论文全名:VoiceAgentRAG: Solving the RAG Latency Bottleneck in Real-Time Voice Agents Using Dual-Agent Architectures
摘要
检索增强生成(RAG)使语言模型能够将其回答建立在外部知识的基础上,但检索步骤引入了与实时语音对话不相容的延迟。典型的向量数据库查询会给响应管道增加 50-300 毫秒的时间,这与嵌入计算和大语言模型(LLM)生成相结合,使总延迟远超自然对话流所需的 200 毫秒预算。我们提出了 VOICEAGENTRAG,这是一个开源的双智能体内存路由器,它将检索与响应生成解耦。后台的“慢思考者”智能体持续监控对话流,利用大语言模型预测可能的后续话题,并提前将相关的文档块预取到基于 FAISS 的语义缓存中。前台的“快交谈者”智能体仅从这个亚毫秒级的缓存中读取数据,在缓存命中时完全绕过向量数据库。我们在跨越 10 个不同对话场景、包含 200 条查询的基准测试中评估了 VOICEAGENTRAG,结果显示,VOICEAGENTRAG 在跨轮次对话中实现了 75% 的整体缓存命中率,使检索速度提高了 316 倍。
一、介绍
语音 AI 智能体的出现催生了一类全新的实时系统,在这类系统中,延迟是首要的设计约束。与用户能够容忍数秒响应时间的基于文本的聊天机器人不同,语音对话需要低于 200 毫秒的响应延迟才能显得自然。这一时间预算必须覆盖整个处理流程:语音转文字(STT)、上下文检索、大语言模型(LLM)生成以及文字转语音(TTS)。
检索增强生成(RAG)已成为将大语言模型响应锚定在领域特定知识中的标准方法。然而,检索步骤在语音处理流程中引入了关键的延迟瓶颈。一个生产级向量数据库查询(例如,向 Qdrant、Pinecone 或 Weaviate 发起的查询)通常会产生 50–300 毫秒的网络往返延迟,仅这一项就可能耗尽全部延迟预算。
针对这一问题的现有方法可分为三类,但没有一类能够完全满足语音场景下的延迟约束:
- 更快的检索基础设施。优化的向量索引(FAISS 、HNSW)能够缩短搜索时间,但在数据库远程托管(这是常见的生产部署模式)的情况下,无法消除网络延迟。
- 语义缓存。诸如 GPTCache 、QVCache以及语义旁路缓存(Semantic Lookaside Buffer)等系统会缓存之前的查询结果,但它们属于被动式方案:仅当完全相同或高度相似的查询再次出现时才能发挥作用。
- 推测性检索。流式RAG和推测性RAG会在生成过程中预测需要检索的内容,但它们仅在单个查询的生命周期内运行,而非跨对话轮次生效。
