论文名称:HAVEN: High-Bandwidth Flash Augmented Vector ENgine for Large-Scale Approximate Nearest-Neighbor Search Acceleration
摘要
检索增强生成(RAG)依赖于大规模近似最近邻搜索(ANNS)来为大语言模型检索语义相关的上下文。在各类 ANNS 方法中,IVF-PQ 在内存效率和搜索准确性之间达到了理想的平衡。然而,为了实现高召回率,系统需要执行重排(reranking)步骤,该步骤涉及获取全精度向量进行计算。由于 GPU HBM(高带宽内存)容量有限,十亿级规模的向量数据库不得不驻留在主机 CPU 的 DRAM 或 SSD 中。这种脱离 GPU 的数据移动导致了严重的延迟增加和吞吐量下降。
我们提出了 HAVEN,这是一种增强型 GPU 架构,它集成了高带宽闪存(HBF)。HBF 是一种近期推出的堆叠芯片 3D NAND 技术,旨在提供 TB 级容量和数百 GB/s 的读取带宽。通过将 HBF 和近存储搜索单元作为 HBM 的封装内补充,HAVEN 使得全精度向量数据库能够完全驻留在设备端,从而消除了重排过程中 PCIe 和 DDR 的瓶颈。
通过对重构后的 3D NAND 子阵列、功耗受限下的 HBF 带宽以及端到端 IVF-PQ 流水线的详细建模,我们证明:与传统的 GPU-DRAM 和 GPU-SSD 系统相比,在十亿级数据集上,HAVEN 将重排吞吐量提升了高达 20 倍,延迟降低了高达 40 倍。我们的结果表明,增强了 HBF 的 GPU 能够以极高的吞吐量实现高召回率检索(该吞吐量此前仅在不进行重排的情况下才能达到),这为以内存为中心的 AI 加速器提供了一个极具前景的发展方向。
一、介绍
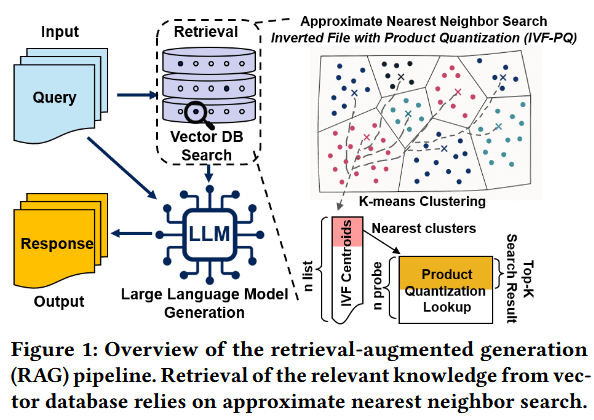
检索增强生成(RAG)已成为大规模语言模型的核心技术,它通过将参数化生成与非参数化外部知识源相结合来实现。如图 1 所示,RAG 的关键组件是检索模块,它通过搜索极大规模的向量数据库来返回语义相关的嵌入向量。因此,近似最近邻搜索(ANNS)算法对于实现在十亿级规模下的低延迟检索至关重要。
在各类 ANNS 算法中,倒排索引乘积量化(IVF-PQ)框架在平衡大规模向量数据库的准确性、内存占用和搜索效率方面被证明非常有效。IVF-PQ 首先通过粗糙量化对搜索空间进行划分,然后应用乘积量化(PQ)来压缩存储的向量。为了提高召回率,现代 IVF-PQ 实现会执行重排阶段,即获取原始的全维向量并进行重新排序。然而,该重排步骤需要访问未压缩的向量数据库,在十亿级向量规模下,其大小通常达到数百 GB 甚至更多。
目前的 GPU 在设备封装内集成了高带宽内存(HBM),虽然提供了卓越的带宽,但容量有限(每台设备通常为 80-192 GB)。因此,完整的 IVF-PQ 数据库无法放入 HBM,迫使系统将原始向量存储在主机 DDR 内存或 NVMe SSD 中。这种脱离 GPU 的数据移动引入了高出几个数量级的延迟,并显著降低了 ANNS 的吞吐量,尤其是在重排阶段。
