论文全名:CEMU: Enabling Full-System Emulation of Computational Storage Beyond Hardware Limits
摘要
计算存储驱动器(CSD)通过在固态硬盘(SSD)中实现近数据处理,为提升系统性能提供了一种极具前景的方案。然而,当前的研究平台体系分散,难以充分探索计算存储驱动器系统的完整设计空间。现有的硬件平台和仿真器平台受物理计算资源的限制,而模拟器又缺乏全系统级的保真度。为解决上述问题,我们提出了一款全新的纯软件计算存储驱动器仿真平台 CEMU,可支持全系统级的研究工作。该平台由计算存储驱动器设备仿真器和面向计算存储驱动器的软件栈两部分构成。借助创新的虚拟机冻结机制,CEMU 实现了计算存储驱动器仿真的高度可配置性:既可以利用主机中央处理器(CPU)实际执行计算,以完整还原全系统运行行为,又能对计算延迟进行独立建模,从而仿真出计算能力不受主机 CPU 限制的高性能计算存储驱动器。该软件栈的设计遵循两大原则 —— 兼容最新的计算存储驱动器行业标准、适配现有输入 / 输出(I/O)栈,并通过全新研发的 FDMFS 文件系统实现了这一设计目标。我们通过多款应用程序,以实际计算存储驱动器硬件为基准对 CEMU 的仿真保真度开展验证测试,结果表明,其端到端性能仿真的平均准确率达到 95% 及以上。我们还以大语言模型训练和 LevelDB 键值存储为对象开展了两项案例研究,以此验证 CEMU 在探索计算存储驱动器(CSD)系统研究方面的有效性,同时证明该平台能够挖掘出此前各类研究平台均未发现的关键研究洞见。
一、介绍
数据的指数级增长与人工智能技术的爆发式发展,推动业界对计算能力和能源效率的需求持续攀升。传统计算模型需要将海量数据从存储设备加载至主机进行处理,再将处理结果回写至存储设备,这类数据迁移操作会产生显著的性能开销与能耗,进而可能造成系统性能瓶颈。新兴的计算存储驱动器(CSD)采用存储内处理架构,将计算任务从主机迁移至数据所在的存储设备,从根源上消除了数据传输的开销。此外,CSD 还通过在存储控制器中以芯粒形式集成面向特定应用的硬件加速器进一步提升性能,同时支持多 CSD 部署,实现处理能力随挂载驱动器数量成比例扩展的线性可扩展性。
大量针对各类应用的研究已验证了 CSD 在性能与效率方面的优势,涉及领域包括高性能计算、数据库、数据压缩、图计算、推荐系统、机器学习,以及新兴的大语言模型和检索增强生成技术。学术界的研究热潮也带动了产业界的落地应用,三星 SmartSSD、思萃通量 ScaleFlux CSD 系列等知名商用产品相继推出,且这类产品已集成到阿里巴巴 PolarDB等大型系统中。为进一步完善 CSD 技术生态,存储网络工业协会(SNIA)和非易失性内存主机控制器接口规范(NVMe)已制定了 CSD 领域的基础架构、编程模型及应用程序接口(API)标准。
缺乏适用的研究平台,是阻碍 CSD 技术研究与推广的一大核心难题。现有研究平台主要分为硬件和软件两类,具体如表 1 所示。OpenSSD 等硬件平台能够提供完整的 CSD 系统,既包含由计算子系统和存储子系统构成的 CSD 硬件,也配备了访问该硬件的软件栈。基于硬件平台的全系统研究,可对具体的软硬件组件开展全面的验证与优化,为研究软硬件的协同运行行为提供实证分析与精细调优的条件。但硬件平台存在成本高昂的问题(如一款 SmartSSD 的单价约为 2400 美元),多 CSD 配置的部署成本则更高;同时,硬件平台的 CSD 配置受物理条件限制,无法搭建出计算能力超越该平台本身的下一代 CSD 原型。
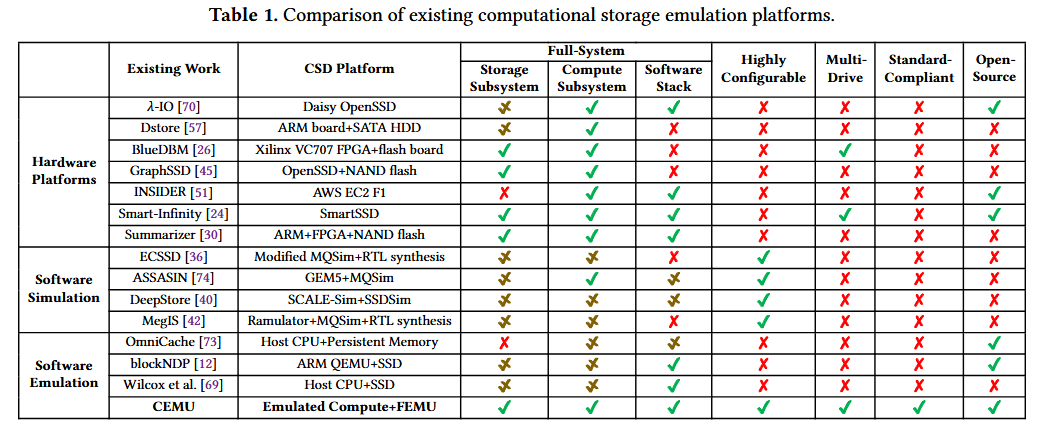
以仿真和模拟为核心的软件平台成本低廉(零成本),可在通用服务器上运行。软件仿真平台无需物理设备,能在通用服务器上对硬件进行建模,支撑全栈式研究。当建模的硬件配置未超出服务器自身能力时,仿真实现起来较为简便,例如通过添加时延模型,可利用高速动态随机存取存储器(DRAM)有效仿真低速闪存存储 。但在仿真 CSD 中的硬件加速器时,服务器中央处理器(CPU)的性能和效率会形成根本性限制,因此基于软件的 CSD 仿真,其计算能力配置始终受主机 CPU 的约束。