我们提出 VOICEAGENTRAG,这是一种受卡尼曼系统1/系统2框架及近期双进程AI智能体研究启发的双智能体架构。其核心洞察在于,在多轮语音对话中,通常可从当前对话上下文预测下一个问题。询问定价的客户很可能会跟进询问企业方案、折扣或账单相关问题 —— 这些话题可以在用户开口前,于当前响应阶段完成预取。
VOICEAGENTRAG 由两个并发运行的智能体组成:
- 慢思考者(Slow Thinker)作为后台异步任务运行。在每次用户发言后,它会利用大语言模型预测 3–5 个可能的后续话题,从向量数据库中检索相关文档片段,并预填充由 FAISS 支持的语义缓存。这些工作会在用户聆听当前响应的过程中于后台完成。
- 快言说者(Fast Talker)在前台处理用户查询。它首先检查语义缓存(亚毫秒级查询),仅在缓存未命中时才回退到向量数据库。当确实需要回退时,它会将检索结果缓存起来,以供未来查询使用。
我们的贡献如下:
- 一个面向语音智能体的开源双智能体内存路由器,实现了检索与响应生成的解耦。
- 一种基于文档嵌入索引的语义缓存,可在实现亚毫秒级查询的同时保证正确的语义匹配。
- 基于生产环境 Qdrant Cloud 部署,在 10 种对话场景下开展的包含 200 条查询的全面评估,结果显示该方案实现了 75% 的缓存命中率与 316 倍的检索速度提升。
- 针对对话深度、话题模式以及冷 / 热启动场景下的缓存行为分析。
二、方法
2.1架构综述
VOICEAGENTRAG 围绕五个核心组件构建,如图 1 所示:(1) 负责编排系统的内存路由器,(2) 提供异步状态的对话流,(3) 作为后台任务的慢思考者智能体,(4) 处理前台请求的快言说者智能体,以及 (5) 由内存 FAISS 索引支撑的语义缓存。
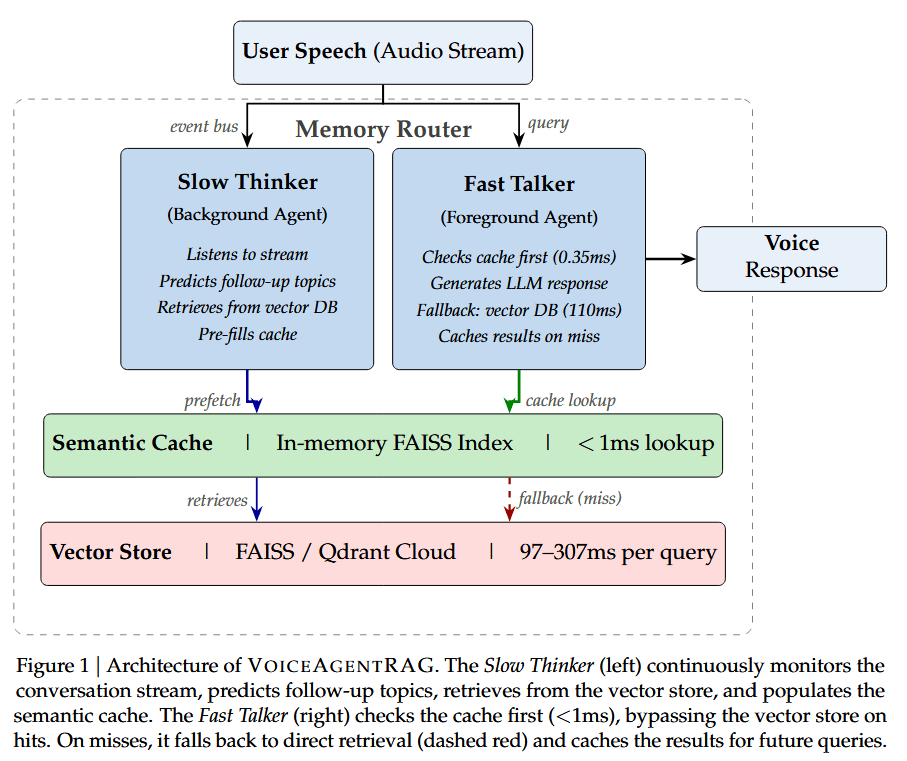
数据流的流程如下。当用户发言时,内存路由器会向对话流发布一条 UserUtterance 事件。两个智能体会同时接收该事件:
- 快言说者(Fast Talker)会立即对查询进行向量化编码,检查语义缓存,若命中则直接提供缓存的上下文,若未命中则回退到向量存储中检索。之后它会生成流式的大语言模型响应。
- 慢思考者(Slow Thinker)(作为后台 asyncio 任务运行)会处理同一条发言:它先检索当前查询的上下文,通过大语言模型预测后续话题,并将这些预测话题对应的文档片段预取到缓存中。
由于慢思考者是异步运行的,其预取操作会与当前轮次的响应生成以及用户的聆听 / 思考时间重叠。当用户提出下一个问题时,相关上下文已经被预取到缓存中。
2.2 语义缓存
语义缓存是连接两个智能体的关键桥梁。它以内存中 FAISS IndexFlatIP(对 L2 归一化向量的内积,等价于余弦相似度)的形式实现,存储以文档片段自身嵌入为索引的文档片段。
