在很多情况下,让程序运行得快也是一个重要的考虑因素,编写高效程序需要做到以下几点:第一、我们必须选择一组适当的算法和数据结构。第二、我们必须编写出编译器能够有效优化以转换成高效可执行代码的源代码。对于第二点,理解优化编译器的能力和局限性是很重要的,编写程序方式看上去只是一点小小的变动,都会引起编译器优化方式很大的变化。
5.1 优化编译器的能力和局限性
大多数编译器包括GCC,向用户提供了一些对它们所使用的优化的控制,最简单的控制就是指定优化级别,例如,以命令行选项"-Og"调用GCC是让GCC使用一组基本的优化,以选项"-O1"或更高(如"-O2"或"-O3")调用GCC会让它使用更大量的优化。这样做可以进一步提高程序的性能,但是也可能增加程序的规模。
编译器必须很小心地对程序只使用安全的优化,也就是说对于程序可能遇到的所有可能的情况,优化前后有一样的行为,让我们来看看下面这两个过程:

这两个过程似乎有相同的行为,而twiddle2效率更高一些,它只要求3次内存引用,而twiddle1需要6次,不过当xp == yp时,twiddle1会让xp指向的值增加4倍,而twiddle2仅让xp指向的值增加3倍。这种两个指针可能指向同一个内存位置的情况称为内存别名使用,这造成了一个主要的妨碍优化的因素,也是可能严重限制编译器产生优化代码机会的程序的一个方面,如果编译器不能确定两个指针是否指向同一个位置,就必须假设什么情况都有可能,这就限制了可能的优化策略。
第二个妨碍优化的因素是函数调用,考虑下面这两个过程:

看上去两个过程计算的都是相同的结果,但是考虑f函数的代码如下:

这个函数有个副作用——它修改了全局程序状态的一部分,改变调用它的次数会改变程序的行为。大多数编译器不会试图判断一个函数是否没有副作用,如果没有,就可以被优化成像func2中的样子。然而,编译器会假设最糟的情况,因此保持所有的函数调用不变。
在各种编译器中,就优化能力来说,GCC被认为是胜任的,但是并不是特别突出,它能完成基本的优化,但是不会对程序进行更加激进的变换,因此,使用GCC的程序员必须花费更多的精力,以一种简化编译器生成高效代码的任务的方式来编写程序。
5.2 表示程序性能
我们引入度量标准每元素的周期数(Cycles Per Element,CPE) ,作为一种表示程序性能并指导我们改进代码的方法。处理器活动的顺序是由时钟控制的,时钟提供了某个频率的规律信号,通常用千兆赫兹(GHz),即十亿周期每秒来表示。
许多过程含有一组元素上迭代的循环,例如图5-1中的函数psum1和psum2计算的都是一个长度为n的向量的前置和。对于向量a,前置和p定义为:
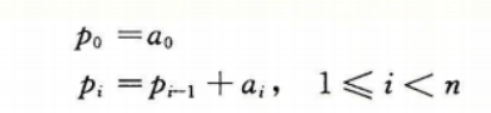

函数psum1每次迭代计算结果向量的一个元素,第二个函数使用循环展开的技术,每次迭代计算两个元素,本章后面会探讨循环展开的好处。
5.3 程序示例
为了说明一个抽象的程序是如何被系统地转换成更有效的代码的,我们将使用一个基于图5-3所示的向量数据结构的运行示例。向量由两个内存块表示:头部和数据数组,头部是一个声明为如下的结构:
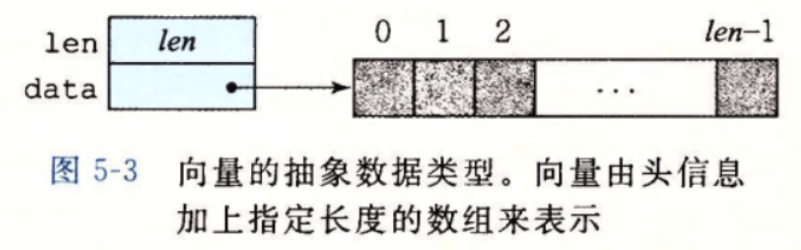

对于上述的数据结构,我们给出一个生成向量的函数:vec_ptr new_vec(long len)、一个访问向量元素的函数:int get_vec_element(vec_ptr v, long index, data_t *dest)、这个程序会对每个向量引用进行边界检查,边界检查降低了程序出错的机会,但同样也会减缓程序的执行。
图5-5所示的代码使用某种运算,将一个向量中所有的元素合并成一个值:

接下来,我们会对这个代码进行一系列的变化,得到这个合并函数的不同版本,通过测量CPE来评估性能,首先是未优化的和抽象的-O1的结果:

5.3.1 消除循环的低效率
图5-6是一个修改了的版本,称为combine2,它在开始时调用vec_length,并将结果赋值给局部变量length。

这个优化是一类常见的优化的一个例子,称为代码移动,这类优化包括识别要执行多次但是计算结果不会改变的计算。因而可以将计算移动到代码前面不会被多次求值的部分。然而编译器不知道一个函数是否会有副作用,因此为了改进代码,程序员必须经常帮助编译器显式地完成代码的移动。
5.3.2 减少过程调用
以combine2代码为例,其循环迭代调用get_vec_element函数获取向量元素时,因要做边界检查导致效率低,不过经分析该代码所有引用合法;因此提出替代方法,通过增加get_vec_start函数获取数组起始地址,进而写出无函数调用、直接访问数组的combine3过程,虽然这种变换可能损害程序模块性,但有些程序员认为这是获得高性能结果的必要步骤。