软件模拟平台借助寄存器传输级(RTL)综合、MQSim 仿真器等工具,对计算存储驱动器(CSD)的计算行为与输入输出(I/O)行为进行独立建模。这类平台可突破硬件限制,灵活配置 CSD 的各项参数,却不支持全系统运行,因此可能忽略关键的系统级行为与复杂交互,导致性能评估结果失真。例如,在模拟应用向 CSD 卸载计算任务的过程中,系统级页缓存等重要组件未被纳入建模范围;而我们在 6.2 节针对 LevelDB 开展的实验也发现,因缓存绕开问题,CSD 计算卸载反而出现了超出预期的性能衰减。现有基于 CSD 的压缩性能模型均假定压缩延迟为固定值,但实际测试结果显示,压缩延迟会随数据模式发生变化:在主机中央处理器(CPU)上对 4KB 数据进行 Zstd 压缩时,延迟范围为 18 微秒至 25 微秒,偏差幅度达 38.8%。此外,软件模拟方法无法与实际的软硬件进行交互,因此也不支持开展全系统的设计探索。
此外,如表 1 所示,当前的 CSD 研究平台分散于各类硬件平台与软、硬件仿真 / 模拟工具中,这种碎片化现状破坏了平台间的兼容性,导致相关研究成果难以复现,也无法与前人研究进行直接对比。同时,现有平台的编程框架均为定制化开发,与通用的 I/O 栈互不兼容。例如,λ-IO 与 INSIDER 均通过重载 Linux 系统的 pread 系统调用实现计算卸载,将计算语义与文件读取语义混置于同一接口中。
为此,我们提出了一款全新的开源 CSD 仿真平台 CEMU,旨在解决上述各类问题。该平台为纯软件实现,可零成本支撑 CSD 的全系统研究;其存储子系统基于成熟的 FEMU 固态硬盘(SSD)仿真器 构建,能实现灵活、精准的存储仿真。CEMU 重点攻克了计算子系统与软件栈两大核心难题,即 CSD 仿真的 CPU 算力受限问题与研究平台的碎片化问题。针对 CSD 计算子系统仿真的算力瓶颈,CEMU 在 QEMU 虚拟机(VM)环境中设计了创新的虚拟机冻结机制:该机制支持在主机 CPU 上执行从 CSD 卸载的计算任务,同时完整还原任务的计算行为与全系统功能;在此过程中,虚拟机内应用的运行时钟会被临时冻结,待计算任务在主机端完成后,虚拟机会经过一段可配置的延迟恢复运行。从应用层视角来看,计算任务的执行耗时极短,仿佛 CSD 搭载了性能极强的硬件加速器。由此,CEMU 可通过计算时序模型,仿真出计算能力可灵活配置的 CSD,甚至能模拟出性能超越主机 CPU、基于现场可编程门阵列(FPGA)或专用集成电路(ASIC)的硬件加速器。
针对平台碎片化的问题,CEMU 的设计遵循两大核心原则。第一,遵循存储网络工业协会(SNIA)与非易失性内存主机控制器接口规范(NVMe) 制定的 CSD 行业标准,从根源上解决平台兼容性问题;第二,保证与现有 I/O 栈的兼容性 —— 究其本质,CSD 仍属于存储设备。尽管相关行业标准已明确了 CSD 的编程模型与设备接口,但如何设计一款操作系统模块来实现这些接口,尤其是设计出兼具易用性、且能与现有 I/O 栈兼容的模块,仍是尚未解决的开放性问题。
为实现上述目标,CEMU 搭建了一套面向 CSD 的专用软件栈,其核心是全新研发的 FDMFS 文件系统。该文件系统基于存储访问中常用的文件抽象模型构建,可与将 CSD 视作普通 SSD 的传统文件系统共存;同时,它为 CSD 的设备内存管理、计算任务调度提供了易用的编程框架,并通过文件系统权限机制实现对 CSD 数据的访问控制。此外,FDMFS 还支持异步操作与 CSD 间的对等(P2P)数据传输,进一步提升系统性能。
综上,本文的核心研究贡献如下:
- 提出仿真平台 CEMU:一款全新的开源软件平台,集成了可零成本使用、且高度可配置的 CSD 仿真功能,以及兼容 CSD 行业标准与传统 POSIX I/O 栈的面向 CSD 软件栈,可实现精准的 CSD 全系统研究与多 CSD 集群研究。
- 完成平台有效性验证:基于三星 SmartSSD、思萃通量 ScaleFlux CSD2000 等实际 CSD 硬件开展对比验证,四款合成基准测试的仿真平均准确率达 95%;以大语言模型(LLM)训练与 LevelDB为对象的两项全系统案例研究表明,CEMU 具备快速构建 CSD 系统原型的能力,相关开发仅需数百行代码即可完成。
- 开展具有启发性的案例研究:借助 CEMU 探索不同 CSD 配置方案、分析全系统运行行为,挖掘出了此前各类研究平台均未发现的关键研究洞见。大语言模型训练的案例研究表明,采用多 CSD 部署或超高性能 CSD,能显著提升训练性能;但即便将 CSD 的计算能力提升数百倍,训练速度也仅能实现两倍提升,这意味着要充分发挥 CSD 的技术潜力,必须进行全系统的整体设计。LevelDB 的案例研究则揭示了 CSD 计算卸载可能引发的各类副作用,包括主机缓存绕开、CSD 内部 I/O 干扰以及 CSD 间数据传输开销等,这也提示我们,在部署 CSD 时需秉持审慎原则,并采取针对性措施管控各类潜在副作用。