为了克服这一容量瓶颈,新兴的研究和行业路线图提出了高带宽闪存(HBF),这是一种以类似于 HBM 的方式集成的堆叠芯片 NAND 闪存。HBF 每个堆栈中提供高出 8-16 倍的容量,同时通过大规模并行 3D NAND 子阵列保持数百 GB/s 的读取带宽。这些特性使得 HBF 成为读密集型工作负载中 GPU 封装内存极具吸引力的候选方案。
在这项工作中,我们推出了 HAVEN,这是一种在 GPU 封装内部用 HBF 取代部分 HBM 容量的架构。在 HBF 之上,我们还集成了近存储搜索单元,以进一步提升重排性能。通过 HAVEN,包括 IVF-PQ 重排所需的全精度向量在内的完整向量数据库可以存储在封装内并进行处理,从而消除了 DDR/SSD 的往返传输,并显著降低了检索延迟。我们分析了带宽与延迟的权衡,研究了架构集成的约束条件,并评估了其对 RAG 系统典型的大规模 ANNS 流水线的性能影响。
本文的主要贡献如下:
- 我们量化了当前仅配备 HBM 的 GPU 在执行 IVF-PQ 时的内存容量和带宽限制。
- 我们提出了 HAVEN,这是一种混合了 HBM 加 HBF 的 GPU 内存层级结构,配有近存储搜索单元,能够实现海量向量数据库的封装内存储与处理。
- 我们建模并评估了 HAVEN 上的 IVF-PQ 重排性能,证明与基于 DDR/SSD 的系统相比,其吞吐量提升了高达 20 倍,延迟降低了高达 40 倍。
二、背景
2.1 近似最邻近搜索
k-最近邻(k-NN)搜索的目标是从数据集 $X = \{x_1, \dots, x_N\}$ 中检索出与查询向量 $q \in \mathbb{R}^D$ 最接近的 $k$ 个点。精确搜索问题可以表述为: $R = \text{arg}\min_{R \subset X, |R|=k} \text{dist}(q, x)$
, 其中,$\text{dist}(\cdot, \cdot)$ 可以是欧几里得距离、余弦相似度或内积。暴力检索方案需要 $O(ND)$ 次比较,这对于百万或十亿级规模的数据集来说是不切实际的。为了满足实时延迟要求,现代系统依赖于近似最近邻搜索(ANNS),它在仅检查一小部分数据的情况下返回一个近似邻居集 $\hat{R}$。ANNS 方法的性能很大程度上取决于用于缩小搜索空间索引结构。常见的索引包括倒排文件(IVF)系统、基于图的方法以及基于哈希的方法,每种方法在延迟、内存占用和准确性之间提供了不同的权衡。

IVF-PQ 搜索。在本研究中,我们重点关注广泛使用的 IVF-PQ(倒排文件乘积量化) 索引技术,它在大规模近似最近邻搜索(ANNS)中实现了搜索速度与内存效率之间的良好平衡。如图 1 所示,IVF-PQ 能够自然地集成到基于大语言模型(LLM)的检索增强生成(RAG)流水线中。在离线索引构建期间,IVF 采用 k-means 算法将向量空间划分为 $N_{list}$ 个粗聚类,而乘积量化(PQ)则进一步将每个聚类内的残差向量压缩为短编码。这种结合使得在内存中存储数十亿个向量成为可能,同时保持了极具竞争力的检索准确性。在查询时,IVF-PQ 执行三个主要步骤(如代码段 1 所示):1) 粗量化器探测;2) 对所选倒排列表进行近似 IVF-PQ 扫描;3) 使用更高精度的距离对候选的 Top-k 结果进行重排。
步骤 1:粗量化器探测(Coarse Quantizer Probing)。给定一个查询向量 $q$,IVF 首先计算其与所有粗聚类中心的距离,并选择距离最近的 $N_{probe}$ 个中心。系统仅搜索对应的倒排列表,从而将搜索空间从 $N$ 个向量大幅缩小至与 $N_{probe}$ 成正比的一小部分。