我们发现修改之后性能没有明显的提升,实际上,整数求和的性能还略有下降,这个原因在于内循环中的其他操作形成了瓶颈,限制性能超过调用get_vec_element
5.3.3 消除不必要的内存引用
在分析 combine3 函数的内部循环生成的汇编代码时,特别是针对 double 类型和乘法运算进行计算时,可以观察到一个关键的性能瓶颈:
- 冗余的内存读写:计算的累积值被指令不断地写入由
dest指向的内存位置。 - 循环内部操作:在每次迭代中,累积计算的结果都存储在寄存器
%xmm0中,然后通过vmovsd %xmm0, (%rax)(假设%rax包含dest的地址)写回到内存。在下一次迭代开始时,程序又会从内存中读回这个值,用于新的计算。
解决方案:使用累加变量
为了解决这种低效率,优化方法是消除不必要的内存引用。
程序员应当在循环内部使用一个累加变量(accumulator variable),该变量通常存储在处理器寄存器中。
• 实现机制:将累积计算的结果一直保存在这个本地(临时)变量中,直到循环完成。
• 最终写回:只有在循环结束时,才需要将最终的累积结果写回到dest。

5.4 理解现代处理器
现代处理器的性能优化不仅依赖于目标机器的任何特性,还依赖于对流水线处理器结构的理解。优化需要深刻理解机器的基本限制,并生成能够最大限度地在功能单元上实现并行执行的代码。
现代处理器的复杂性与执行机制:
- 现代处理器采用了乱序执行 (out-of-order execution) 的技术:指令执行的顺序不一定要与它们在机器级程序中的顺序一致。
- 处理器的成功关键在于动态调度 (dynamic scheduling),它按顺序接收指令,但可以在乱序中执行操作。
- 虽然程序在汇编代码中看起来是按顺序执行的,但处理器在执行层面采取了许多步骤来实现并行。
- 程序性能的限制由两个基本因素决定:延迟界限 (latency bound) 和吞吐量界限 (throughput bound)。
现代处理器(如 Intel 处理器)的结构通常包含两个主要部分:指令控制单元(ICU) 和执行单元(EU) 。
- 指令控制单元 (ICU):
- ICU负责从内存(指令高速缓存)中读取指令。
- ICU将复杂的指令序列转换成一系列更小的基本操作(微操作)。
- ICU 通过分支预测 (branch prediction) 技术来处理控制流(分支)。如果预测错误,将需要“冲刷”(刷新流水线),导致性能损失。
- 退役单元 (retirement unit) 是ICU的一部分,它维护程序寄存器状态的正确顺序。
- 执行单元 (EU):
- EU 接收 ICU 生成的微操作,并将它们分配给不同的功能单元来执行。
- 功能单元是执行特定操作的硬件资源,例如整数运算、浮点/向量运算、加载和存储。
- EU使用高速缓存 (data cache) 读取内存数据,加载和存储单元通过高速缓存与内存进行通信。
5.5 循环展开
循环展开(Loop Unrolling)是一种重要的程序优化技术,旨在提高循环执行效率,并允许处理器实现更高程度的指令级并行性。
它通过增加每次迭代处理的元素数量,来达到优化目的:
• 减少循环开销: 减少了整个循环执行所需的迭代次数,从而减少了索引增加和条件判断(比较和跳转)的循环控制开销。
• 增加指令数量: 允许在内层循环中执行更多的操作,为处理器提供了更多的指令,从而增加了乱序执行(out-of-order execution)和功能单元并行的机会。
• 优化关键路径: 可以减少限制性能的关键路径上的操作数量。
单累加变量是最简单的循环展开形式,其中k个元素在一次迭代中被处理,但所有中间结果都累积在同一个累加变量(accumulator, acc)中。这种展开形式可以有效地降低循环开销,从而提高吞吐量界限附近的性能,然而:这种k×1 展开不能突破延迟界限。由于累加操作(例如乘法或加法)仍存在数据相关性(当前迭代的计算依赖于前一次迭代的 acc 值),关键路径的长度并未改变。性能仍然受限于操作的延迟。
为了克服单累加变量带来的延迟限制,需要结合使用循环展开和多累加变量(Multiple Accumulators)的技术。这被称为 k×k 循环展开(或 k 路并行)。将 k 个独立的累加变量用于 k 值的累积。例如,2×2 展开(combine6)将奇数和偶数元素分别累积到两个独立的变量 (acc0 和 acc1) 中。
在某些情况下,为了充分发挥 k×k 展开的优势,还需要进行重新结合变换(reassociation transformation)。比如将acc = (acc OP data[i]) OP data[i+1]写成acc = acc OP (data[i] OP data[i+1]),重新结合变换旨在打破限制性能的关键路径上的数据相关性,从而提高并行操作的数量。