二、相关工作与动机
2.1 CSD和工业标准
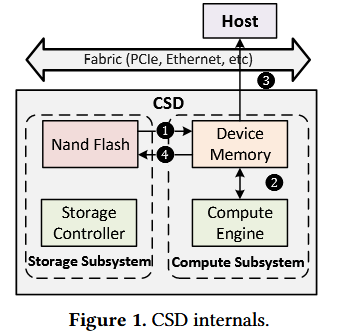
图 1 展示了计算存储驱动器(CSD)的内部架构。CSD 由两部分组成,其一为存储子系统,该子系统通常以 NAND 闪存等持久性存储介质为基础;其二为计算子系统,该子系统将计算引擎与设备内存集成于存储控制器中。两个子系统通过内部高速总线完成数据交互,从而支持将计算任务从主机卸载至 CSD 并在本地执行。
行业界已制定相应的计算存储标准,其一为存储网络工业协会(SNIA)发布的《计算存储架构与编程模型》,该标准提出了直接使用模型和间接使用模型两种编程模型;其二为非易失性内存主机控制器接口规范(NVMe)发布的《计算程序规范》,该规范将 NVMe 协议作为 CSD 的设备接口。
编程模型
如图 1 所示,在 CSD 中执行一项计算任务包含三个步骤:1)将数据从 NAND 闪存传输至设备内存❶;2)在设备内存中执行计算操作❷;3)将输出数据从设备内存读取至主机❸,或回写至 NAND 闪存❹。在直接使用模型中,上述三个步骤均由主机显式发起并调度;而在间接使用模型中,计算流程被嵌入到 I/O 请求中,主机仅需将该请求发送至 CSD,由 CSD 沿 I/O 处理流程自动完成计算。
NVMe 接口
NVMe 协议为 CSD 新增了两个命名空间,即计算命名空间和内存命名空间。其中,计算命名空间专门用于计算任务的卸载与执行,分别通过加载指令和执行指令实现该功能;内存命名空间则用于设备内存的管理,提供内存拷贝、内存读取和内存写入三大核心指令,其中内存拷贝指令可实现传统闪存存储命名空间与内存命名空间之间的高效数据传输。
2.2 现有CSD平台
表 1 总结了目前主流的基于硬件和软件的计算存储驱动器(CSD)研究平台,并从全系统支持能力、多 CSD 扩展能力、标准兼容性、开源性四个维度对这些平台进行了对比分析。
全系统支持能力
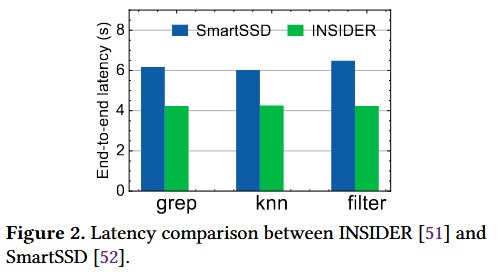
三星 SmartSSD、FPGA 开发板等实际硬件平台虽能支持 CSD 的全系统研究,但存在购置成本高、开发投入大的问题,且硬件配置固定,无法灵活探索不同的 CSD 配置方案。例如,λ-IO 基于专用硬件平台 OpenSSD(搭载老旧的 PCIe 第三代接口)开发,后续研究 OmniCache的研发团队无法获取该硬件,只能通过软件仿真的方式复现 λ-IO 的功能。INSIDER 采用赛灵思 UltraScale + 系列 FPGA 搭建 CSD 计算子系统,但该 FPGA 未集成闪存存储模块,其存储子系统是在 DRAM 中通过添加固定 I/O 延迟实现的简化仿真。由于闪存的并行架构和实际运行特性未被真实还原,仿真精度大打折扣。图 2 在三项计算任务下,对 INSIDER 与集成了同款 FPGA 的 SmartSSD 进行了性能对比,结果显示二者的端到端延迟存在显著差距,误差率达 34%。
软件仿真 / 模拟技术为探索 CSD 系统的设计空间提供了可行路径。其中软件模拟平台通过结合处理器 / 加速器模拟器(如寄存器传输级分析)作为计算子系统、固态硬盘模拟器(如 MQSim)作为存储子系统,对 CSD 的计算延迟和 I/O 延迟进行建模。但这类平台无法与实际的应用程序和硬件组件进行交互,也不涉及真实的数据处理流程,因此会忽略关键的全系统运行行为,导致端到端仿真精度降低。
尽管gem5模拟器支持全系统模式,但其设计初衷是用于微架构仿真,而非面向系统级研究。该模拟器采用单线程时钟驱动的仿真方式,运行效率极低 —— 例如对固态硬盘进行仅数十秒的行为仿真,却需要耗时五小时 。此外,blockNDP和威尔科克斯团队的 CSD 仿真器虽基于 QEMU 实现了 CSD 的全系统仿真,但仅能对 CSD 的计算卸载功能进行功能性仿真,既缺乏性能建模能力,其 CSD 计算能力的配置也受主机 CPU 的限制。与之不同的是,本文提出的 CEMU 基于主流的全栈系统研究固态硬盘仿真器 FEMU开发,并为其拓展了一款高度可配置的计算子系统(详见 3.2 节)。
