操作数的大批量位运算。这一特性使得MWS在两个方面比先前利用多字线(或多行)激活进行存内计算的NDP(近数据处理)提议更强大。首先,虽然先前的研究也曾提议通过激活多条字线在各种存储设备内部执行大批量位运算,但能同时计算的源操作数数量有限(通常仅限于两个),因此像 ParaBit 一样需要对更多操作数进行顺序感测。其次,尽管存在一些利用多字线激活在 NAND 闪存内执行累加计算(如乘加运算)的提议,但它们依赖于模拟电流感测,这需要对常规闪存芯片进行重大修改(例如,在基于忆阻器的多十字交叉阵列系统中,为每个阵列添加精确的模数转换器 (ADC) 成本极高;即使每个ADC由128个输出列共享,其功耗仍占芯片总功耗的 58%,面积占芯片总面积的 31%)。
块内和块间 MWS 可以结合使用来执行复杂的按位与(AND)和按位或(OR)组合运算。假设图 9(b) 中的块Bl和Bn分别拥有N个页面(WL),每个页面分别存储位向量Ai和Bi (1≤i≤N)。如果我们同时对这两个块中的所有WL施加VREF,那么当且仅当Bl或Bn中至少有一个块的NAND串内所有单元都存储为“1”时,芯片才会将位线BLj读作“1”,这等同于:
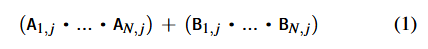
可行性与开销。 将 MWS 应用于商用 NAND 闪存芯片具有高度的可行性,且成本低廉。事实上,现有的芯片为了其他目的已经使用或支持块间和块内 MWS。例如,在擦除一个块后,NAND闪存芯片需要通过对所有单元同时施加VREF来检查该块中的所有单元是否已被完全擦除(称为“擦除校验”),即芯片对块内的所有字线(WL)执行块内 MWS。此外,制造商通常在芯片设计中支持激活多条 WL(即块内 MWS)和多个块(即块间 MWS),以便执行对芯片快速测试至关重要的多页读/写和多块擦除操作。
MWS 方案有两个潜在的缺点。第一,与常规页读取相比,块间MWS会消耗更多功耗,因为它需要激活更多块,而这需要对多个块中的所有WL进行充电。值得注意的是,块内 MWS 操作的功耗实际上比常规读取更低,因为它对额外的目标WL施加的是VREF,而在常规读取中,会对这些字线施加VPASS(其电压通常比VREF高出数倍)。第二,可靠的 MWS操作延迟可能长于默认读取延迟tR,因为MWS操作的目标数据是使用ESP方案(详见后续)且在未进行随机化处理的情况下编程的。与经过随机化的情形(其中约 50% 的单元始终处于擦除状态)相比,未经随机化的NAND串可能具有较低的电阻(例如,当所有单元均处于擦除状态时),为了确保操作的可靠性,这可能会增加预充电延迟和评估延迟。我们将在后续对这些缺点进行评估。
增强型SLC模式编程(ESP)
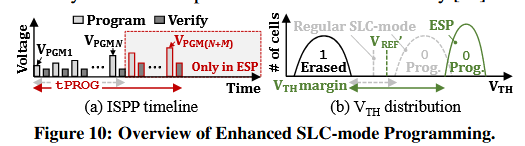
核心思想。 ESP 通过最大化两种阈值电压(VTH)状态之间的裕量(margin)来增强现有的 SLC 模式编程。图 10 展示了与常规 SLC 模式编程相比,ESP 如何提高可靠性。NAND 闪存通常采用增量步进脉冲编程(ISPP)方案,以精确控制NAND闪存单元的VTH,并收窄VTH状态分布的宽度。如图 10(a) 所示,ISPP方案以一定的步进电压(ΔVISPP)从VPGM1开始逐渐增加编程电压(注意编程电压不是Vth),直到字线(WL)中每个单元的VTH电平均达到其目标电压VTGT。在每个 ISPP 步进结束时,芯片会检查每个单元的VTH电平是否已达到其VTGT(即图 10(a) 中的校验/Verify),并在下一 ISPP 步进中排除这些已达标单元。
ESP的核心思想是在执行常规SLC模式编程之后,执行额外的ISPP步进,并使用:(i) 增加的 VTGT值(针对每个单元),将已编程的VTH状态进一步推向更高电压水平;以及 (ii) 减小的ΔVISPP值,以收窄已编程VTH状态分布的宽度。如图 10(b) 所示,这样做显著增加了新的读取参考电压(VREF′)与擦除态及编程态VTH状态之间的裕量,从而使单元不易受 NAND闪存中存在的多种错误源的影响。
可行性与开销。由于以下两个原因,将ESP应用于商用NAND闪存芯片具有极高的可行性且成本较低。首先,现代 MLC NAND 闪存通常出于多种原因支持 SLC 模式编程,例如:存储对可靠性敏感的数据、管理 SLC 写入缓存,或者在某些单元无法用于MLC模式时将其用于数据存储 。其次,商用NAND闪存芯片可以使用 SET FEATURE 命令来调节ISPP参数,这对于 NAND 闪存芯片的制造后优化至关重要。SET FEATURE 命令还被用于根据 P/E 周期(编程/擦除周期)的变化以及NAND闪存单元的可靠性特性进行动态调整。
ESP 有两个缺点。第一,它通过执行额外的ISPP步进增加了编程延迟。第二,因为其采用了 SLC 模式编程,与 MLC 模式编程相比,存储相同容量的数据需要消耗两倍的字线(WL)。我们将在后续对ESP的性能和容量开销进行详细分析。
真实设备特性表征
本节介绍了我们对 160 颗真实 3D NAND 闪存芯片进行的特性表征,旨在验证 Flash-Cosmos 两个核心机制的可行性、性能和可靠性。
特性表征方法论