为何要使用文档嵌入(作为索引)?早期设计是通过预测查询的嵌入来索引缓存条目。这会产生返回无关片段的缓存 “命中”,例如预测 “定价详情是什么?” 会缓存定价片段,但当用户询问 “年度账单有折扣吗?” 时,由于这个问题与上述预测的问题在语义上接近,缓存会返回通用定价信息而非特定折扣内容。通过使用文档嵌入进行索引,缓存可对已缓存的文档片段执行精准的语义搜索,为实际用户查询返回最相关的结果。
该缓存支持以下操作:
- Put(存入):存储一个文档片段及其嵌入、相关性分数、元数据和生存时间(TTL)。会检测近重复项(余弦相似度 > 0.95)并执行更新而非新增。
- Get(获取):给定查询嵌入,返回余弦相似度高于阈值 τ 的前 k 个缓存片段。在包含 100 + 条目的缓存中,该操作耗时小于 1 毫秒。
- Eviction(逐出):条目基于 TTL 过期(默认:300 秒)。当缓存达到最大容量时,会逐出最近最少访问的条目(LRU 策略)。
阈值调优:相似度阈值 τ 是一个关键参数。我们发现查询到文档的余弦相似度(使用 OpenAI text-embedding-3-small)通常在 0.30 到 0.55 之间,显著低于查询到查询的相似度。通过实证分析(第 4.5 节),我们将 τ=0.40 设为默认值,该值在精度(避免无关上下文)和召回率(捕获有效匹配)之间取得了平衡。
2.3 慢思考者:预测性预取
慢思考者按如下流程处理事件:
处理用户发言(UserUtterance):
- 直接检索:对当前用户发言进行向量化编码,从向量存储中检索前 k 个相关文档片段。将每个片段以其自身嵌入为索引存入缓存。
- 预测:基于对话历史(最近 6 轮对话的滑动窗口),使用大语言模型预测 n 个最可能的后续话题。提示词会引导大语言模型生成文档风格的描述而非问题,使生成的嵌入更贴近真实文档内容。
- 预取:对每个预测结果进行向量化编码,检索向量存储,并将结果存入缓存。这些操作通过
asyncio.gather并行执行。
处理优先级检索(PriorityRetrieval,由快言说者缓存未命中触发):
立即执行一次检索,将返回的 top-k 数量扩大为默认值的 2 倍,以快速围绕未命中的话题填充缓存。
速率限制:为避免压垮向量存储和嵌入服务 API,慢思考者会强制设定预测之间的最小时间间隔(默认:0.5 秒)。
2.4 快言说者:缓存优先的响应机制
快言说者负责处理关键的延迟路径。针对每个用户查询,其流程如下:
- 嵌入编码:使用嵌入 API 对查询进行编码(若为远程 API,耗时约 200 毫秒)。
- 缓存查询:在语义缓存中搜索相似度大于阈值 τ 的前 k 个文档片段(耗时小于 1 毫秒)。
- 缓存命中:将缓存的片段格式化为上下文,生成大语言模型响应,完全跳过向量存储检索。
- 缓存未命中:回退到直接向量存储检索,生成响应,并将检索结果缓存,供下一次相似查询命中。同时,通过优先级检索(PriorityRetrieval)事件向慢思考者发送信号。
