前置知识
Valgrind
Valgrind 内存跟踪文件是由 Linux 工具 Valgrind 生成的文本文件,记录程序执行过程中所有内存访问的详细轨迹,用于缓存模拟器等工具分析内存操作行为。
例如,通过 Valgrind 的lackey工具捕获目标程序的内存访问,命令格式固定:valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes 目标程序。例如运行ls -l时,该命令会捕获其所有内存访问并输出到标准输出,保存后即为跟踪文件。
每一行对应一次或两次内存访问,格式为「[空格]操作 地址,大小」,具体规则如下:
- 操作字段:“I” 表示指令加载(无前置空格),“L” 数据加载、“S” 数据存储、“M” 数据修改(均有前置空格,“M” 等价于加载 + 存储)。
- 地址字段:64 位十六进制内存地址,如
0421c7f0。 - 大小字段:访问的字节数,如
4表示 4 字节访问。
用途:用于复现程序的内存访问行为,从而作为缓存模拟器的输入数据,统计缓存命中、缺失和驱逐次数
高速缓存存储器
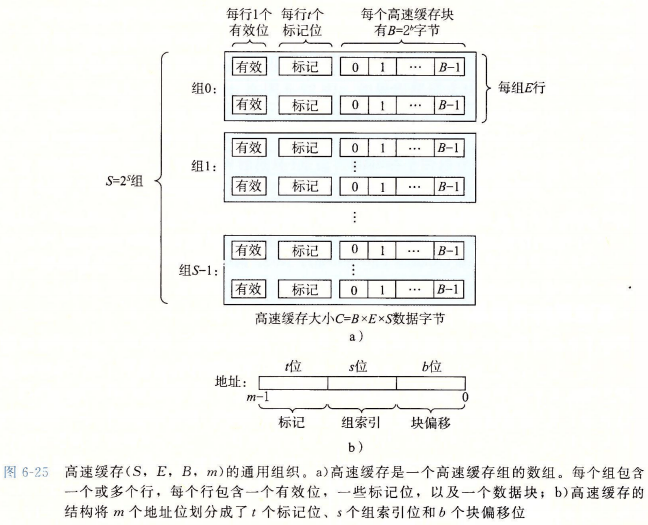
高速缓存被组织成一个S组的数组,由三个参数定义:
- S:组数;高速缓存中组的数量
- E:每组行数;每个组中行的数量
- B:块大小;每行中数据块的大小
其它说明
• 缓存行(Cache Line): 每个行包含一个有效位(valid bit)、t 位的标记(tag)以及一个 B 字节的数据块。
• 有效位: 指示该行中的数据块是否包含有效的主存数据。
• 标记位: 用于唯一标识存储在该行中的数据块来自哪个主存地址。
组相联映射
这种缓存每个组都保存有多于一个的告诉缓存行,一个1<E<C/B的高速缓存通常称为E路组相联高速缓存:
组相联高速缓存中的组选择
在这一步中,高速缓存从w的地址中间抽取出s个组索引位,与直接映射一样,如图,此时的组索引位就是1
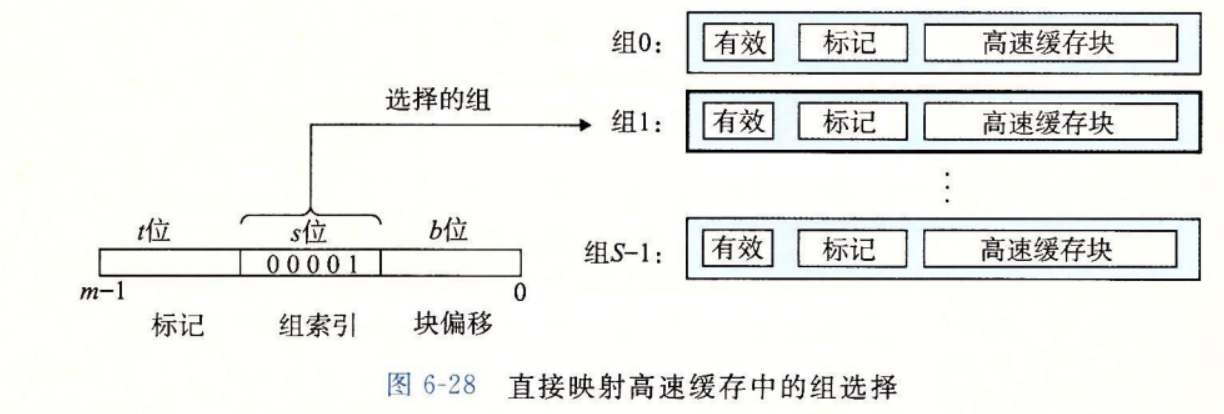
组相联高速缓存中的行匹配和字选择
它必须检查多个行的标记位和有效位,以确定所请求的字是否在集合中。图6-34展示了这个过程
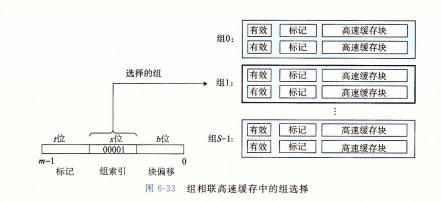
组相联高速缓存中不命中时的行替换
如果该组中没有空行,那么需要利用替换策略,利用局部性原理,可以使用最不常使用LFU策略或者最近最少使用LRU策略进行替换。、
PartA
本次实验的目的就是写一个简单的缓存模拟器,并将上述valgrind产生的包含内存行为(加载、存储、改变)跟踪文件作为输入,判断缓存的命中、不命中、替换的次数是否符合预期
完整代码及注释如下所示(来源:https://arthals.ink/blog/cache-lab#%E6%88%90%E5%93%81%E4%BB%A3%E7%A0%81)
#include "cachelab.h"
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
struct line
{
int valid; // 有效位
int tag; // 标记
int last_used_time; // 最后使用时间,用于LRU替换策略
};
// 定义组,每组有E行,一行有一块
typedef struct line *set;
// 定义缓存,有S个组
set *cache;
// 定义全局缓存参数
int v = 0; // 可选的详细信息标志,用于显示跟踪信息
int s; // 缓存的组数为S=2^s
int E; // 缓存每组的行数
int b; // 每个高速缓存块的有B=2^b个字节
int timestamp = 0; // 时间戳,记录当前时间
// 定义全局返回参数
unsigned hit = 0; // 命中数
unsigned miss = 0; // 未命中数
unsigned eviction = 0; // 替换数
// 打印使用说明
void printUsage()
{