基础设施。我们使用了一个基于FPGA的测试平台,其中包含定制的NAND闪存控制器和温度控制器。该闪存控制器支持我们NAND闪存芯片中实现的所有命令,不仅包括基本的读取/编程/擦除命令,还包括各种测试模式命令,这些命令对于动态更改操作参数(例如 ISPP 步进电压和其他时序参数)以及同时激活多个字线(WL)至关重要。温度控制器将 NAND 闪存芯片的温度维持在目标温度的 ±1°C 以内。这一功能使我们能够 (i) 在相同的操作温度(85°C)下测试所有芯片,以及 (ii) 基于阿伦尼乌斯定律加速电荷保持力损耗(retention loss),这对于在保持合理测试时间的前提下,表征长保持期(如 1 年)下的真实设备特性至关重要。我们对160颗48层3DTLC NAND闪存芯片进行了特性表征,其中每个NAND串包含 48 个闪存单元,页大小为 16 KiB。在常规 SLC 模式编程下,芯片的读取延迟 tR 为 22.5 μs,编程延迟 tPROG 为 200 μs。
方法论。为了尽量减少特性表征结果中潜在的不准确性,我们严格按照 JEDEC 标准设计了实验,这些标准规定了评估商业级 NAND 闪存产品可靠性所推荐的测试方法。为了确保高置信度的可靠性测试,JEDEC 建议测试来自三个不同晶圆的 39 颗以上闪存芯片。我们的 160 颗闪存芯片由五个不同的晶圆制造而成,我们从这 160 颗芯片的随机位置分别选取了 120 个block(而非sub block)。我们测试了每个选中block中的每一页(共计 3,686,400 条字线),以获得具有统计学意义的结果。
为了评估 Flash-Cosmos 在最坏操作条件下的可靠性,我们测量了在 30°C 下经历 1 年数据保持时间以及 10K 次 P/E 周期后,每条字线(WL)的 RBER。我们通过重复执行对block内每一页进行编程(TLC 模式)并擦除整个block的循环,来增加block的 P/E 周期数。除非另有说明,我们使用“棋盘格”(checkered)数据模式对每一页进行编程,这是 NAND 闪存可靠性测试中的最坏情况数据模式,即任何两个相邻单元(无论是水平还是垂直方向)都被编程为最高VTH状态(例如 TLC 模式下的 P7 状态)或最低VTH状态(即擦除状态)。
特性表征结果

ESP 延迟与可靠性。我们首先研究了 ESP 方案在可靠性与编程延迟之间的折衷。图 11 展示了当我们为了实现更精确的ISPP控制而增加 ESP 延迟tESP并对字线(WL)进行编程时,每 1-KiB 数据的平均 RBER。我们绘制了所有测试block中表现最差、中等和最佳block的 RBER,并将增加后的tESP值相对于常规SLC模式编程的默认编程延迟tPROG进行了归一化。
我们从图 11 中得到了两个关键观察。首先,通过增强 SLC 模式编程,可以在不使用数据随机化的条件下避免原始比特错误,其代价是编程延迟的增加。当我们将tESP增加到比tPROG高 90% 以上时,在总共包含超$4.83×10^{11}$比特的测试页中,我们观察到了零比特错误(zero bit errors) ,其次,ESP方案的可靠性提升随tESP的延伸而显著增强。对于中位数block,将tESP增加60%即可实现一个数量级的 RBER 降低。我们得出结论,ESP 方案对于在闪存计算结果中实现有效的零比特错误至关重要,因此 ESP 能够将闪存内计算(in-flash processing)的适用性扩展到更广泛的应用领域。
MWS 延迟与可靠性。我们测量了 tMWS,即在所有测试block中实现零比特错误所需的 MWS操作最小延迟。首先,我们执行块内 MWS 操作,同时将读取字线(WL)的数量从 1 更改为 48(即一个 NAND 串中的字线数量)。其次,我们对目标block中的所有字线执行块间MWS 操作,同时将激活的(目标)block数量从 1 更改为 32。在这两个实验中,我们首先使用棋盘格数据模式增加目标block的 P/E 周期数。接着,我们检查在由使用不同数据模式对block进行编程所引起的高干扰和噪声下,块内 MWS 的正确性。这种新数据模式通过对block进行编程以满足两个条件,从而最大化block中 NAND 串的电阻:(i) 存储比特值“1”的单元(即“1”单元)的数量必须少于两个;(ii) 如果一个 NAND 串包含一个“1”单元,则该单元必须处于 MWS 操作的目标字线之一上。我们通过将从真实芯片中获得的 MWS 操作结果与存储数据上位运算的正确结果进行比较,验证了 MWS 的正确性。
图 12 和图 13 分别展示了块内和块间MWS操作的tMWS值(以tR的倍数表示)。我们从结果中得出了三个关键观察。
第一,绕过数据随机化不会增加常规读取操作的延迟。如图 12 所示,当我们在一个block中仅读取单条字线(WL)时,使用默认读取延迟不会引入错误。第二,块内MWS不会显著增加读取延迟。即使我们同时读取一个block中的所有 48 条字线,tMWS 也仅比tR高 3.3%。当我们对8 条(或更少)字线执行块内MWS 时,tMWS 比 tRtR 高出不到 1%。第三,尽管与块内 MWS 相比,块间 MWS(如图 13 所示)对 tMWS 的影响更为显著,但与对相同字线进行单独读取相比,它仍然具有显著优势。如图 13 所示,当同时读取 32 个不同block中的字线时,tMWS 比 tRtR 高出 36.3%。这是因为同时激活多个block会显著增加需要同时预充的字线数量。在激活 8 个block之前,增加的字线预充时间大部分被位线(BL)预充时间所掩盖;但随着激活block数量的进一步增加,字线预充时间会变得比位线预充时间更长,从而导致可靠的 MWS 操作延迟长于常规页读取的延迟。然而,对 32 条字线执行 MWS 增加后的延迟(1.363×tR)仍远低于单独(串行)读取 32 条字线的延迟(32×tR)。