此外,绝大多数现有研究平台要么未配备专用软件栈,要么采用定制化的编程框架,与当前通用的 I/O 栈互不兼容。为此,我们设计了一套面向 CSD 的专用软件栈,该软件栈既兼容行业标准,又能适配现有 I/O 栈,支持用户调用语义无偏差的 Linux 系统调用访问 CSD 的计算资源。例如,可通过copy_file_range系统调用将闪存中的数据加载至 CSD 设备内存以待处理,通过pread系统调用将 CSD 的计算结果读取至主机。
多 CSD 扩展能力
目前多数 CSD 相关研究并未开展多 CSD 系统的探索,而 Smart-Infinity和 BlueDBM 虽搭建了多 CSD 硬件平台,但存在成本高昂、可用性差的问题。其中 Smart-Infinity 基于 10 块 SmartSSD 搭建硬件平台,并配备了 PCIe 插槽扩展机箱;BlueDBM 则通过在多台服务器上集成 FPGA 和 NAND 闪存卡,实现多 CSD 的仿真。本文提出的 CEMU 可在单台通用服务器中创建多个 CSD 实例,同时通过支持 CSD 间的对等(P2P)数据传输,提升了多 CSD 系统的数据传输效率。
标准兼容性与开源性
现有所有 CSD 研究平台均未遵循存储网络工业协会(SNIA)和非易失性内存主机控制器接口规范(NVMe)的行业标准,且绝大多数平台均未开源。这导致 CSD 研究领域呈现碎片化发展态势,不仅使得前人的研究成果难以复现,也严重阻碍了该领域的研究推进。在 CEMU 的研发过程中,我们高度重视标准兼容性,同时致力于打造一款开源的通用型 CSD 仿真平台。
三、CEMU CSD
3.1 CEMU总览
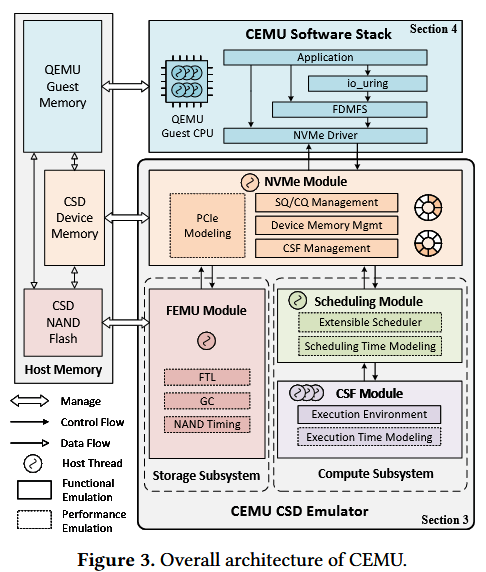
本文设计并实现了 CEMU—— 首款全系统计算存储驱动器(CSD)仿真平台,该平台集成了高可配置性的 CSD 仿真器,以及兼容 CSD 行业标准和现有 I/O 栈的面向 CSD 专用软件栈。CEMU 基于 QEMU开发,可将 CSD 仿真器作为标准 NVMe 设备挂载至客户机虚拟机中。平台整体架构如图 3 所示,其中 CSD 仿真器包含四大模块:NVMe 模块、计算存储功能(CSF)模块、调度模块和 FEMU 模块。CEMU 仿真的 CSD 对外提供三个 NVMe 命名空间,分别为传统非易失性存储器(NVM)存储命名空间、面向 CSD 的计算命名空间和内存命名空间,后两者分别用于执行计算任务与管理设备内存。
计算存储功能模块为各类计算任务提供执行环境,同时对任务的功能行为和时序模型进行仿真;调度模块负责计算任务的管理,且支持新调度算法的开发与部署。上述两大模块共同构成了 CSD 的计算子系统(详见 3.2 节)。FEMU 模块则采用业界主流的 FEMU 固态硬盘仿真器,作为 CEMU 的存储子系统(详见 3.3 节)。为实现多 CSD 部署支持,CEMU 通过新增 CSD 间的 PCIe 对等(P2P)通信功能,解决了原有 FEMU 仿真器的扩展性瓶颈问题。此外,CEMU 还内置了一套完整的 CSD 软件栈,相关设计细节将在第 4 节展开介绍。
3.2 CSD 计算子系统
3.2.1 CSF执行环境
为提升平台灵活性,支持研究人员探索各类执行环境,CEMU 提供了三种计算存储功能(CSF)类型,供研究人员将任务卸载至 CSD 中执行。(1)扩展伯克利包过滤器(eBPF)是一项革命性技术,可在特权环境中运行沙箱化程序。凭借良好的安全性与完善的工具链,eBPF 成为适用于 CSD 的极具前景的 CSF 实现形式。CEMU 通过 ubpf 在主机 CPU 上运行 eBPF 类型的 CSF 程序。(2)CEMU 支持将共享库(.so 文件)作为 CSF,以此适配操作系统及 Docker 容器执行环境,能让用户便捷地将现有应用迁移至 CEMU 仿真的 CSD 中。运行时,CEMU 借助 libdl 库在主机 CPU 上动态加载并执行共享库类型的 CSF。(3)当采用 FPGA 板卡作为 CSD 计算引擎时,CEMU 还支持比特流类型的 CSF:用户可生成实现目标 CSF 功能的比特流文件,将其下载至 FPGA 中执行即可。
3.2.2 计算性能建模