puts("Usage: ./csim [-hv] -s <num> -E <num> -b <num> -t <file>");
puts("Options:");
puts(" -h Print this help message.");
puts(" -v Optional verbose flag.");
puts(" -s <num> Number of set index bits.");
puts(" -E <num> Number of lines per set.");
puts(" -b <num> Number of block offset bits.");
puts(" -t <file> Trace file.");
puts("");
puts("Examples:");
puts(" linux> ./csim -s 4 -E 1 -b 4 -t traces/yi.trace");
puts(" linux> ./csim -v -s 8 -E 2 -b 4 -t traces/yi.trace");
}
// 访问缓存
void useCache(size_t address, int is_modify)
{
int set_pos = address >> b & ((1 << s) - 1);
int tag = address >> (b + s);
set cur_set = cache[set_pos];
int lru_pos = 0, lru_time = cur_set[0].last_used_time;
for (int i = 0; i < E; i++)
{
if (cur_set[i].tag == tag)
{
++hit;
// 如果是修改操作还需要增加一次命中,因为既有读又有写
hit += is_modify;
cur_set[i].last_used_time = timestamp;
if (v)
{
printf("hit\n");
}
return;
}
if (cur_set[i].last_used_time < lru_time)
{
lru_time = cur_set[i].last_used_time;
lru_pos = i;
}
}
miss++;
// 如果是修改操作,必有一次写的命中
hit += is_modify;
// 如果lru_time != -1,说明当前缓存已满,需要驱逐
eviction += (lru_time != -1);
if (v)
{
if (lru_time != -1)
{
if (is_modify)
printf("miss eviction hit\n");
else
printf("miss eviction\n");
}
else
{
printf("miss\n");
}
}
// 驱逐
cur_set[lru_pos].last_used_time = timestamp;
cur_set[lru_pos].tag = tag;
return;
}
int main(int argc, char *argv[])
{
int option;
FILE *trace_file;
if (argc == 1)
{
printUsage();
exit(0);
}
// 读取参数
while ((option = getopt(argc, argv, "hvs:E:b:t:")) != -1)
{
switch (option)
{
case 'h':
printUsage();
exit(0);
break;
case 'v':
v = 1;
break;
case 's':
s = atoi(optarg);
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
trace_file = fopen(optarg, "r");
break;
default:
printUsage();
exit(0);
}
}
// 注意这里内存地址是64位的,而地址格式为:(Tag, Set Index, Block Offset)这三个加起来要等于64,所以s + b不能超过64