基于我们的观察,我们得出了三个主要结论。首先,我们证明了真实的商用 NAND 闪存芯片可以可靠地支持块内和块间 MWS 操作,因此,只要计算机架构师能够访问用于我们特性表征的命令接口,就可以构建利用 Flash-Cosmos 的系统。其次,两种类型的 MWS 都能以较低成本显著加速商用 NAND 闪存芯片中的闪存内大批量位运算(bulk bitwise operations)。第三,支持两种类型的 MWS 仅需在默认读取延迟的基础上增加极小的延迟。如果我们将块间 MWS 同时激活的block最大数量限制为 4,我们就可以支持任何 MWS 操作,且其固定延迟(tMWS)仅比 tRtR 高出 3.3%。
块间 MWS 的最大功耗。由于同时激活的字线(WL)数量更多,块间 MWS 相比常规页读取消耗更多功耗。了解 MWS 对功耗的影响至关重要,因为基于 NAND 闪存的 SSD 具有有限的功耗预算(例如,PCIe Gen4 SSD 的预算为 75W )。图 14 展示了执行块间 MWS 时,NAND 闪存芯片的平均功耗随同时激活block数量的变化关系。为了测量最坏情况下的功耗,我们每个block仅读取一条字线(即,我们对每个block的一条字线施加VREF,同时对所有非目标字线施加 VPASS (>VREF)。我们将图 14 中的所有值相对于常规页读取操作的平均功耗进行了归一化。
我们得出了三个观察结果。第一,块间 MWS 的 NAND 闪存芯片功耗随激活block数量的增加而显著增加。将激活block的数量从 1 个增加到 2 个会使平均功耗增加约 34%。第二,尽管功耗增幅不容忽视,但仍可以在 SSD 的功耗预算范围内支持块间 MWS。在激活四个block以内,块间MWS的功耗仍低于擦除操作。第三,与对相同字线进行串行读取相比,块间 MWS 的能效(energy efficient)更高。例如,在四个不同block上执行块间 MWS 操作,相比常规读取会导致约 80% 的功耗增加,但由于其延迟增加极小(3.3%),与对四条字线进行单独读取相比,它显著降低了 53% 的能耗。我们的结论是,通过对块间 MWS 的(并发)数量进行适当限制,Flash-Cosmos 无需增加商用 SSD 的功耗预算。
Flash-Cosmos设计
我们展示了 Flash-Cosmos 用于支持高效闪存内大批量位运算的设计
扩展计算能力
我们通过两种方式增强了 Flash-Cosmos 的基本能力
支持其他位运算。我们利用真实NAND闪存芯片中广泛支持的两个现有特性,设计 Flash-Cosmos 以支持位非(NOT)、与非(NAND)、或非(NOR)、异或(XOR)和同或(XNOR)运算。第一,如前面所述,现代 NAND 闪存通常支持反向读取(inverse reads),这使得 Flash-Cosmos 不仅能执行位非运算,还能执行位与非和或非运算。Flash-Cosmos 通过在反向读取模式下读取字线(WL),即可实现对该字线的非(NOT)操作。如果我们在以反向读取模式控制感测锁存电路的同时执行块内(或块间)MWS(多字线感测),则感测到的数据将是所有同时读取字线的位与(或位或)结果的反转值,即根据定义,得到了位与非(或位或非)结果。
第二,许多现代 NAND 闪存芯片支持不同锁存器之间的数据位异或(XOR)运算(即 NAND 闪存芯片中为 MLC/TLC 编程操作准备的两到三个额外锁存器)。该特性对于支持片上随机化和提高可测试性至关重要(例如,通过支持将已编程数据与参考值(golden value)在片内进行直接比较,而无需将数据读出芯片,从而显著缩短测试时间。通过结合使用该特性与反向读取,Flash-Cosmos 还可以支持位同或(XNOR)运算,因为:
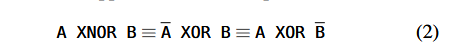
提高位级或(OR)运算的性能。与使用块内 MWS 实现的位与(AND)运算相比,使用块间 MWS 的位或运算性能受限。商用 NAND 闪存芯片可以通过单词块内 MWS 操作执行一个block内所有字线(WL)的位与运算。然而,受高功耗影响,块间 MWS 的最大操作数(操作对象数量)受到了限制。
通过 1) 块内 MWS 结合 2) 反向读取并 3) 利用德·摩根定律(De Morgan’s laws),我们可以消除对最大激活block数量的这种限制。如果我们在block中存储操作数的反转数据(而非原始数据),则可以利用反向读取模式和德·摩根定律,通过单次块内 MWS 操作来执行这些操作数的位或运算:

增加 IFP 的最大操作数数量。如果操作数(operands)的数量超过了一个block内的字线(WL)数量,仅靠 Flash-Cosmos 无法完全避免位与/位或/位与非/位或非运算的片外数据传输。这是因为块内 MWS 涉及单次感测操作来读取block内的所有字线,从而将最大操作数限制在单个block的字线数量之内。诚如第 5.2 节所述,由于受限的功耗预算,块间 MWS 对最大操作数的约束更为严格。