CEMU 默认可利用主机 CPU,也可在有硬件支持的情况下通过 FPGA 板卡,对卸载至 CSD 中的计算存储功能(CSF)任务进行物理执行。作为一款低成本、高可配置的 CSD 仿真器,CEMU 需支持多样化的计算能力配置,且不受主机 CPU 或 FPGA 的硬件性能限制。为此,CEMU 支持基于 CSF 任务的实际执行时间对计算耗时进行建模。我们引入计算单元(CU) 作为处理核心的抽象概念,一个计算任务在单个 CU 中运行的响应时间(Tresponse)为任务执行时间(Texec)与调度等待时间(Tsched)之和,其中Texec代表任务的实际运算耗时,Tsched代表任务在调度过程中的排队或等待耗时。
任务执行时间(Texec)建模
CEMU 为用户提供了可配置的缩放因子参数Scsf,该参数用于对任务在物理计算硬件(如主机 CPU)上的实际执行时间Thost进行缩放,计算公式为Texec=Scsf×Thost。若要仿真计算引擎性能低于物理计算硬件的 CSD(如搭载 ARM CPU 的 CSD),CEMU 可通过限制计算速度(如降低 CPU 主频)获得实际执行时间,也可通过设置Scsf>1对执行时间进行建模;反之,若要仿真计算引擎性能超越物理计算硬件的 CSD(如一款假想的 ASIC 加速器),则需将Scsf设为小于 1 以完成性能建模。若暂无实际硬件可用于校准Scsf,可借助 gem5 等成熟的周期精准模拟器对目标加速器进行建模,获取其计算能力后确定参数值,也可配置一系列缩放因子,对各类潜在的加速器进行仿真。
仿真这类高性能计算引擎存在一定技术难点,因为这要求物理计算硬件上的任务尚未完成,仿真端就要返回计算结果。为解决这一问题,CEMU 引入了虚拟机冻结机制,相关细节详见 3.2.3 节。
调度等待时间(Tsched)建模
计算任务的Tsched由调度策略决定。CEMU 内置了可插拔式调度模块,支持用户自定义实现各类调度策略,该模块提供了四大钩子函数:enqueue_job()、dequeue_job()、pick_next_job()和switched_out()。CEMU 默认实现了先进先出和轮询两种调度策略。
多计算单元(CU)配置
CEMU 支持配置多个 CU,以仿真 CSD 中的多计算引擎架构。每个 CSF 任务可绑定至指定 CU 运行,这一机制与 Linux 系统中的 CPU 核心亲和性类似。此外,单个 CU 可被配置为仿真特定类型的计算引擎,例如一个 CU 专门仿真压缩加速器,另一个 CU 则作为通用计算核心使用。在多 CU 仿真场景下,可为每个 CU 单独配置缩放因子和调度策略,实现对异构计算架构的精细化仿真控制。
设备内存管理
对于 eBPF 类型和共享库类型的 CSF 任务,CEMU 在主机 DRAM 中为其分配设备内存;而比特流类型的 CSF 任务,则直接使用 FPGA 板卡的本地内存。设备内存的各类管理操作(如分配、释放、权限控制)均由面向 CSD 的 FDMFS 文件系统完成,相关设计将在第 4 节展开阐述。
综上,CEMU 仿真的 CSD 可对计算子系统进行灵活配置,可配置项包括各 CU 的计算能力、CU 的数量、设备内存容量以及调度策略等。
3.2.3 通过虚拟机冻结实现高度可配置性
在未使用外部 FPGA 板卡的情况下,CEMU 会在主机 CPU 上执行计算存储功能(CSF)的计算任务。为仿真性能超越主机 CPU 的计算引擎,我们设计并提出了虚拟机冻结机制。在 CEMU 中,用户应用程序运行于 QEMU 虚拟机内部,而 CSD 的仿真逻辑则在主机 CPU 上执行。当输入数据加载至设备内存、CSF 任务完成初始化后,虚拟机将被暂停,此时虚拟 CPU(vCPU)及其时钟均停止运行,该计算任务会在主机 CPU 上持续执行直至完成,而这一过程的耗时在虚拟机内部无法被感知。待任务执行完毕,虚拟机恢复运行,从虚拟机的视角来看,该计算任务仿佛瞬间执行完成。基于此,CEMU 的调度器可根据任务执行时间(Texec)的建模结果(详见 3.2.2 节),添加一段停滞时间以仿真任务的实际执行耗时,相关时间线如图 4 所示。从虚拟机视角来看,任务的执行耗时为可配置的停滞时间与虚拟机暂停、恢复操作的耗时开销之和,该耗时可短于任务在主机 CPU 上的实际执行时间。
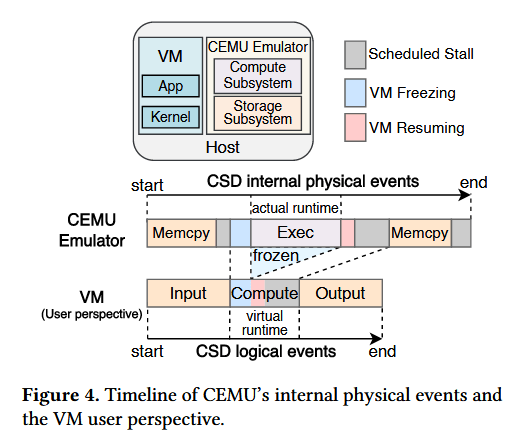