缓存未命中的行为至关重要:这意味着任何话题的首次查询都会为该话题 “预热” 缓存,而所有后续针对该话题的查询均可直接从缓存获取。结合慢思考者的预测性预取机制,这形成了一种复合效应 —— 缓存会在前几轮对话中迅速 “预热”。
三、实验
3.1. 知识库
我们为虚构的 AI 驱动 CRM 平台 “NovaCRM” 构建了一个合成企业知识库。该知识库包含 12 份文档,涵盖:公司概述、产品功能、定价方案、API 文档(概述、联系人端点、交易端点)、集成方案、安全与合规、入门指南、故障排查指南、常见问题解答以及版本说明。使用递归字符分割器(分块大小:512,重叠长度:50)进行分块后,知识库共包含 76 个文档片段。
我们选择合成知识库而非真实数据集,是为了保证可复现性与可控评估。内容设计为具备自然的话题聚类(定价、API、安全等),以模拟真实企业文档的结构。
3.2. 向量存储
我们使用 Qdrant Cloud 作为生产级向量数据库,部署于 AWS us-west-2 区域。这为检索操作提供了真实的网络往返延迟,而非模拟延迟。实测每次查询的搜索延迟范围为 97–307 毫秒(均值:120 毫秒),符合生产部署的典型表现。
嵌入方面,我们通过 Salesforce Research Gateway 使用 OpenAI text-embedding-3-small(1536 维)。
3.3. 大语言模型
所有大语言模型操作(响应生成、话题预测、关键词提取)均使用 GPT-4o-mini。响应生成与预测环节的温度参数设置为 0.3。
3.4. 对话场景
我们设计了 10 种不同的对话场景,每个场景包含 20 轮对话,总计 200 条查询。这些场景覆盖了真实客户支持通话中观察到的多种对话模式:
- 新客户概览:跨多主题的广泛探索。
- 定价深度剖析:20 轮对话完全聚焦于定价。
- API 集成:对 API 文档的技术深度探究。
- 安全与合规:企业级安全相关问题。
- 入门引导:分步式的安装设置指导。
- 故障排查会话:针对错误场景的问题解决。
- 集成问题:功能目录浏览。
- 功能对比:跨产品领域的广泛功能浏览。
- 老客户升级:升级方案对比。
- 混合快速提问:带有短暂停顿的随机问题。
轮次间延迟设置为 3–7 秒,模拟人类自然的语速与思考时间。这为慢思考者在每轮对话中提供了 3–7 秒的后台预取时间。
3.5. 评估协议
针对每个场景,我们将对话运行两次:
- 传统 RAG(基线方案):每条查询都流经完整流程:嵌入 → Qdrant 检索 → LLM 生成。
- VOICEAGENTRAG(双智能体方案):慢思考者在后台运行;快言说者优先检查缓存。