幸运的是,Flash-Cosmos 可以利用 ParaBit(其对最大操作数的限制较少)来累加(accumulate) 多次块内 MWS 操作的结果。例如,假设 (i) 一个block有N条字线,且 (ii) Flash-Cosmos 需要对M个不同block的所有字线执行位与(bitwise AND)运算(即总操作数为M×N)。我们可以分两步累加结果。首先,Flash-Cosmos 在每个block上执行位与运算,每次处理N个操作数。其次,Flash-Cosmos 对来自这M个block的结果执行位与运算。
Flash-Cosmos命令集
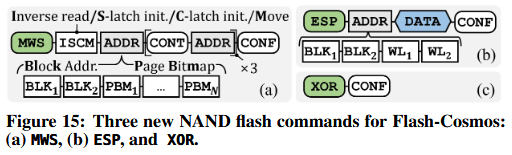
虽然我们证明了我们的 NAND 闪存芯片已经在其测试模式(test-mode)命令集中支持了执行 ESP 和 MWS 操作所需的所有功能,但高效设计Flash-Cosmos命令仍然至关重要,原因有二。第一,NAND 闪存供应商将他们的测试模式命令集设计视为专有技术(proprietary),不会在公开文档中披露任何细节。第二,高效的命令集设计可以显著减少对 NAND 闪存芯片控制逻辑的必要更改,并降低与闪存控制器(flash controller)之间的通信开销。
图 15 展示了我们为 Flash-Cosmos 设计的三个新 NAND 闪存命令:(a) MWS、(b) ESP 和 (c) XOR。我们设计的 MWS 命令用于 Flash-Cosmos 中除位异或(bitwise XOR)之外的所有三个必要功能:(i) 块内和块间 MWS、(ii) 反向读取,以及 (iii) 之前所述的所有读取结果的累加。为此,我们从三个方面扩展了包含操作码和目标页地址的常规读取命令。
第一,我们在地址槽(address slot)之前添加了 ISCM 命令槽,允许闪存控制器通过设置专用标志位来开启或关闭四项功能:(i) 反向读取模式、(ii) 感测锁存器(S-latch)初始化、(iii) 缓存锁存器(C-latch)初始化,以及 (iv) 数据从 S-latch 向 C-latch 的传输。第二,我们通过在地址槽中发送页位图(PBM)而非页索引,使闪存控制器能够高效地指定 MWS 操作中需要激活的字线(WL)。第三,我们设计了一个 MWS 命令,通过在 CONT(继续)槽之后发送额外的block地址和 PBM,使其最多可以拥有四个用于块间 MWS 的地址槽。ESP 命令与常规编程命令具有相同的命令接口;而 XOR 命令则在两个锁存器(感测锁存器和缓存锁存器)之间执行位异或运算,并将结果存储在 C-latch 中。
注解:CONT 是一个命令槽(command slot),用于指示后续将紧跟一个地址周期(address cycle)。 CONF 是一个命令槽,用于指示命令序列(command sequence)的结束。

图 16 通过一个示例展示了闪存控制器如何利用 Flash-Cosmos 执行大批量位运算。该示例基于两个假设:(i) 一颗支持 Flash-Cosmos 的芯片在四个block Bi(1≤i≤4)中存储了四组位向量 Ai,Bi,Ci和 Di(每组包含四个位向量),每个block有四个页;(ii) 预知位向量 Ci 和Di将被用于位或(OR)运算,因此使用它们的反转数据进行编程。
假设用户希望执行以下位运算:
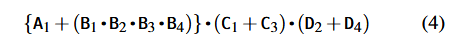
如图 16 所示,用户可以使用两条块内 MWS 命令来执行这些位运算:
❶ 第一条用于计算 (C1+C3)⋅(D2+D4),同时开启反向读取模式并开启两个锁存器的初始化;
❷ 第二条用于计算 A1+(B1⋅B2⋅B3⋅B4),同时关闭反向读取模式并关闭两个锁存器的初始化。
通过在执行第二条 MWS 命令时禁用两个锁存器的初始化,这两条 MWS 命令(❶ 和 ❷)的结果将同时在 S-latch(感测锁存器)和 C-latch(缓存锁存器)中进行累加。注意,这两条 MWS 命令的顺序非常重要,因为反向读取需要初始化 S-latch,这会阻止之前结果的累加。
系统级支持
我们简要讨论了为高效启用 Flash-Cosmos 所构思的端到端系统支持。
需求(Requirements): 为了充分发挥支持 Flash-Cosmos 的 NAND 闪存芯片的优势,系统需要满足两个关键需求。第一,位运算的目标数据需要使用 ESP(增强型 SLC 模式编程)进行妥善存储。为了最大化 Flash-Cosmos 的性能收益,尽可能将同一个位运算的多个操作数存储在同一个block(Block)中至关重要,因为这能最大限度地减少所需的 MWS 操作次数。例如,对 48 个页(即操作数)进行位或(OR)运算,如果每个操作数都存储在不同的block中,在假设为了避免功耗相关问题而将单次块间 MWS 激活的页数限制为 4 的情况下,将需要 12 次块间 MWS 操作。然而,如果将操作数及其反转数据(Inverse Data)存储在同一个block内,就可以利用反向读取模式,仅通过一次块内 MWS 操作完成相同的位或运算。第二,主机系统需要与底层 SSD 进行交互,以便高效地存储数据,从而最大化 Flash-Cosmos 的收益。