尽管虚拟机冻结机制能够隐藏计算任务的实际执行延迟,但虚拟机的暂停与恢复操作会产生虚拟机可感知的延迟开销。QEMU 处理虚拟机暂停请求的流程为:主线程首先获取 QEMU 大锁(BQL),随后停止虚拟机全局时钟,再向所有虚拟 CPU 广播暂停请求(通过 QEMU 中的pause_all_vcpus()和cpu_disable_ticks()函数实现);所有虚拟 CPU 运行至安全执行点后,确认该请求并进入休眠状态。虚拟机的恢复操作则遵循对称的控制流程:QEMU 主线程重新启用全局时钟,向所有虚拟 CPU 广播恢复请求(通过resume_all_vcpus()和cpu_enable_ticks()函数实现),各虚拟 CPU 被唤醒后,从暂停前的状态继续执行。在我们的测试服务器上,整个虚拟机暂停 - 恢复流程的延迟开销约为 21 微秒。此外,由于虚拟机全局时钟会被统一暂停,QEMU 暂不支持针对单个虚拟 CPU 的精细化冻结操作;而不同虚拟 CPU 的实际暂停节点存在微小差异并不会影响仿真的正确性和时序可观测性,因为在虚拟机时钟暂停期间,客户机内部的所有执行操作均处于停滞状态。
这 21 微秒的延迟开销,为基于虚拟机冻结机制的建模设定了任务执行时间的最小值。以输入数据量为 4MB 的计算任务为例,单个计算单元(CU)的 CSF 处理吞吐量上限为 184GB/s。若要提升吞吐量,可通过配置多个 CU 实现并行处理,同时降低虚拟机冻结的频率(例如将多个任务分组进行批处理、增大数据分块的尺寸)。若应用程序卸载的计算任务执行耗时低于 21 微秒,CSD 调度器会在每次虚拟机冻结操作中,自动将尽可能多的此类任务合并执行。
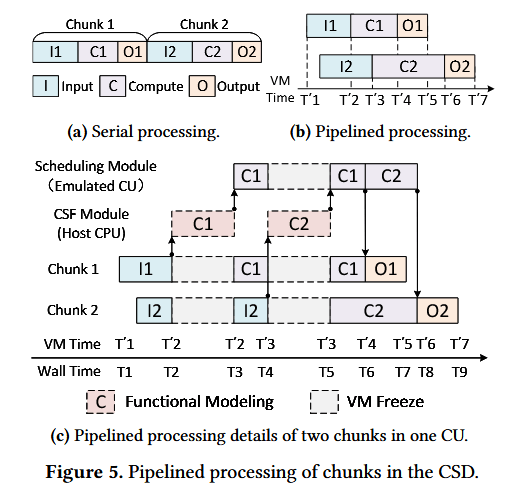
虚拟机冻结机制支持在单个 CU 中对数据分块进行流水线处理,也支持在多个 CU 或多台 CSD 中对数据分块进行并发处理。单个数据分块的处理流程包含三个阶段:数据输入、计算执行、结果输出。在串行处理模型中,数据分块在单个 CU 中被依次处理,CU 在数据输入和结果输出阶段均处于空闲状态(见图 5a)。为提升 CU 的利用率,可采用流水线方式处理数据分块,图 5b 为该方式的逻辑示意图,图 5c 则详细展示了单台 CSD 的单个 CU 中两个数据分块的流水线处理过程。该 CU 由主机 CPU 仿真实现,计算任务也在主机 CPU 上物理执行:在时间点T2′(T2),分块 1 完成数据输入,随即启动计算并冻结虚拟机;时间点T3,分块 1 的计算完成,虚拟机恢复运行。对于分块 2,其数据输入阶段在T2时刻被暂停,T3时刻恢复,T4时刻完成输入;随后虚拟机再次被冻结,至T5时刻恢复,此过程中完成分块 2 的计算。当分块 1 或分块 2 在主机 CPU 上的计算完成后,CSD 调度器会添加一段停滞时间,以仿真该计算在 CU 中的实际耗时;仿真完成后,再执行结果输出操作。若系统部署了多台 CSD,或单台 CSD 配置了多个 CU,即可实现多数据分块的并行处理 —— 例如分块 2 的计算可在另一台 CU 中仿真,并在时间点T3′(T5)立即启动。
3.3 CSD 存储子系统
3.3.1 FEMU模块
本平台采用业界主流的固态硬盘仿真器 FEMU搭建存储子系统并完成建模。FEMU 在主机内存中对具备并行架构的闪存存储进行仿真,可精准还原其实际运行特性,同时集成了闪存转换层(FTL)实现对闪存存储的管理,该模块独立线程运行,有效避免了计算子系统与存储子系统之间的资源竞争。
我们为 FEMU 新增了 PCIe 总线模型,以此为各类操作添加数据传输开销的仿真逻辑 —— 这一设计至关重要,因为近数据存储计算的核心目标之一便是减少数据传输。具体而言,该 PCIe 总线模型会对传输队列进行仿真,并根据配置的带宽参数,为每一个 I/O 请求添加经计算得出的排队延迟与传播延迟。
3.3.2 多CSD
要实现多 CSD 系统的仿真,计算子系统必须具备良好的可扩展性。CEMU 会为每一个仿真的 CSD 分配专属的 CPU 核心与内存资源,但 QEMU 在执行虚拟机暂停 / 恢复操作时需要获取大锁(BQL),这一特性会制约系统的扩展能力。为此,CEMU 采用原子引用计数的方式降低锁开销,实现了轻量级的虚拟机冻结操作。
当业务的工作集数据分布在多个 CSD 上时,跨 CSD 的数据传输开销便成为需要重点关注的问题。最直接的传输方式是依靠主机 CPU,先将数据从源 CSD 读取至主机内存,再写入目标 CSD,但该方式会占用大量主机 CPU 与内存资源,且数据传输路径过长,导致系统性能和可扩展性大幅下降。为降低这一开销,CEMU 基于 PCIe 对等(P2P)技术,实现了 CSD 之间通过 PCIe 交换机进行直接数据传输。在 CEMU 中,我们通过 PCIe 基址寄存器(BAR)将各 CSD 的设备内存进行暴露,以此完成 PCIe P2P 传输的实现;在 PCIe 枚举阶段,主机会为每个 CSD 的 BAR 地址空间分配唯一的总线地址,跨 CSD 数据传输可通过单次 P2P I/O 操作完成,只需将操作的目标地址设为远端 CSD 的 BAR 地址即可。