步骤 2:对探测列表进行 IVF-PQ 扫描。在每个探测到的列表中,向量以压缩的 PQ 编码形式存储。查询向量与压缩向量之间的近似 PQ 距离可以通过轻量级的“查表并求和”过程计算得出。这个近似扫描阶段极其高效,并能提供候选邻居的初步排序。
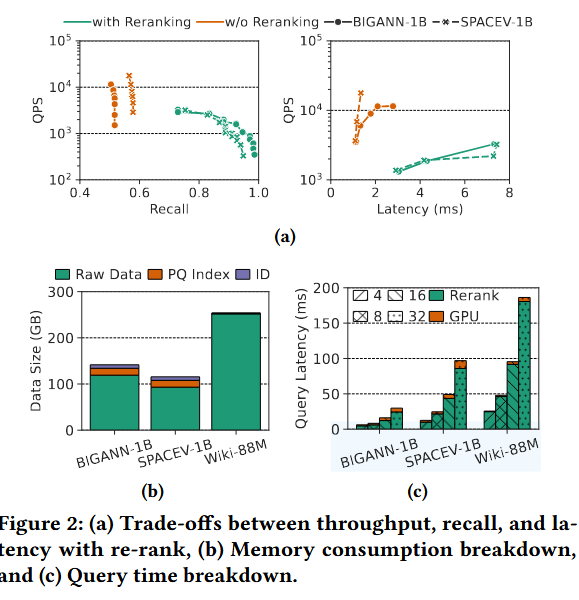
步骤 3:对 Top-k 候选者进行重排(Reranking)。由于 PQ 编码会引入量化误差,IVF-PQ 会通过使用全精度向量重新计算距离,对前 $N_{rerank}$ 个候选者进行重排。如文本图 2(a) 所示,重排操作仅针对一小部分向量进行,却能显著提升召回率,使 IVF-PQ 在高质量检索中兼具可扩展性和准确性。
2.2 剖析基于IVF-PQ的ANNS
由于 GPU 拥有极高的带宽和并行处理能力,它们被广泛用于近似最近邻搜索(ANNS),但十亿级规模的数据集很快就会超出 GPU HBM(高带宽内存)的有限容量。因此,现有系统通常仅在 GPU 上存储 IVF 索引和 PQ 编码,而将用于重排的全精度向量卸载到主机 DRAM 或 SSD 中。为了量化这种设计的影响,我们对实验室现有的一套系统进行了性能剖析,该系统配备了 DDR4 内存、NVMe SSD 和 NVIDIA A100 GPU(详见 4.1 节)。我们观察到以下局限性:
挑战 1:吞吐量、召回率与延迟之间的失衡。图 2(a) 显示,启用重排虽然能显著提高召回率,但会剧烈降低吞吐量并增加查询延迟。在不进行重排的情况下,系统可以获得较高的 QPS(每秒查询数),但召回率较低;而一旦开启重排,召回率虽有提升,吞吐量却会塌陷 1 到 2 个数量级。这种失衡使得系统难以同时满足高召回率和低延迟的要求,尤其是在实时或批处理约束下。
挑战 2:内存占用挑战。如图 2(b) 所示,原始向量占据了绝大部分的内存容量——对于 Wiki-88M 和 SIFT-1B 等数据集,其占用空间达数百 GB。在十亿级规模的部署中,将 PQ 编码存储在 GPU 上、同时将用于重排的原始向量存储在 CPU 内存或 SSD 中,会极大地膨胀总内存需求。有限的 GPU 内存强制引发了频繁的数据传输,而 DRAM/SSD 的容量限制也使得将规模扩展至数亿向量以上变得昂贵或不可行。
挑战 3:过长的重排延迟。如图 2(c) 所示,重排占据了查询时间的主要部分,因为全精度向量必须通过 PCIe 总线从 DRAM 或 SSD 中获取,这引入了巨大的延迟。这种开销在十亿级规模下会进一步增长,尤其是在处理大批量数据时。由于原始向量消耗了大部分内存空间(图 2(b)),它们无法驻留在 GPU 内,导致跨设备的数据访问不可避免,使得重排性能从根本上受限于内存容量和跨设备的数据移动。
2.3 新型高带宽闪存
上述瓶颈源于 IVF-PQ 重排(reranking)对内存的需求与封装内 HBM 有限容量之间的根本错配。A100 级别的 GPU 虽然提供了卓越的带宽,但容量仅有几十 GB,远不足以同时存储 PQ 编码和全精度向量。3D 非易失性存储器的最新进展引入了高带宽闪存(High Bandwidth Flash, HBF),这是一种在形态因子和信号传输上类似于 HBM 的堆叠 NAND 架构。与追求存储密度的 SSD 不同,HBF 展现了极大的内部并行性和更细的访问粒度。行业预测表明,在相似的占用面积下,HBF 可以提供比 HBM 高出 8 到 16 倍的容量,同时维持数百 GB/s 的读取带宽,这非常适合读密集型的向量检索工作负载。