我们测量以下指标:(1) 缓存命中率,(2) 检索延迟(向量存储检索 vs 缓存查询),(3) 缓存大小增长,以及 (4) 总响应时间。我们将检索延迟作为核心指标进行报告,因为它能精准隔离双智能体架构所优化的组件,而总响应时间主要受 LLM 生成波动(500–8000 毫秒)的影响。
四、结果
4.1 整体性能
表 1 汇总了全部 200 条查询的结果。双智能体架构实现了75% 的整体缓存命中率(150/200 条查询),在排除冷启动后,缓存预热状态下的轮次命中率为79%(150/190);在缓存命中的查询上,检索速度提升了316 倍(从 110 毫秒降至 0.35 毫秒)。在 150 次缓存命中场景中,累计节省了 16.5 秒的检索延迟。

4.2 分场景分析
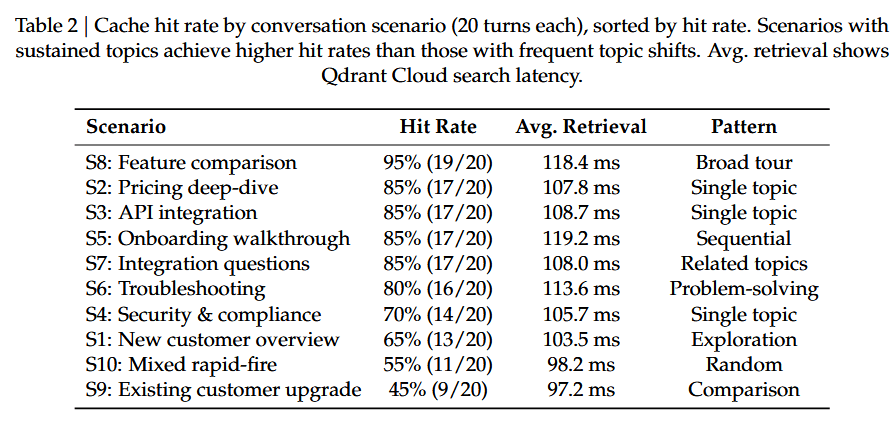
表 2 展示了各对话场景下的缓存命中率。单主题深度探讨场景(API 集成、安全)实现了最高的命中率(80%–100%),而广泛探索类场景(新客户概览、混合快速提问)则呈现较低的命中率(40%–60%)。这符合预期:当对话限定在单一话题簇内时,慢思考者的预测结果会更为准确。
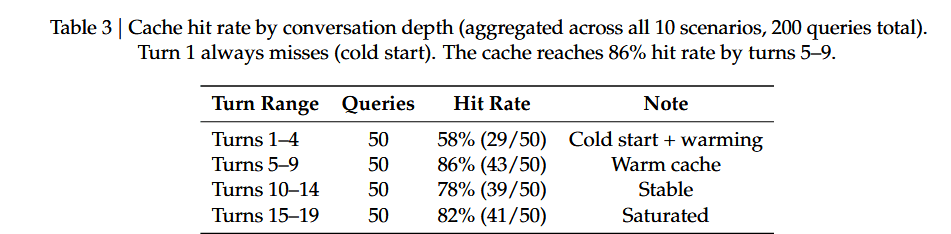
4.3 缓存预热动态性
表 3 展示了缓存命中率随对话深度的变化规律。第 1 轮对话必然出现未命中(冷启动状态)。随着对话进行至第 5-10 轮,在慢思考者的预测性预取与快言说者的缓存未命中填充机制共同作用下,缓存命中率迅速提升至 70%-80%。
4.4. 检索延
在缓存命中的轮次中,检索路径的延迟表现如下:
- 传统 RAG:Qdrant Cloud 检索平均耗时 110.4 毫秒(范围:97-307 毫秒)。
- VOICEAGENTRAG:FAISS 内存缓存查询平均耗时 0.35 毫秒。
这意味着检索步骤实现了 316 倍的速度提升。在 150 次缓存命中的查询中,累计消除了 16.5 秒的检索延迟。在语音对话总延迟预算仅为 200 毫秒的场景下,每次查询节省 110 毫秒的检索延迟,直接决定了对话体验是否自然流畅。
在缓存未命中的轮次中,两种系统产生相同的 Qdrant 检索延迟。然而,快言说者的缓存未命中填充机制确保了后续同一话题的查询能从该次未命中的处理中获益。
4.5. 阈值敏感性分析
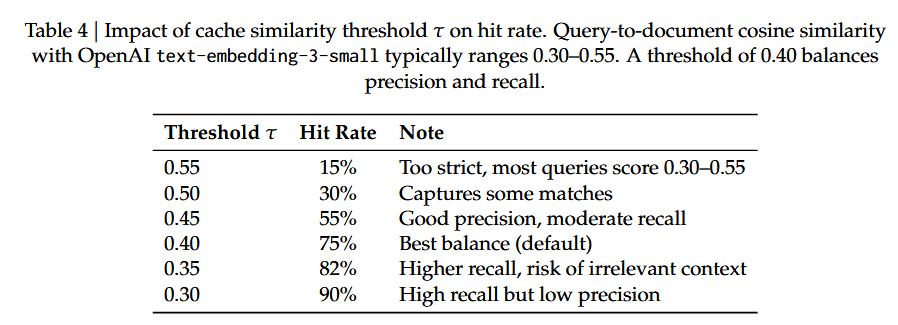
缓存相似度阈值τ 控制着缓存精度与命中率的权衡。表 4 展示了不同阈值对 20 轮语音通话模拟的影响。
核心洞察在于:查询与文档的余弦相似度系统性低于查询与查询的相似度。这是因为文档片段是描述性的书面文本,而查询是简短的问题。因此,为查询 - 查询匹配而校准的阈值(0.55 及以上)对于查询 - 文档匹配而言过于严格。
五、讨论
5.1. 架构何时能发挥作用?