if (s <= 0 || E <= 0 || b <= 0 || s + b > 64 || trace_file == NULL)
{
printUsage();
exit(1);
}
// 初始化缓存
cache = (set *)malloc(sizeof(set) * (1 << s));
for (int i = 0; i < (1 << s); i++)
{
cache[i] = (set)malloc(sizeof(struct line) * E);
for (int j = 0; j < E; j++)
{
cache[i][j].valid = -1;
cache[i][j].tag = -1;
cache[i][j].last_used_time = -1;
}
}
// 解析trace文件
int size;
char operation;
size_t address; // size_t大小与系统有关
// %lx:读取无符号十六进制整数
while (fscanf(trace_file, "%s %lx,%d", &operation, &address, &size) == 3)
{
++timestamp;
if (v)
{
printf("%c %lx,%d", operation, address, size);
}
switch (operation)
{
case 'I':
continue;
case 'M': // Modify = Load + Store
useCache(address, 1);
break;
case 'L':
case 'S':
useCache(address, 0);
}
}
free(cache);
printSummary(hit, miss, eviction);
return 0;
}PartB
参考:https://zhuanlan.zhihu.com/p/484657229
利用gdb,可以知道A和B数组的地址分别为:0x40a0和0x440a0,这属于虚拟地址
接下来我们分析如何在s=5、E=1、b=5的情况下,从虚拟地址得出组索引,虚拟地址可以看成是虚拟页号+页内偏移量,页内偏移的位数(假设a位)一般大于等于索引位数+块偏移位数(假设工b位),即a>=b,因此可以直接通过虚拟地址的后b位得出组索引和块偏移。而标记不能从虚拟地址中获取,而且从用户的视角也没必要获取
对A进行缓存位置的分析:
A:010000 00110 00000 组索引:6,块偏移:0
A[0][1]: 010000 00110 00100 组索引:6,块偏移:4
...
A[0][8]: 010000 00111 00000 组索引:7,快偏移:0
可以发现B对应位置的组索引和块偏移与A是完全相同的
此外,还需要理解一个机制:首先由于b=5,一个缓存组可以存放32字节,也就是可以存储8个int,当我们用“行优先”对矩阵元素进行访问时,每读取一个元素就会将这个元素以及后面的8个int放入缓存中(因为块是缓存读写的最小单位)(这也解释了遍历的时候为什么行优先优于列优先)
如果使用常规转置方案:
void trans_submit(int M, int N, int A[N][M], int B[M][N]) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
int tmp = A[i][j];
B[j][i] = tmp;
}
}
}这里我们会按行优先读取 A 矩阵,然后一列一列地写入 B 矩阵,以第1行为例,在从内存读 A[0][0] 的时候,除了 A[0][0] 被加载到缓存中,它之后的 A[0][1]---A[0][7] 也会被加载进缓存。
但是内容写入 B 矩阵的时候是一列一列地写入,在列上相邻的元素不在一个内存块上,这样每次写入都不命中缓存。并且一列写完之后再返回,原来的缓存可能被覆盖了,这样就又会不命中,我们来定量分析。
缓存只够存储一个矩阵的四分之一,A中的元素对应的缓存行每隔8行就会重复。A和B的地址根据之前的分析,每个元素对应的缓存地址是相同的.