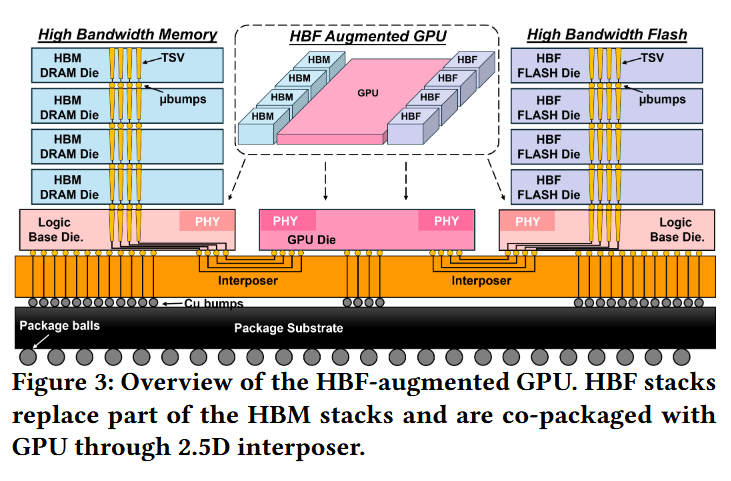
增强型 HBF GPU。当 HBF 取代 GPU 封装内部的部分 HBM 堆栈时,内存层级结构将获得一个如图 3 所示的设备端高容量层。将全精度向量直接存储在 HBF 中,可以消除主导重排阶段的 PCIe 和 DDR 瓶颈。这种集成带来了三个直接优势:(1) 更低的延迟,因为重排产生的数据流不再离开封装;(2) 充足的容量,足以在设备端完整存储十亿规模的原始向量;(3) 高重排带宽,这得益于分布式 NAND 子阵列带来的广泛并行性。
对 IVF-PQ 重排的影响。随着原始向量保留在封装内,重排从一个受延迟限制的阶段转变为高吞吐量的操作。因此,实现高精度的重排变得可行,而不会出现 CPU 或 SSD 后端系统中所见的吞吐量剧烈塌陷。大批量处理(Larger batches)也变得具有实际意义,从而在实时和离线 RAG 流水线中都能实现更高的 QPS。总之,HBF 将设计转向了以内存为中心的方法,扩展了 GPU 的有效容量并将重排保留在设备上。基于这一契机,我们提出了 HAVEN——一种 HBM 与 HBF 混合的向量搜索引擎,它在 HBF 中存储并处理原始向量,同时保留 HBM 用于延迟敏感的 PQ 操作。下一节将详细介绍其整体架构,以及底层的 3D NAND 重构和硬件设计。
三、HAVEN加速器
3.1 整体架构
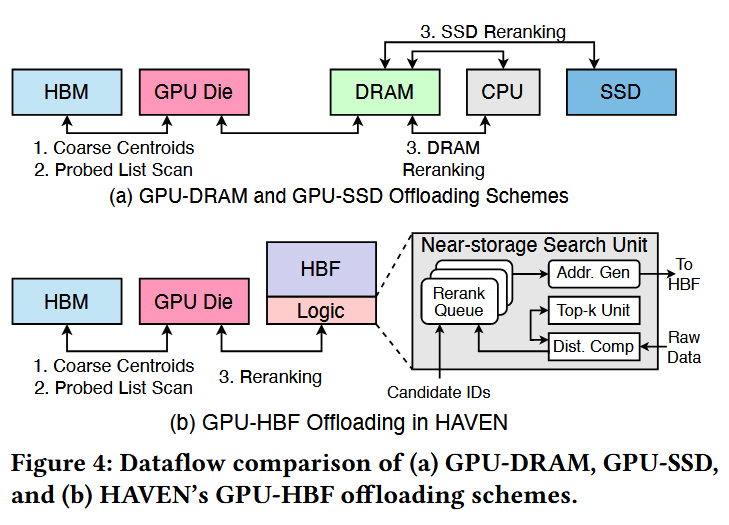
数据流 (Dataflow)。如图 3 所示,HAVEN 通过将 HBF 与 GPU 核心及 HBM 共同封装,采用了一种高效的数据通路。IVF-PQ 的前两个阶段(粗聚类中心探测和 IVF-PQ 列表扫描)保留在 GPU 和 HBM 上,以维持低延迟处理;而最后阶段——存储密集型的重排(reranking)——则被卸载到具有近存储处理(NSP)能力的 HBF 中。与基于 DRAM 或 SSD 的系统相比,这种设计显著降低了重排延迟。图 4 突出了其中的差异:在传统设计中(图 4(a)),全精度向量必须从 CPU 内存或 SSD 中获取,从而产生昂贵的 DDR 或 PCIe 传输开销。相比之下,HAVEN 的 GPU-HBF 数据流(图 4(b))将重排过程完全保留在封装内,消除了片外往返传输,并充分利用了 HBF 极高的内部带宽和并行性。
近存储搜索单元 (Near-Storage Search Unit)。由于重排阶段的算术强度较低,将原始向量从 HBF 搬运到 HBM 会引入不必要的数据移动。为了避免这种低效并降低查询延迟,HAVEN 使用实现在 HBF 堆栈底部逻辑层(Logic Die)上的近存储搜索单元,直接在 HBF 附近执行重排。如图 4(b) 所示,该单元首先从 GPU 接收候选向量 ID,并将其存储在重排队列(Rerank Queue)中。HAVEN 包含 32 个重排队列,每个队列配备一个 8 KB 的缓冲区,能够存储多达 1,024 个 32 位 ID 及其距离。