由于 QEMU 无法跨物理主机创建虚拟机,CEMU 的可扩展性会受限于宿主机的 CPU 与内存资源。CEMU 在主机内存中仿真闪存存储,因此所有仿真 CSD 的总存储容量和 I/O 带宽,均不能超过主机内存的对应指标。每仿真一个 CSD 会占用 4 个 CPU 核心:原生 FEMU 需 2 个核心运行固态硬盘 FTL 和 NVMe 模块,而 CEMU 新增的调度模块与 CSF 模块,还会额外占用 2 个核心(见图 3)。一般来说,服务器通常配备数百 GB 至数 TB 的内存的带宽以及数十个 CPU 核心,这些资源足以支撑 CSD 系统原型的搭建,满足研究思路验证的需求。例如,分配 32 个 CPU 核心和 800GB 主机内存,可仿真由 8 个 CSD 组成的存储阵列,且每个 CSD 可配置 100GB 的存储容量和 10GB/s 的 I/O 带宽。
CEMU 的可扩展性也可突破单台物理主机的限制,主要有三种实现方式:第一,分布式应用可在不同主机上创建多个 QEMU 实例,每个实例承载若干个 CSD,将计算任务及其数据集拆分后分配至各 CSD,实现并行处理;第二,可采用基于 CXL 或 RDMA 协议互联的远端内存 扩展主机内存容量,进而提升仿真 CSD 的总存储容量;第三,也可使用物理固态硬盘替代主机内存仿真 CSD 存储,突破主机内存的容量限制,在此种场景下,若固态硬盘的实际访问延迟超过建模的 I/O 延迟,需调度执行虚拟机冻结操作来处理对应的 I/O 请求。
四、CEMU软件栈
4.1 FDMFS的设计
面向计算存储驱动器(CSD)的软件栈需遵循行业标准、具备良好的易用性,同时还需保持与现有 I/O 栈的兼容性 —— 这是因为 CSD 本质上仍保留了固态硬盘(SSD)的存储功能。现代 I/O 栈的架构均以文件系统为核心,因此 CEMU 为 CSD 设计的软件栈,也采用文件抽象的设计思路,将计算任务的卸载、调度与执行功能融入其中,并为此研发了一款全新的面向 CSD 的专用文件系统 ——FDMFS。
设备内存是 CSD 的核心组件,例如数据处理流程中的四大操作(见图 1)均需依托设备内存完成。FDMFS 将设备内存抽象为文件,支持用户通过熟悉的文件接口对其进行管理:通过fallocate系统调用实现内存分配,通过pread/pwrite完成内存的读写操作,还可借助文件权限机制实现对设备内存数据的访问控制。4.2 节将详细说明如何通过这些系统调用,在 CSD 中完成一项计算任务的执行。
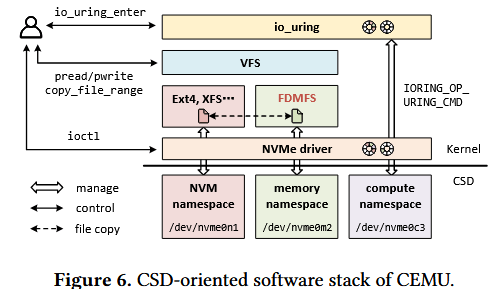
基于 FDMFS,我们搭建了一套完整的 CSD 软件栈,整体架构如图 6 所示。该软件栈的底层为经改造的 NVMe 设备驱动,可适配 NVMe《计算程序规范》的要求 —— 该标准新增了内存命名空间与计算命名空间,并定义了对应的 NVMe 指令集,包括内存读写、程序下载与执行等指令。为实现与现有 I/O 栈的集成,我们在操作系统内核中新增了一个块设备用于访问内存命名空间,同时新增一个字符设备用于访问计算命名空间;FDMFS 运行在该块设备之上,文件的创建与删除操作分别对应设备内存空间的分配与释放。
通过文件系统管理设备内存,需要对文件映射关系进行精细设计。在 ext4 这类传统的面向存储的文件系统中,文件的映射关系由离散的物理区间构成;但如果将非连续的设备内存区域映射至 FDMFS 文件,CSD 内部就必须配备内存管理单元(MMU),这会引入额外的硬件限制。为解决这一问题,CEMU 要求应用程序通过fallocate()系统调用预分配FDMFS 内存文件的目标大小,这样系统便可为文件分配并映射连续的设备内存区域。在当前的实现版本中,若要调整 FDMFS 文件映射的内存大小,需先删除原有文件再重新创建;而基于非连续内存分配机制,其实现动态的内存大小调整是完全可行的 ——NVMe CSD 标准已定义了内存范围集机制,可对多个非连续的内存区域进行描述,CEMU 未来可通过将 FDMFS 文件映射至内存范围集,再通过动态添加或移除内存范围的方式实现内存动态扩容,这一功能拓展将作为后续的研究工作。