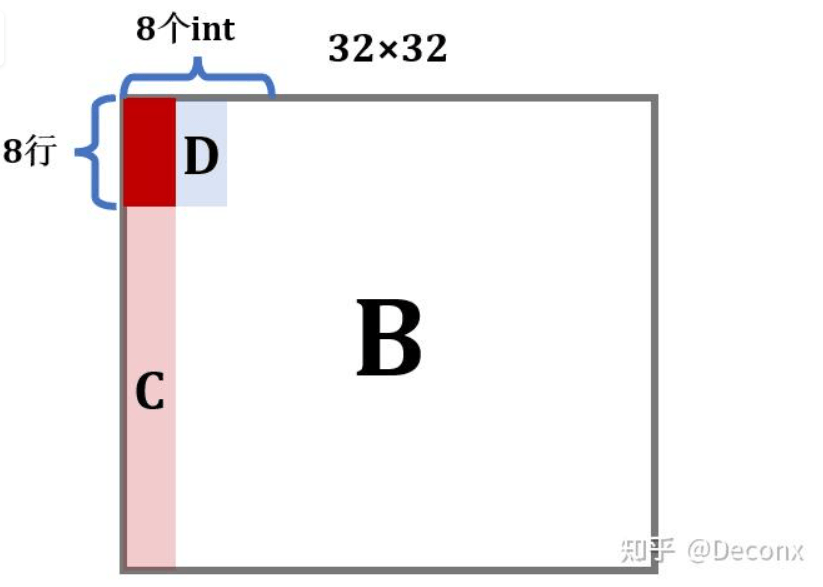
在写入B的前 8 行后,B的D区域就全部进入了缓存,此时如果能对D进行操作,那么就能利用上缓存的内容,不会miss;但是,暴力解法接下来操作的是C,每一个元素的写都要驱逐之前的缓存区,当来到第 2 列继续写D时,它对应的缓存行很可能已经被驱逐了,于是又要miss,也就是说,暴力解法的问题在于没有充分利用上已经进入缓存的元素。
分块解决的就是同一个矩阵内部缓存块相互替换的问题。
由上述分析,显然应考虑 8 × 8 分块,这样在块的内部不会冲突,接下来判断A与B之间会不会冲突
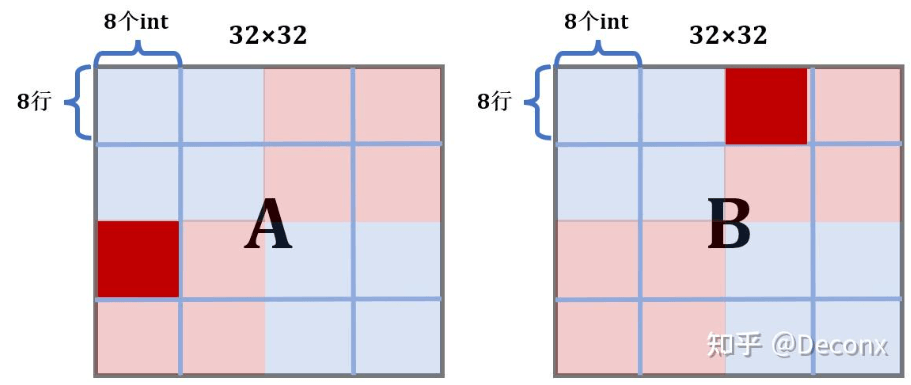
A中标红的块占用的是缓存组与B中标红的块占用的是缓存组不会冲突。事实上,除了对角线,A与B中对应的块都不会冲突。所以,我们的想法是可行的,写出代码:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
for (int i = 0; i < N; i += 8)
for (int j = 0; j < M; j += 8)
for (int k = 0; k < 8; k++)
for (int s = 0; s < 8; s++)
B[j + s][i + k] = A[i + k][j + s];
}对于A中每一个操作块,只有每一行的第一个元素会不命中,所以为8次不命中;对于B中每一个操作块,只有每一列的第一个元素会不命中,所以也为 8 次不命中。总共miss次数为:8 × 16 × 2 = 256
但实际上经过测试发现miss:343,这是因为A与B对角线上的块在缓存中对应的位置是相同的,而它们在转置过程中位置不变,所以复制过程中会发生相互冲突。以A的一个对角线块p,B与p相应的对角线块q为例,复制前, p 在缓存中。 复制时,q会驱逐p。 下一个开始复制 p 又被重新加载进入缓存驱逐 q,这样就会多产生两次miss。考虑使用 8 个本地变量一次性存下 A 的一行后,再复制给 B,代码如下:
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
for(int i = 0; i < 32; i += 8)
for(int j = 0; j < 32; j += 8)
for (int k = i; k < i + 8; k++)
{
int a_0 = A[k][j];
int a_1 = A[k][j+1];
int a_2 = A[k][j+2];
int a_3 = A[k][j+3];
int a_4 = A[k][j+4];
int a_5 = A[k][j+5];
int a_6 = A[k][j+6];
int a_7 = A[k][j+7];
B[j][k] = a_0;
B[j+1][k] = a_1;
B[j+2][k] = a_2;
B[j+3][k] = a_3;
B[j+4][k] = a_4;
B[j+5][k] = a_5;
B[j+6][k] = a_6;
B[j+7][k] = a_7;
}
}对于非对角线上的块,本身就没有额外的冲突;对于对角线上的块,写入A每一行的第一个元素后,这一行的元素都进入了缓存,我们就立即用本地变量存下这 8 个元素,随后再复制给B。这样,就避免了第一个元素复制时,B把A的缓冲行驱逐,导致没有利用上A的缓冲。