随后,每个 ID 被传递给地址生成(Address Generation)模块,该模块负责计算其对应原始向量的物理地址。生成的地址被封装成读取请求并发送至 HBF。一旦获取到全精度向量,配备有 32 个乘加器(MAC)的距离计算模块(Distance Computation Module)便会计算其与查询向量的精确距离。最后,通过并行双调排序器(Bitonic Sorter)实现的 Top-k 单元筛选出最佳匹配的候选者。这些组件实现了完全的封装内重排,在最小化延迟的同时,最大限度地发挥了 HBF 的带宽优势。
3.2 针对HBF的3D NAND架构重构
将 NAND 技术应用于 HBF(高带宽闪存)需要对商用 3D NAND 的结构进行重新思考。商用 NAND 主要针对存储密度而非带宽进行设计,其性能无法匹配大规模 IVF-PQ 重排所需的细粒度及高度并行的访问模式。为了弥补这一差距,我们采用了一种分布式子阵列(distributed subarray) 组织结构,以增加内部并行度并提高总吞吐量。本节将阐述架构重构过程、子阵列建模框架以及全栈 HBF 建模流程。
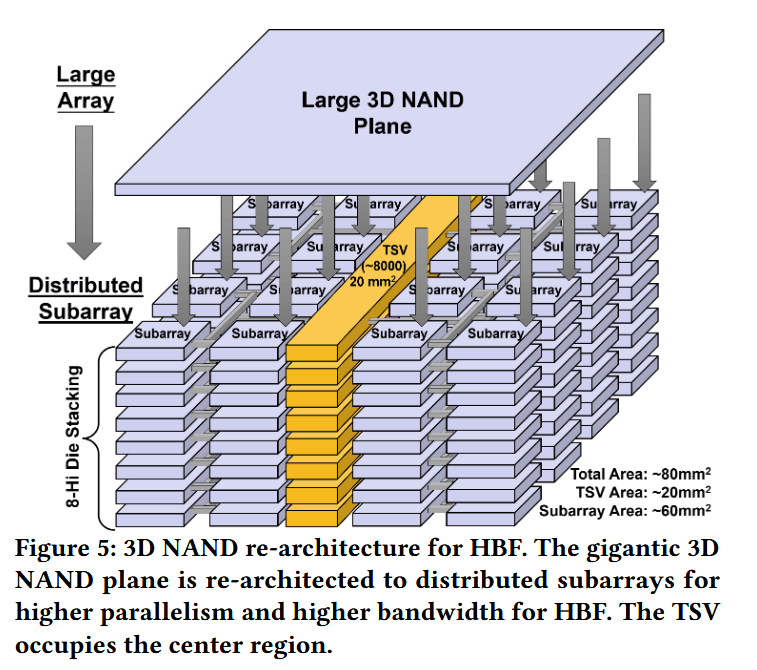
3D NAND 架构重构。传统的 3D NAND 是围绕巨型单体存储面(monolithic memory planes)构建的,旨在优化密度而非带宽。这种大容量阵列具有极长的位线(bitline)、极高的字线(wordline)寄生电容以及粗粒度的访问粒度。然而,这些特性与 IVF-PQ 重排所需的细粒度访问模式不相符。为了解决这种不匹配,如图 5 所示,我们借鉴了快速 NAND(fast NAND)的方法,从单体存储面转向分布式小尺寸子阵列。这种架构转变缩短了局部位线,降低了寄生效应,改善了访问能耗,并暴露了显著更多的并行子阵列。
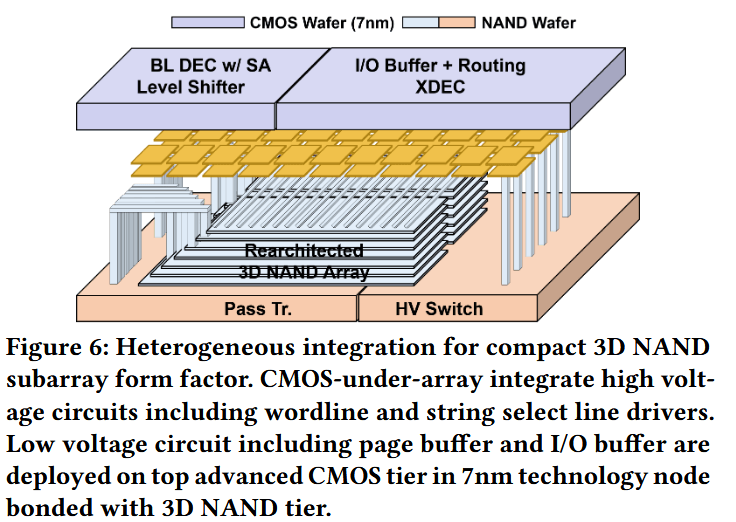
分布式子阵列建模。我们评估了将 3D NAND 分布到大量小尺寸子阵列中的架构权衡。在这种架构中,每个子阵列都配有独立的局部字线/位线驱动器和感测放大器,从而能够实现比传统 NAND 组织更高的内部并行度。此外,我们还引入了异构集成(heterogeneous integration),以进一步提高存储密度并提升性能,如图 6 所示。

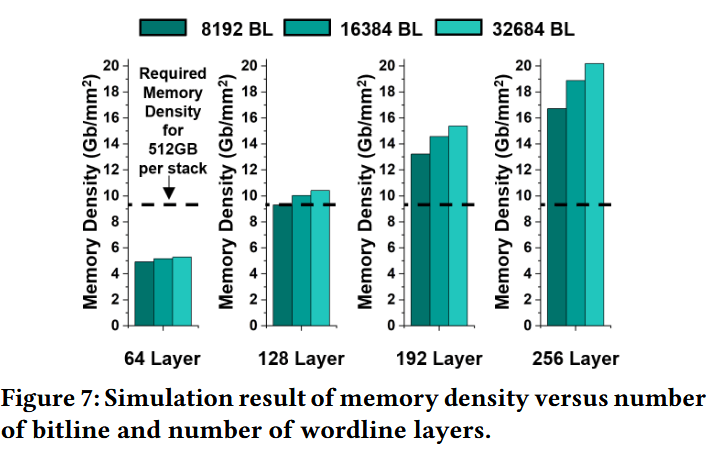
为了量化这种重构的影响,我们采用了一个基于 3D-FPIM 并结合 NeuroSim(用于缩放外围电路)的分布式 3D NAND 子阵列建模框架。这种组合能够实现从阵列级到芯片级的投射,涵盖 3D 堆叠层数、页大小(page size)和块大小(block size)等子阵列粒度参数。详细的 3D NAND 参数列于表 1 中。利用该仿真框架,我们首先扫描了 3D 堆叠中的字线(WL)层数,并评估了密度扩展趋势,如图 7 所示。分析表明,要在 8 层堆叠(8-Hi stack)中实现 512 GB 的容量,至少需要 128 层字线。为了给更多的向量数据库留出设计余量,并与最先进的 NAND 技术路线图保持一致,我们采用 256 层字线作为后续所有 HBF 建模的基准技术节点。