针对计算命名空间,CEMU 通过ioctl系统调用来实现计算存储功能(CSF)任务的下载与执行,图 7 展示了不同使用模型下各类系统调用的应用示例(下一节将详细介绍相关模型)。借助计算命名空间,CEMU 可将计算任务当作普通 I/O 任务进行管理,同时还能复用 io_uring 等现有 I/O 栈组件完成任务调度,大幅降低了开发与使用成本。
4.2 标准编程模型
CEMU 软件栈支持由存储网络工业协会(SNIA)标准化的两种 CSD 编程模型,即直接使用模型与间接使用模型。
直接使用模型
在该模型下,计算任务的完整执行流程均由主机显式控制,包括数据输入、计算执行以及结果输出全环节。
用户需先创建 FDMFS 文件,为任务执行分配对应的设备内存输入、输出空间;随后将数据从普通数据文件(如 ext4 文件)传输至输入内存文件。若简单通过对数据文件执行pread、再对内存文件执行pwrite的方式完成传输,数据会经过主机中转,传输效率极低。为解决这一问题,CEMU 采用 Linux 系统的copy_file_range系统调用,该调用可实现文件间的直接数据拷贝,避免内核空间与用户空间之间的上下文切换和数据拷贝开销。结合 FDMFS 的设计,CEMU 可通过copy_file_range实现驱动器内部闪存与设备内存间的直接数据传输,全程无需主机介入。具体而言,FDMFS 接收到copy_file_range调用后,会先获取数据文件的映射关系与内存文件的内存区间信息,再向 CSD 下发 NVMe 内存拷贝指令完成传输。
用户向计算命名空间提交ioctl请求,即可触发计算任务执行。计算完成后,结果会暂存于输出内存文件中,后续可通过copy_file_range()将结果回写至闪存中的数据文件,也可通过对输出内存文件执行pread将结果读取至主机。图 7a 给出了直接使用模型的代码示例,演示了如何在 CSD 中实现计算任务卸载、输入数据读取、任务执行与输出数据读取的全流程。此外,将该示例中第九行的nvm_fd和in_fd分别指向源 CSD 和目标 CSD 的对应文件,即可通过copy_file_range实现 CSD 间的对等(P2P)数据传输。
间接使用模型
在该模型下,主机仅需通过ioctl系统调用向 CSD 提交计算请求(见图 7b),后续的全流程任务执行均由 CSD 固件自主管理。因此,间接使用模型可有效避免主机与 CSD 之间频繁的通信和同步操作。
两种使用模型的对比
直接使用模型是主机中心化的设计,CSD 中计算任务的每一个执行步骤均由主机发起,适用于输入数据分散在多个文件中、或任务执行依赖其他任务输出结果的复杂业务场景。与之相反,间接使用模型是设备中心化的设计,由 CSD 自主完成卸载计算任务的全流程执行,该模型既避免了主机与 CSD 间的频繁交互同步,也大幅简化了应用程序的开发流程。
异步操作
由于 CEMU 软件栈与现有 I/O 栈深度集成,设备内存操作和计算任务执行均可借助当下的异步 I/O 框架提升性能。在 CEMU 中,我们基于 io_uring实现了 CSD 三个命名空间的全异步操作:在直接使用模型下,主机程序需显式管理各操作间的同步关系,例如需等待将数据加载至设备内存的读指令执行完成后,再提交计算指令;而在间接使用模型下,各操作的调度与同步均由 CSD 固件负责完成。
五、评估
本节对 CEMU 开展全面的性能评估,评估内容包括硬件保真度验证、软件栈性能分析、系统可扩展性测试,以及基于大语言模型训练和 LevelDB 键值存储的全系统案例研究。
5.1 实验配置
CEMU 基于 QEMU 8.0.0 与 Linux 6.8 内核开发实现。其中仿真器模块以 FEMU 代码库为基础进行开发,新增了对驱动器内部计算子系统的功能建模与性能建模;软件栈则集成于 Linux 内核中,对 NVMe 驱动、FDMFS 文件系统以及 io_uring 中的 IORING_OP_COPY_FILE_RANGE 操作均做了相应适配修改。CEMU 的整体实现代码量约 1.1万行,其中基于 QEMU 开发的代码为 8000 行,内核端开发代码为 3000 行。
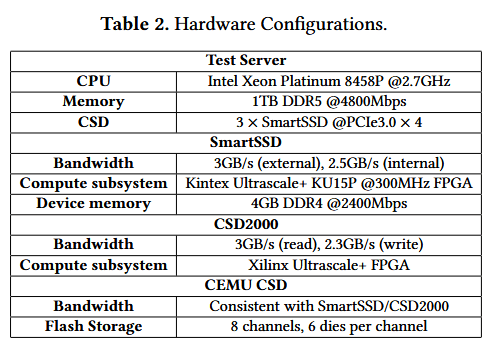
本次实验采用工业级 CSD 硬件平台完成 CEMU 的保真度验证,具体包括三星 SmartSSD 与思萃通量 ScaleFlux CSD2000。测试服务器、CEMU 仿真 CSD 的配置参数,以及两款工业级 CSD 的核心参数均如表 2 所示。
后续
略