应用层更改(Application Changes): 在我们的设计中,应用程序需要从三个方面决定数据如何存储。第一,应用程序确定哪些数据将用于大批量位运算,以便通知 SSD 仅针对这些数据选择性地使用 ESP(以最小化 SLC 模式带来的存储开销)。第二,根据最能从 Flash-Cosmos 中获益的计算类型,应用程序决定是否存储原始数据的反转形式。例如,如果应用程序对某些数据执行位或运算的频率高于位与(AND)运算,那么存储反转数据以利用块内 MWS 执行位或运算可能会更有益。第三,应用程序决定哪些操作数应存储在同一个block内,以最小化执行同一种位运算所需的 MWS 操作次数。
系统软件更改(System Software Changes): 在我们的设计中,应用程序通过 Flash-Cosmos 库与 SSD 进行交互,该库包含两个方法:(i) fc_write,用于写入位运算的操作数数据;(ii) fc_read,用于读取位运算的结果。通过使用 fc_write,应用程序向 SSD 告知操作上下文,例如编程模式和存储位置(如逻辑块地址),以确保数据针对闪存内计算(in-flash computation)进行妥善存储。为了执行闪存内位运算,应用程序使用 fc_read 向 SSD 指定目标操作数的位置、操作数的大小以及所需的位运算类型。
SSD 更改(SSD Changes): 在我们的设计中,SSD 固件需要两项关键更改。第一,它生成 Flash-Cosmos 命令,以妥善处理来自主机系统的 fc_write 和 fc_read 请求。第二,SSD 固件维护 Flash-Cosmos 所需的额外元数据,例如每个页(page)的编程模式以及该页应当存储的位置。
在本研究中,我们的重点是利用现代 NAND 闪存芯片调查 Flash-Cosmos 的可行性和收益。虽然对 Flash-Cosmos 的端到端支持需要在系统技术栈的各个层级进行多项更改,但我们认为可以应用现有方法来满足关键需求。我们将为 Flash-Cosmos 开发更高效的端到端系统设计和软件栈留作未来工作。
评估方法
评估系统(Evaluated Systems)。 为了评估 Flash-Cosmos 的有效性,我们分析了四种计算平台:(i) 存储外处理系统 (OSP);(ii) 存储内处理系统 (ISP);(iii) ParaBit (PB) ;以及 (iv) Flash-Cosmos (FC)。OSP 使用主机 CPU 执行大批量位运算,同时分批将操作数从 SSD 读取到主内存。ISP 利用由简单位逻辑和 256-KiB SRAM 缓冲区组成的存储内硬件加速器,在 SSD 内部执行大批量位运算,并仅将最终结果发送给主机。PB 和 FC 分别通过先前描述的闪存内处理机制,在 NAND 闪存芯片内部执行大批量位运算,且仅将最终结果发送给主机。除非另有说明,为了进行公平的性能对比,我们将所有评估系统设置为在 SLC 模式下对位运算的输入和输出进行编程(并据此进行读取)。

性能建模(Performance Modeling)。 我们使用两种最先进的模拟器来分析评估系统的性能。我们在 Ramulator(一种广泛使用的周期精确 DRAM 模拟器)中,使用 DDR4 接口对 DRAM 时序进行建模。我们使用 MQSim (一种最先进的 SSD 模拟器)对 SSD 性能进行建模。我们扩展了 MQSim,利用从真实设备特性分析(“真实设备特性表征”小节)中获得的时序参数,真实准确地模拟了 ISP、ParaBit 和 Flash-Cosmos 的性能。我们基于两个计算阶段的吞吐量来对评估系统的端到端吞吐量进行建模,这两个阶段分别是:SSD 读取(包括 ISP、PB 和 FC 中的内部分析处理)和主机端计算(我们在真实主机系统上测量得出)。表 1 总结了用于评估的 SSD 和主机系统的配置。
能耗建模(Energy Modeling)。 我们使用 Intel RAPL测量主机端计算的能耗消耗。为了对 DRAM 的能耗消耗进行建模,我们使用了基于 DDR4 模型的 DRAM 功耗值。为了对 SSD 的能耗消耗进行建模,我们使用了三星 980 Pro SSD的功耗值,以及我们在真实设备特性分析中测得的 NAND 闪存功耗值。
工作负载(Workloads)。 我们评估了三个重度依赖大批量位运算的真实应用。为了与 ParaBit 进行公平对比,我们评估了位图索引(Bitmap Indices)和图像分割(Image Segmentation),以及一个名为 k-clique star listing的图处理工作负载。对于所有工作负载,由于数据集规模庞大,我们假设其初始状态均存储在 SSD 中。