高带宽闪存(HBF)建模。我们将分布式子阵列模型整合到全栈 HBF 建模中。遵循 HBM 的堆叠组织,我们假设微凸块(microbump)的硅通孔(TSV)间距为合理的 50 μm,并维持图 5 中的 TSV 组织和 8 层芯片堆叠(8-Hi)配置,以便在容量、能耗和吞吐量扩展方面进行公平比较。注:我们的设计与 A100 GPU 中集成的 HBM2E 规范保持一致。
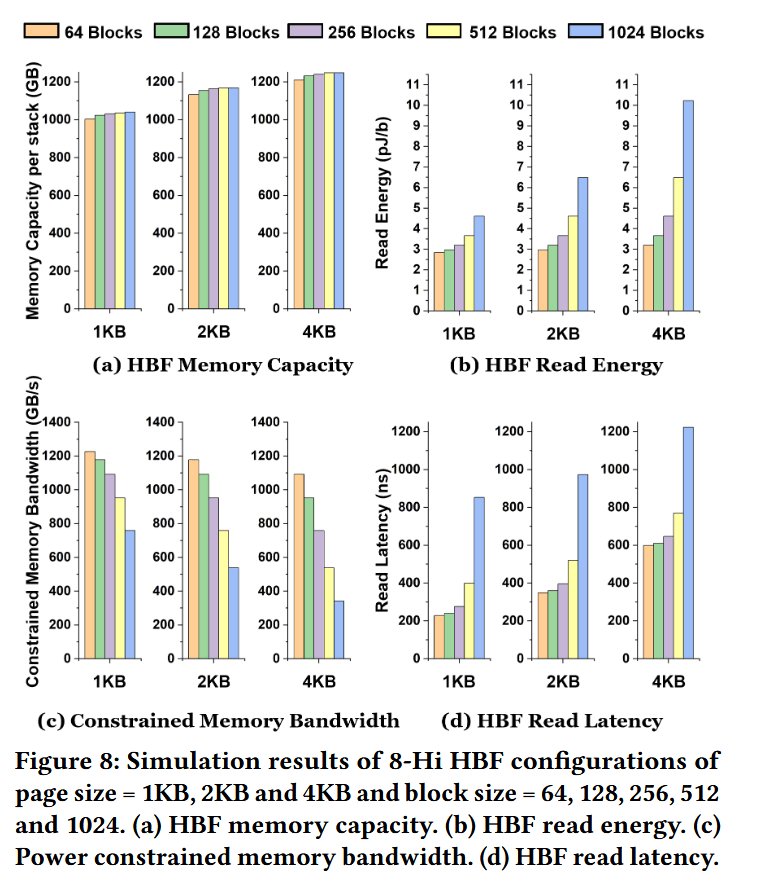
基于 3D-FPIM 子阵列建模的仿真结果揭示了预期的总体趋势,如图 8 所示。较大的子阵列(即更大的页大小或每个存储面包含更多块)提供了更高的容量密度,如图 8(a) 所示。然而,由于阵列内部导线变长以及 3D 结构寄生效应增加,它们也会提高读取能耗和读取延迟,如图 8(b) 和 8(d) 所示。相反,激进地缩小子阵列尺寸虽然会降低读取能耗并改善单次访问延迟,但会减小总容量。
在能耗方面,我们利用工业级 3D NAND 数据对读取能耗进行了校准。具体而言,我们以当代器件报道的约 $30\text{ pJ/bit}$ 读取能耗为基准进行缩放,并计入 HBM2 的数据移动能耗。在分布式子阵列配置中,读取能耗随页面尺寸(Page Size)的增大或块数量(Block Count)的增加而迅速上升,并最终成为限制可实现带宽的主要约束因素。
由于采用了细粒度的并行分布式子阵列架构,HBF 的带宽从根本上受限于供电功率。为了保持与 HBM 相当的热约束和封装约束,我们为每个堆栈(Stack)设定了类似 HBM 的 $30\text{ W}$ 功率包络。基于此约束,我们通过遍历不同的页面尺寸和块数量来评估可持续的读取带宽,结果如图 8(c) 所示。随着页面增大和块数增多导致容量提升,单次访问所需的功率随之增加,并最终限制了有效吞吐量。当块数量超过 128 时,由此产生的带宽退化尤为严重。为兼容 HBM2E 基础设施,我们设定每个堆栈的最大带宽为 $460\text{ GB/s}$。
读取延迟同样受到影响,如图 8(d) 所示。随着我们扩大子阵列的维度,阵列的 RC 延迟和页面激活时间均有所增加,导致不同配置下的延迟呈增长趋势。建模结果证实,存储容量与性能的扩展方向截然相反,没有任何单一设计能同时实现两者的最大化。
综合考虑上述权衡,我们选择了一种既能提供所需容量、又能保持高带宽并兼顾适度延迟的配置。我们将 $4\text{ KB}$ 页面尺寸、每个子阵列 $64$ 个块以及 $256$ 层字线(WL) 设定为后续架构分析的基准 HBF 配置。该配置提供了高并行度,在 $30\text{ W}$ 功率包络内实现了可控的读取能耗,并具备充足的容量,可支持在封装内存储十亿级向量以进行 IVF-PQ 重排。
四、评估
4.1 实验方法
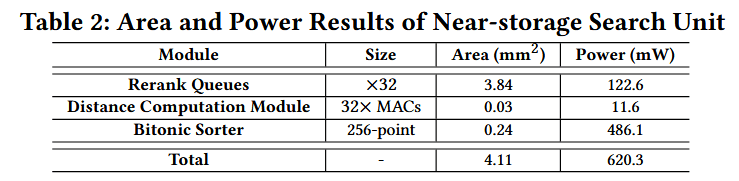
HAVEN 与 HBF 仿真。我们结合 3D-FPIM 和 NeuroSim 对重构后的 3D NAND 子阵列进行了仿真。其功耗模型经过工业级性能数据的校准(参考文献:1)。ASIC 近存储搜索单元采用 Verilog HDL 实现,并在 22 nm 技术节点下进行综合。该搜索单元的内核频率达到 1 GHz。表 2 总结了近存储搜索单元的面积和功耗结果:总占用面积为 4.11 mm²,功耗为 620.3 mW;其中重排队列(rerank queues)占据了主要面积,而双调排序器(Bitonic sorter)则是功耗的主要来源。