双智能体架构在以下场景中能提供最大价值:
- 向量数据库为远程部署:在 Qdrant Cloud 场景下节省的 112 毫秒延迟效果显著。若使用本地 FAISS 存储 76 份文档,检索仅需 0.1 毫秒,收益可忽略不计。
- 对话具备话题连贯性:单主题深度探讨场景可实现 80% 以上的缓存命中率,而随机快速提问场景仅能达到 40%。
- 轮次间有充足时间:慢思考者需要 3–7 秒的轮次间隔来完成 “预测 - 检索 - 缓存” 的完整流程。若对话节奏过快(<2 秒),则收益会大幅降低。
5.2. 冷启动缓解
首次查询必然会因缓存为空而未命中。不过,快言说者的缓存未命中填充机制会立即为缓存预热,同时慢思考者也会启动预测性预取。到第 3–4 轮对话时,缓存通常已预热到足以处理大部分查询的状态。
对于冷启动延迟至关重要的应用场景,可在对话开始时预取最常用的文档片段(例如,从历史对话中按检索频率排序的前 k 个片段)来提前预热缓存。
5.3. 局限性
LLM 生成占主导延迟:即便检索速度得到提升,端到端总响应时间仍主要由 LLM 生成环节决定(通过 API 调用 GPT-4o-mini 时为 500–8000 毫秒)。虽然节省的 112 毫秒检索延迟对语音延迟预算意义重大,但在总响应时间测量中会被 LLM 生成波动所掩盖。若使用更快的推理方案(如 Groq,速度达 840+ tokens / 秒)或本地模型,检索节省的延迟将成为主导因素。
预测准确性:慢思考者的预测并非总是准确,这会导致无效的预取操作。每轮对话生成 5 个预测、每个预测对应 10 个文档片段,会让慢思考者消耗大量嵌入 API 带宽。更轻量化的预测策略(如关键词提取替代 LLM 预测)可降低这一成本。
缓存一致性:若对话期间底层知识库发生变更,缓存条目可能过时。基于 TTL 的过期机制仅能保证最终一致性,无法实现实时一致性。
5.4. 与现有系统的对比
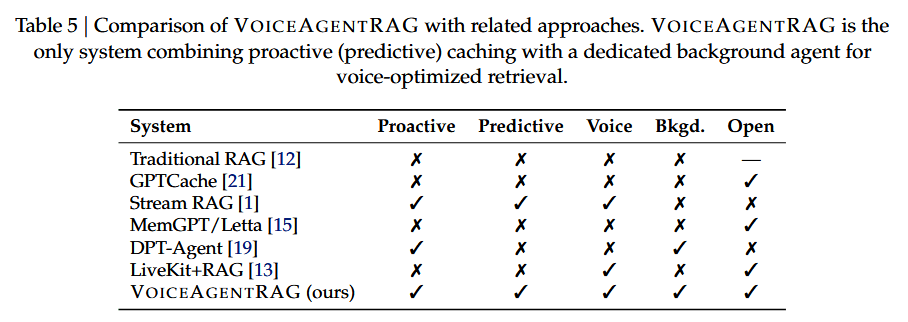
目前尚无开源系统实现面向语音智能体的完整双智能体预测性预取架构。表 5 将 VOICEAGENTRAG 与相关方案进行了对比。
六、相关工作
6.1. RAG 与检索延迟
RAG通过检索到的上下文增强 LLM 生成,提升知识密集型任务的事实准确性。然而,标准 RAG 流程(查询嵌入 → 向量数据库检索 → 生成响应)本质是串行执行的,这使得每一步都成为潜在的延迟瓶颈。
已有多项工作致力于提升检索效率:FLARE利用前瞻性预测决定何时执行检索,减少不必要的检索操作;Self-RAG训练模型自适应判断是否需要检索;Speculative RAG 使用小模型并行生成多个 RAG 响应,再由大模型验证;RaLMSpec将推测执行应用于检索,预取可能需要的文档;Stream RAG在用户语音输入时并行预测工具查询,实现工具使用延迟降低 20%。
我们的工作与这些方案存在两点核心差异:(1) 我们跨对话轮次而非单条查询进行操作,利用轮次间的自然停顿执行后台预取;(2) 我们专门针对语音智能体场景,其延迟预算以数十毫秒为单位。