1) 位图索引 (BMI): 位图索引是数据库中传统 B 树索引的替代方案,与 B 树相比,它在许多查询(如连接和扫描)中能提供更高的空间效率和性能。我们假设有一个数据库每天跟踪网站u个用户的登录活动。对于第i天,数据库维护一个包含u个元素的向量 Di,其中每个元素是一个 1 位(1-bit)标志位,用于指示每个用户当天的登录活动(0:未登录,1:已登录)。我们的 BMI 工作负载运行以下查询:“过去 m个月内,有多少用户每天都处于活跃状态?”执行该查询需要:(i) 对d个向量进行按位与(AND)运算(其中 d是过去 m 个月的天数);(ii) 执行位计数(Bit-count)操作,即统计给定结果向量r中“1”(已登录)位的数量。我们假设数据库跟踪 8 亿用户的登录活动,并在m从 1 到 36 变化的情况下评估 BMI 工作负载。在执行 BMI 工作负载时,PB 和 FC 在分批次将结果向量发送到主内存的同时,利用主机 CPU 并发地执行位计数操作。
2) 图像分割 (IMS): 图像分割是一种图像处理核心算子,旨在根据给定的一组颜色将图像划分为多个区域。为了确定像素p是否属于特定颜色C,我们的 IMS 工作负载使用 YUV 色彩识别,并对 Y(p,C)⋅U(p,C)⋅V(p,C)执行按位与(AND)运算,其中 Y(p,C)、U(p,C)和V(p,C)是可以通过预处理获得的二进制值。在我们的评估中,IMS 分割I张图像,每张图像由 800×600 个像素组成,包含四种颜色。这可以通过对三个位向量执行大批量按位与运算来完成,其中每个位向量包含I×800×600×4 位。我们假设这三个位向量最初存储在 SSD 中,并在I从 10,000 到 200,000 变化的情况下评估 IMS 工作负载。
3) k-团星罗列 (KCS): k-团星罗列(K-clique star listing)旨在找出输入图中所有的 k-团星。对于给定的图,k-团(k-clique)是一个具有k个相互全连接顶点的子图。一个 k-团星是 (i) 一个 k-团和 (ii) 图中剩余部分里所有与该 k-团每一个顶点都相连的顶点的集合。先前的工作表明,通过采用以集合为中心的表述方式(set-centric formulation),k-团星罗列可以利用内存内处理(PIM)显著加速 。在我们的评估中,每个顶点都使用一个位向量表示,该向量包含了与图中所有其他顶点的邻接信息。每个 k-团由另一个位向量表示,用于指定属于该 k-团的顶点集。通过这种位向量表示方式,我们的 KCS 工作负载只需对相应 k-团中所有顶点的位向量执行按位与运算,即可确定一个 k-团星。为了形成 k-团星的最终表示,KCS 对计算出的中间位向量和表示该 k-团的位向量执行按位或(OR)运算。需要注意的是,如果 k-团位向量存储在与存储顶点邻接向量不同的块(block)中,Flash-Cosmos 可以同时执行按位与和按位或运算。我们使用了一个具有 3200 万个顶点和 1,024 个 k-团的输入图,并将团的维度(维度即大小)从 8 遍历至 64。
评估结果
对性能的影响
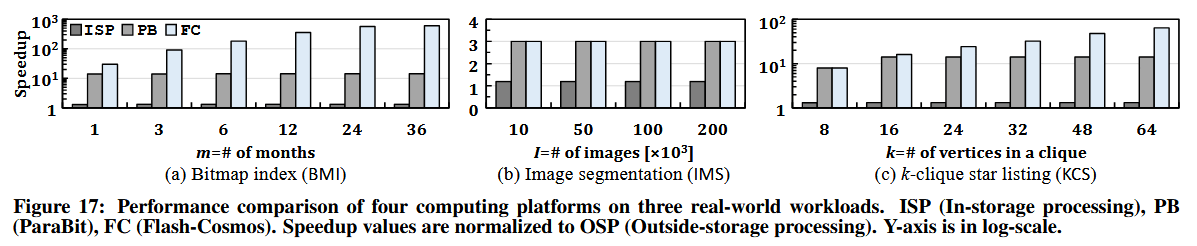
图 17 展示了 Flash-Cosmos (FC)、Para-Bit (PB) 和存储内处理系统 (ISP) 相对于传统存储外处理系统 (OSP) 的加速比。我们从图 17 中得出六点观察结论。
首先,FC 的性能显著优于 OSP,在所有三个工作负载和输入数据集上平均实现了 32 倍的加速。在 OSP 中,由于位运算的性质非常简单,计算开销可以完全被操作数的读取过程所掩盖,但 SSD 的外部带宽限制了性能。这意味着,当操作数存储在存储系统中时,任何其他存储外处理平台(如 GPU 或近内存处理器)都无法在 OSP 的基础上提高大批量位运算的性能(除非增加 SSD 的外部带宽)。
其次,FC 的性能也显著优于 ISP,平均提供 25 倍的加速。虽然 ISP 通过减少来自 SSD 的外部数据移动(外部带宽为 8 GB/s,见表 1),相对于 OSP 提供了显著的加速(28%),但其有限的 SSD 内部带宽(9.6 GB/s,见表 1)成为了新的瓶颈。ISP 需要将所有操作数从 NAND 闪存芯片读取到硬件加速器中,而闪存内处理(in-flash processing)可以很大程度上避免这一过程。
第三,FC 相较于 Para-Bit 提供了巨大的性能提升。虽然 PB 相对于 OSP(和 ISP)也显著优于 9.4 倍(7.2 倍),但在所有三个工作负载和输入数据集上,FC 平均优于 PB 3.5 倍。这突出了在真实应用中执行 MWS(多字线传感)的核心优势。
第四,FC 的收益随着大批量位运算中所使用的操作数数量的增加而增加。FC 在 BMI 工作负载下的加速比高于其他两个工作负载,因为 BMI 具有更多的操作数(从 30 个到 1,095 个)。相比之下,PB 的性能并不会随着操作数数量的增加而提高(例如在 KCS 中当 k>16)。这是因为前面所讨论的,PB 的性能瓶颈转移到了操作数的串行传感上,因此延迟会随着操作数数量的增加而线性增长。其结果是,虽然 FC 在 BMI 工作负载上相对于 OSP/ISP 的性能显著提升了 198.4/150.5 倍,但 PB 对比 OSP/ISP 的收益仅保持在 14/10.7 倍。