基准测试 (Benchmarks)。所有实验均在配备 AMD EPYC 7302 16 核 CPU、512 GB DDR4-3200 内存和 NVIDIA A100 40GB GPU 的服务器上进行。系统包含一块 8 TB PCIe 4.0 NVMe SSD,确保了大规模数据集和索引文件的高带宽存储访问。我们使用 Faiss 为所有数据集构建了 IVF-PQ 索引,并采用 16 字节的 PQ 编码。Faiss 中启用了 cuVS 集成以实现更快的查询搜索。我们在特定的召回率(Recall @k = 100)下,通过吞吐量(QPS)和查询延迟(ms)对不同设计方案进行对比。
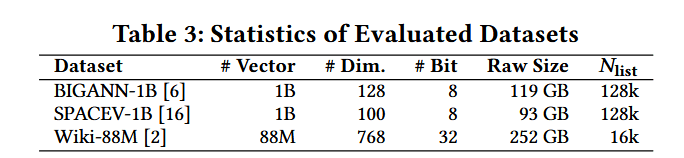
数据集 (Datasets)。我们在三个涵盖不同领域的大规模向量数据集上对 HAVEN 进行了评估。BIGANN-1B 和 SPACEV-1B 是两个十亿规模的数据集,向量维度分别为 128 维和 100 维。Wiki-88M 提供了 8800 万个高维(768 维)嵌入向量,具有典型的大语言模型(LLM)检索负载特征。表 3 总结了这些数据集的关键统计信息。
4.2 实验结果
我们通过将 BIGANN-1B 和 SPACEV-1B 的召回率固定在 0.95,并将 Wiki-88M 的召回率固定在 0.9 来测量性能。
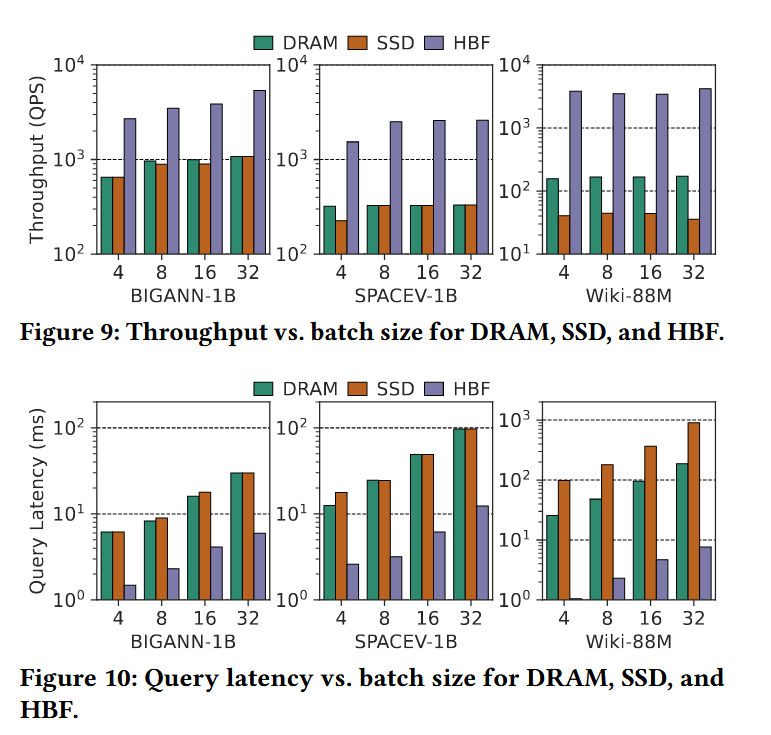
吞吐量 (Throughput)。图 9 展示了 DRAM、SSD 和 HBF 在不同批处理大小(batch sizes)下的吞吐量。HBF 在所有数据集上均实现了最高的 QPS(每秒查询数),并随批处理大小的增加平稳扩展;而 DRAM 和 SSD 则因数据移动瓶颈迅速达到饱和。在 BIGANN-1B 和 SPACEV-1B 数据集上,HBF 的吞吐量高出约 3-8 倍;在重排数据流量更大的高维数据集 Wiki-88M 上,其优势更是扩大到 20 倍以上。
延迟 (Latency)。图 10 报告了不同批处理大小下的查询延迟。HBF 保持了最低的延迟(约 10 ms),而 DRAM 尤其是 SSD 的延迟则因片外重排流量而急剧增加。在 BIGANN-1B 和 SPACEV-1B 上,HBF 比 DRAM 快 3-6 倍,比 SSD 快一个数量级以上;在 Wiki-88M 高维数据集上,其优势达到 10-40 倍。通过将原始向量保留在封装内,HBF 避免了 PCIe 和 NVMe 传输,使重排延迟被严格限制在极小范围内。
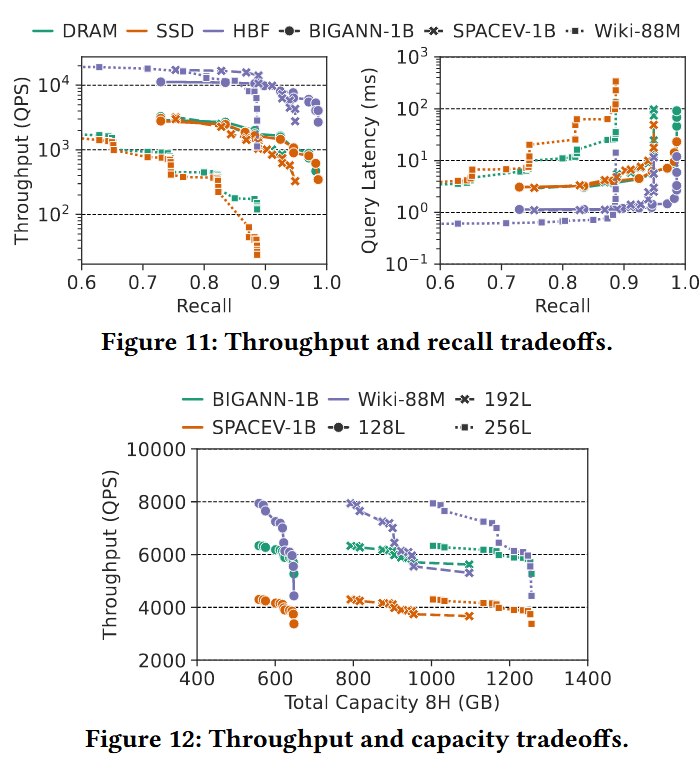
吞吐量与召回率的权衡 (Throughput and Recall Tradeoffs)。图 11 展示了吞吐量与召回率之间的权衡关系。HBF 始终在帕累托前沿(Pareto-dominates)优于 DRAM 和 SSD,在给定召回率下能维持更高的 QPS,在给定 QPS 下能实现更高的召回率。在高召回率(≥ 0.9)阶段,这种优势进一步扩大,因为不断增长的重排流量会导致 DRAM/SSD 因片外传输而承受剧烈的吞吐量下降和延迟惩罚。通过将重排保留在封装内,即使召回率目标更加严苛,HBF 也能同时保持高吞吐量和低延迟。