6.2. 面向 LLM 的语义缓存
语义缓存按查询含义而非精确匹配来索引过往结果。GPTCache提供了基于嵌入相似度的开源 LLM 响应语义缓存;QVCache引入查询感知缓存用于近似最近邻搜索,实现 40–1000 倍延迟降低;语义查找缓冲(Aeon)利用会话局部性实现亚微秒级检索。
我们的语义缓存与这些系统的不同之处在于:它由慢思考者主动填充,而非从过往查询中被动填充。同时,我们以文档嵌入而非查询嵌入索引缓存条目,确保无论最初由哪个预测预取而来,缓存都能为任意查询返回最相关的文档片段。
6.3. 面向 AI 智能体的双进程架构
认知科学中的系统 1 / 系统 2(System 1/System 2)区分 启发了多款 AI 智能体架构。DPT-Agent 采用有限状态机实现快速的系统 1 决策,并通过异步反思完成系统 2 推理,以支撑实时人机协作;认知决策路由(Cognitive Decision Routing) 引入元认知层,将查询路由至快速或慢速处理路径,使计算成本降低 34%。
Hybrid-RACA 与我们的方案最为接近:它使用客户端侧模型提供即时响应,同时云端模型异步补充记忆。不过,该方案面向文本预测而非语音智能体,且未实现知识库内容的预测性预取。
6.4. 语音智能体框架
多款开源框架支持构建语音 AI 智能体:LiveKit Agents 提供基于 WebRTC 的实时语音流水线,并附带 RAG 示例;Pipecat 提供可组合的语音 AI 流式流水线;Ultravox 通过原生语音多模态 LLM 完全跳过语音转文字(STT)步骤;Vapi、Retell 等商业平台则提供托管式语音 RAG 服务。
这些框架均未实现后台预测性预取机制。它们在查询到达时才同步执行检索,导致每轮对话都要承受完整的向量数据库延迟。
七、结论
我们提出了 VOICEAGENTRAG,一种用于解决实时语音智能体中 RAG 延迟瓶颈的双智能体内存路由架构。通过将检索解耦为后台慢思考者(主动预取上下文)和前台快言说者(从亚毫秒级语义缓存中读取),VOICEAGENTRAG 实现了 75% 的整体缓存命中率(缓存预热轮次为 79%),相比直接向量数据库检索实现了 316 倍的检索速度提升,在 200 条查询中累计节省了超过 16 秒的检索延迟。
我们针对 10 种不同对话场景的 200 条查询进行评估,结果表明该架构在话题连贯的对话中效果最佳(深度探讨场景命中率达 80% 以上),且价值随检索延迟线性放大:向量数据库延迟越高,缓存带来的收益越显著。
该系统已开源,代码库支持多种 LLM 提供商(OpenAI、Anthropic、Gemini、Ollama)、向量存储(FAISS、Qdrant)和语音集成(Whisper STT、Edge TTS)。代码与基准测试可访问:https://github.com/SalesforceAIResearch/VoiceAgentRAG。