第五,FC 的收益不仅受操作数数量的影响,还受操作数大小的影响。例如,FC 同样执行与运算(AND),在 BMI(当 m=1)中处理 30 个操作数,在 KCS(k=32 时)中处理 32 个操作数。尽管 KCS 的操作数比 BMI 多,但我们观察到 FC 在 BMI 上相对于 PB 的提升更高。这是因为 BMI 的结果位向量总大小(100 MB)远小于 KCS(4 GB),从而减少了将结果从 SSD 传输至主机的外部 I/O 时间。如图 7(d) 所示,如果应用内的外部 I/O 时间(例如,由于将结果移出 SSD)大于总传感时间,那么即使是闪存内处理,外部数据搬移也可能成为瓶颈。因此,如果外部 I/O 时间在总执行时间中占主导地位,FC 相对于 PB 的收益就会降低。
第六,FC 和 PB 在所有输入集的 IMS 工作负载下表现出几乎相同的性能。尽管在执行 IMS 工作负载时,FC 相比 PB 将平均传感操作次数减少了 3 倍,但对于这两种机制而言,将庞大的 IMS 结果向量(高达 44 GiB)搬移至主机的时间在总执行时间中占据了主导。这与 BMI 形成了鲜明对比,后者的向量大小仅为 100 MB。需要注意的是,在 IMS 中,通过减少作为性能瓶颈的内外部数据传输量,FC 和 PB 相对于 ISP 和 OSP 均提供了较高的加速比(分别为 2.5 倍和 3 倍)。
我们得出结论,Flash-Cosmos 是加速重要现实应用的一种有效架构。Flash-Cosmos 不仅在性能上大幅超越了最先进的闪存内处理(IFP)技术,而且至关重要的是,它提供了可靠、无错误的操作执行(这对于我们评估的所有三个现实工作负载获得正确结果是必不可少的)。
对能耗的影响
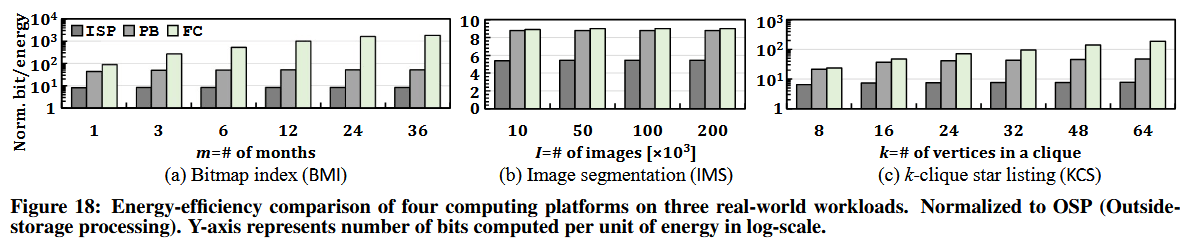
图 18 展示了 FC、PB 和 ISP 的能耗效率,即单位能耗下可计算/传输的比特数,并相对于 OSP 进行了归一化处理。我们得出了以下三点观察结论:
首先,FC 的能耗效率显著优于其他评估系统,在所有三个工作负载和输入集上,其能耗效率平均比 OSP/ISP/PB 分别高出 95 倍、13.4 倍和 3.3 倍。在 BMI 工作负载且 m=36m=36 时,Flash-Cosmos 相比 OSP/ISP/PB 实现了最大的能耗节省,分别达到 1,839 倍、222 倍和 35.5 倍。
其次,FC 能耗效率收益的整体趋势与其性能收益相似。FC 的能耗收益随操作数数量的增加而增加(随操作数大小的增加而减少)。
第三,FC 不仅通过减少数据移动来降低能耗,还显著降低了传感能耗,尤其是对于多操作数运算。因此,它在能耗效率方面的提升(相比 OSP 平均提升 95 倍)比性能方面的提升(相比 OSP 平均提升 32 倍)更为显著。注意到,如图 17(b) 和 18(b) 所示,对于 IMS 工作负载,尽管 FC 的性能表现与 PB 相似,但它仍实现了 2.3% 的能耗节省。
我们得出结论:对于许多常用的现实应用,Flash-Cosmos 是一种高效的底层架构,能够消除因数据移动带来的能耗开销。
开销分析
Flash-Cosmos 由于使用 ESP(增强型 SLC 模式编程)来实现可靠的闪存内计算,从而引入了两个关键开销。首先,与常规 SLC 模式编程相比,ESP 需要 2 倍的页编程延迟。其次,与 MLC 模式编程相比,存储相同数量的数据,ESP 消耗 2 倍的存储容量。
虽然写入性能和容量开销不容忽视,但我们认为,出于以下三个原因,这两个开销不会成为采用 Flash-Cosmos 的严重障碍。首先,ESP 对于确保闪存内计算的可靠性至关重要。常规 SLC/MLC 模式编程表现出的 RBER(原始比特错误率)显著高于 UBER(不可纠正比特错误率)要求,而 ESP 有效地解决了闪存内计算中遇到的这一重要可靠性问题。
其次,写入性能和容量开销仅适用于用于大批量位运算的数据。因此,Flash-Cosmos 可以通过仅对涉及闪存内处理(大批量位运算)的数据选择性地使用 ESP,而对其余数据使用常规 SLC/MLC/TLC 模式进行编程,从而最大限度地减少这些开销。现代 NAND 闪存的多编程模式支持这种功能,即任何块都可以按 SLC、MLC 或 TLC 模式进行编程 。
第三,与 MLC 模式编程相比,ESP 在带宽和延迟方面均不会降低 SSD 的写入性能。这是因为在我们的评估芯片中,ESP 的编程延迟仍低于 MLC 和 TLC 模式的编程延迟(分别为 500 µs 和 700 µs)。我们评估了 ESP 的顺序写入带宽,结果显示 ESP 提供的写入带宽为 4.7 GB/s,达到了常规 SLC/MLC/TLC 模式写入带宽(分别为 6.4 / 3.87 / 2.82 GB/s)的 73.4% / 121.4% / 166.7%。
相关工作
据我们所知,这项工作首次实现了通过单次传感操作在多个操作数上执行闪存内大批量位运算,同时在计算结果中实现了零比特错误。我们已经全面比较了与 Flash-Cosmos 密切相关的最先进技术。我们在此简要介绍存储层次结构中不同层级的其他近数据处理(NDP)方案。
闪存内处理(In-Flash Processing) 。此前的一些研究提出了闪存内处理技术,用以加速神经网络和混合信号传感等不同应用中的乘累加(MAC)运算。与 Flash-Cosmos 类似,这些机制具有很高的位级并行性,但它们利用的是模拟电流累加,这需要对 NAND 闪存单元阵列结构进行重大更改,例如在芯片内部部署精确且昂贵的模数转换器。相比之下,我们的机制可以以极低的成本应用在商用 SSD 中。