设计空间探索 (Design Space Exploration)。为了验证我们选择的子阵列配置(4 KB 页大小、64 个块、256 层),我们进行了设计空间探索。图 12 展示了容量与吞吐量之间的权衡:增加字线(WL)层数、块数量或页大小虽然可以提高容量,但会降低吞吐量。在 128L/192L/256L 选项中,256L 提供了最佳平衡;同时,“4 KB 页-64 块”的配置在容量与性能之间提供了最强的综合权衡,证实了我们基准选择的合理性。
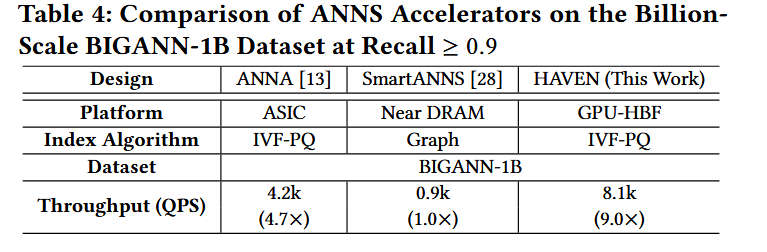
与其他加速器的比较 (Comparison with Other Accelerators)。表 4 将 HAVEN 与两种最先进的 ANNS 加速器在十亿级 BIGANN-1B 数据集(召回率 ≥ 0.9)上进行了对比。ANNA 是一种使用 16 字节 PQ 编码的 IVF-PQ ASIC 加速器,而 SmartANNS 是部署在 12 个 SmartSSD 上的基于图(graph-based)的系统。HAVEN 实现了 8.1k 的 QPS,分别比 ANNA 和 SmartANNS 快 1.9 倍和 9 倍。通过将封装内 HBF 存储与近存储重排集成,HAVEN 充分利用了极高的内部带宽并消除了片外瓶颈,使其性能超越了专用 ASIC 方案和基于 SmartSSD 的加速器。
五、结论
本研究提出了 HAVEN,这是一种通过 HBF(高带宽闪存) 增强的 GPU 内存架构,旨在克服大规模近似最近邻搜索(ANNS)中 IVF-PQ 重排(reranking)所面临的容量瓶颈与数据移动限制。通过将 3D NAND 重新构建为适用于 HBF 的分布式子阵列,并将其集成在 GPU 封装内部,HAVEN 实现了具备高读取带宽的 TB 级封装内向量存储。此外,近存储搜索单元(near-storage search unit) 在 HBF 堆栈内部直接执行重排操作,从而消除了片外数据传输开销。
我们的评估结果表明,与传统的 GPU-DRAM 和 GPU-SSD 系统相比,HAVEN 在十亿级数据集上的重排吞吐量提升了高达 20 倍,延迟降低了高达 40 倍。这突显了 HBF 作为未来“以内存为中心”的 AI 加速器的一个极具前景的发展方向,能够有效应对 RAG(检索增强生成)等检索密集型工作负载。
参考文献
1.Kana Kudo, Yuta Aiba, Kazuma Hasegawa, Xu Li, Yuichi Sano, and Tomoya Sanuki. 2025. Energy-Efficient In-Memory Computing using 3D Flash Memory with Sequential Multi-Block Activation and Current Control Cell (CC cell). In 2025 IEEE International Memory Workshop (IMW). 1–4. [doi:10.1109/IMW61990. 2025.11026979](https://doi.org/10.1109/IMW61990.2025.11026979)