存储内处理(In-Storage Processing) 。此前的一些研究建议利用存储设备内部的处理器或在其中嵌入硬件加速器进行计算。由于其设计更通用,这些方案可以执行更多样、更复杂的运算(如算术运算)。然而,存储内处理需要首先从闪存芯片中读出处理过的数据,并将其通过 SSD 内部 I/O 链路传输到 SSD 控制器,这成为了性能瓶颈。相比之下,Flash-Cosmos 通过在闪存芯片阵列内部执行计算,可以有效减少 NAND 闪存芯片与 SSD 控制器之间的数据移动,从而实现比存储内处理高出一个数量级以上的性能和能量效率。
内存内与缓存内处理(In-Memory and In-Cache Processing) 。大量的现有研究提出了存储层次结构中其他层级的各种 NDP(近数据处理)技术,例如主存内和 SRAM 缓存内的技术。尽管这些工作提供了显著更低的访问延迟和高可靠性,但一旦处理的数据规模超过了缓存和主存的容量,数据就必须在存储设备与存储层次结构的其余部分之间进行跨层移动。Flash-Cosmos 可以与这些 NDP 方案(包括存储内处理)形成互补,它通过在闪存阵列内部直接处理大量数据,并仅向外通信传输计算结果来实现。
讨论
扩展至其他应用(Extensions to Other Applications) 。Flash-Cosmos 不仅可以用于加速位运算,还可以加速任何所需的运算。这是因为 Flash-Cosmos 支持一组在逻辑上完备的位运算,这与利用存储单元操作原理进行计算的其他“存算一体”(PuM, processing-using-memory)架构类似,例如 Compute Caches (基于 SRAM 的 PuM)、Ambit (基于 DRAM 的 PuM)和 Pinatubo (基于 NVM 的 PuM)。后续研究(如 DualityCache 、SIMDRAM 和 IMP )提出了利用这些底层架构和技术自动创建所需复杂运算(如加法和乘法)的框架,以加速广泛的工作负载,包括图处理、数据库、神经网络和基因组分析。我们将为 Flash-Cosmos 开发此类框架的工作留作未来的研究方向。
局限性(Limitations) 。Flash-Cosmos 有两个关键局限性,这也是其他 PuM 方案中普遍存在的。首先,与 ParaBit 和其他 PuM 提案一样,Flash-Cosmos 与现代 SSD 中广泛使用的主流加密技术(如 AES-256)的结合并不直接。这是因为广泛使用的加密技术具有输入数据依赖性,和/或需要位运算之外的复杂计算(如移位)。一种可能的解决方案是采用同态加密(homomorphic encryption),它可以保持加密数据计算的正确性。尽管同态加密目前在计算和容量开销方面面临许多挑战,但我们认为,开发高效的同态加密将是解决 PuM 范式在处理加密数据时这一共同问题的潜力方向。
其次,与 ParaBit 和其他 PuM(存算一体)提案类似,Flash-Cosmos 仅在操作数存储在同一芯片中时才能加速大批量位运算。系统可以潜在地利用高效的片间数据迁移技术,在后台将目标操作数收集到同一个块中,但这样做不可避免地会产生数据移动,从而削弱 Flash-Cosmos 带来的收益。当操作数存储在不同芯片中时,使用靠近 NAND 闪存芯片的硬件加速器进行存储内处理可能会更有效。幸运的是,Flash-Cosmos 仅需要对商用 NAND 闪存芯片进行微小的改动,这使得它可以很容易地与此类存储内处理解决方案相结合。我们将 Flash-Cosmos 与其他 NDP(近数据处理)方案的集成留作未来的研究方向。
总结
我们提出了 Flash-Cosmos,这是一种新型的闪存内处理(in-flash processing)技术,它显著提高了闪存内大批量位运算的性能、能量效率和可靠性。Flash-Cosmos 通过利用 NAND 闪存的单元阵列结构和操作原理,充分发挥了现代 NAND 闪存中蕴含的巨大比特级并行性。首先,Flash-Cosmos 使芯片能够通过单次传感操作对多个(数十个)操作数执行大批量位运算。其次,Flash-Cosmos 增强了现有的 SLC 模式编程方案,实现了计算结果的零比特错误,从而让闪存内处理能够应用于以前无法实现的通用、错误敏感型应用程序。
我们利用 160 个真实的先进 3D NAND 闪存芯片,通过实验验证了 Flash-Cosmos 的可行性、性能和可靠性。基于真实工作负载的仿真评估表明,Flash-Cosmos 在性能和能量效率方面均显著优于存储外处理(outside-storage processing)、存储内处理(in-storage processing)以及最先进的闪存内处理技术,同时能够保证可靠运行。我们的结论是,Flash-Cosmos 是实现高效、高性能且可靠的闪存内计算的一个极具前景的基础架构。我们希望并期待未来的研究能从多个方面基于 Flash-Cosmos 展开,例如通过开发利用 Flash-Cosmos 优势的系统级框架,并展示其在更多工作负载中的收益。
随记
块间MWS操作的功耗随激活的块数增长很快,激活超过四个时,功耗超过擦除操作的功耗,但是可以通过反向读取,将或运算变成与运算,从而把操作数放在同一个sub block内