原文章链接:https://docs.nvidia.com/cuda/cuda-programming-guide/
编程模型
异构系统
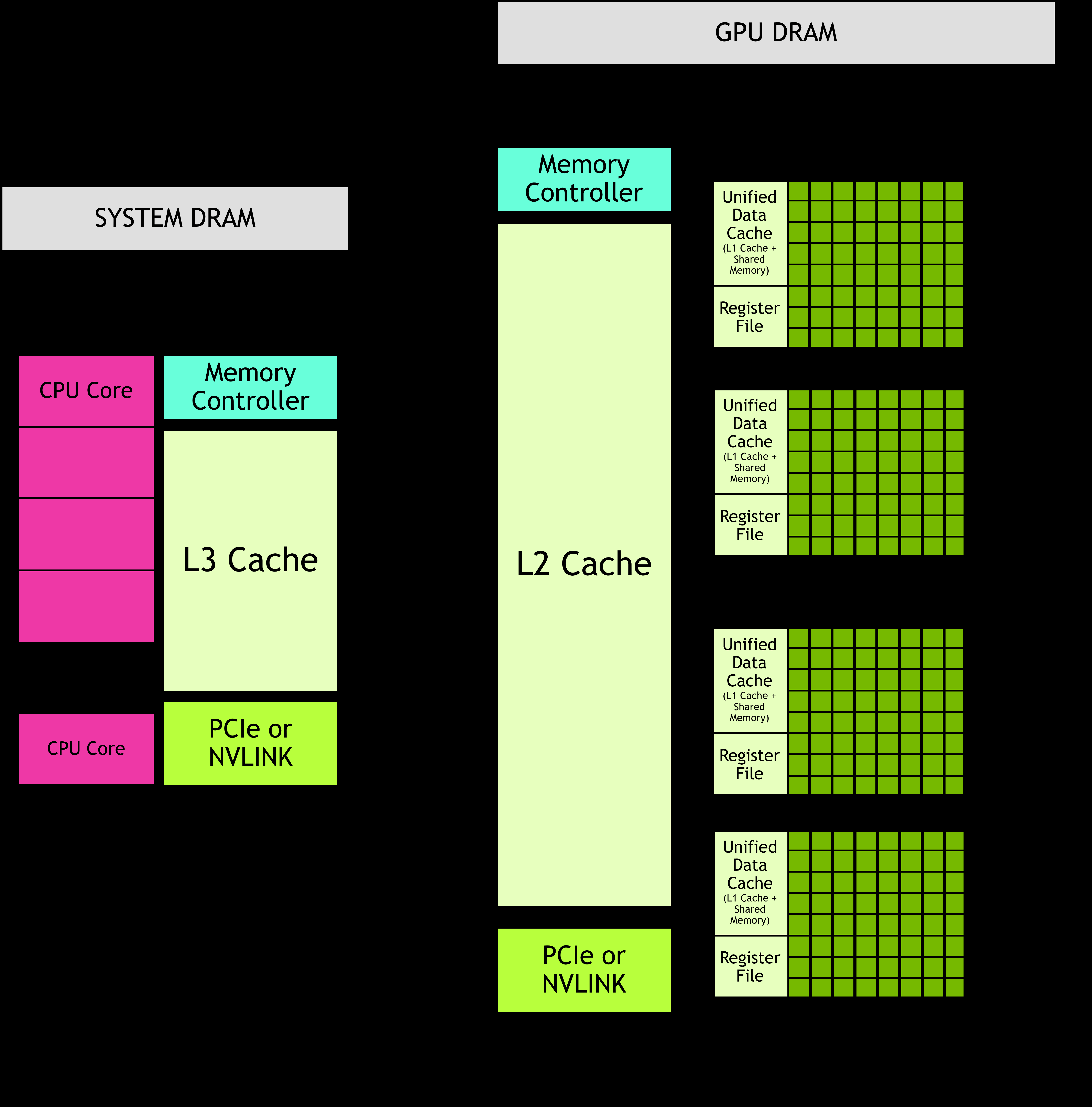
CUDA编程模型假定了一个异构计算系统,这意味着系统同时包含GPU和CPU。CPU及其直接连接的内存分别称为主机(host)和主机内存(host memory)。GPU及其直接连接的内存分别称为设备(device)和设备内存(device memory)。
CUDA应用程序部分代码在GPU上执行,但应用程序始终在CPU上启动,运行在CPU上的代码(主机代码)可以使用CUDA API在主机内存与设备内存之间复制数据、启动GPU上的代码执行,并等待数据复制或GPU代码完成。应用程序在GPU上执行的代码称为设备代码,在GPU上调用执行的函数被称为内核(kernel)。CPU启动内核运行的操作称为内核启动(launching the kernel)。
GPU硬件模型
在CUDA编程中,GPU可视为一组流多处理器(SM)的集合,这些SM被组织成图形处理集群(GPC)。每个SM包含一个本地寄存器文件、一个统一数据缓存以及若干执行计算的功能单元。统一数据缓存为共享内存和L1缓存提供物理资源。统一数据缓存分配给L1和共享内存的比例可在运行时配置。
当应用程序启动内核时,它会以大量线程(通常达数百万个)启动。这些线程被组织成多个块(thread block)。线程块又被组织成网格(grid)。网格中的所有线程块具有相同的大小和维度。图3展示了一个线程块网格的示意图。

一个线程块内的所有线程都在单个流多处理器上执行。这使得线程块内的线程能够高效地相互通信和同步。线程块内的所有线程都可以访问片上共享存储器,该存储器可用于在线程块内的线程之间交换信息。而线程块之间的调度则无法得到保证,因此一个线程块无法依赖其他线程块的结果,图4展示了网格中的线程块如何分配给流多处理器的示例。
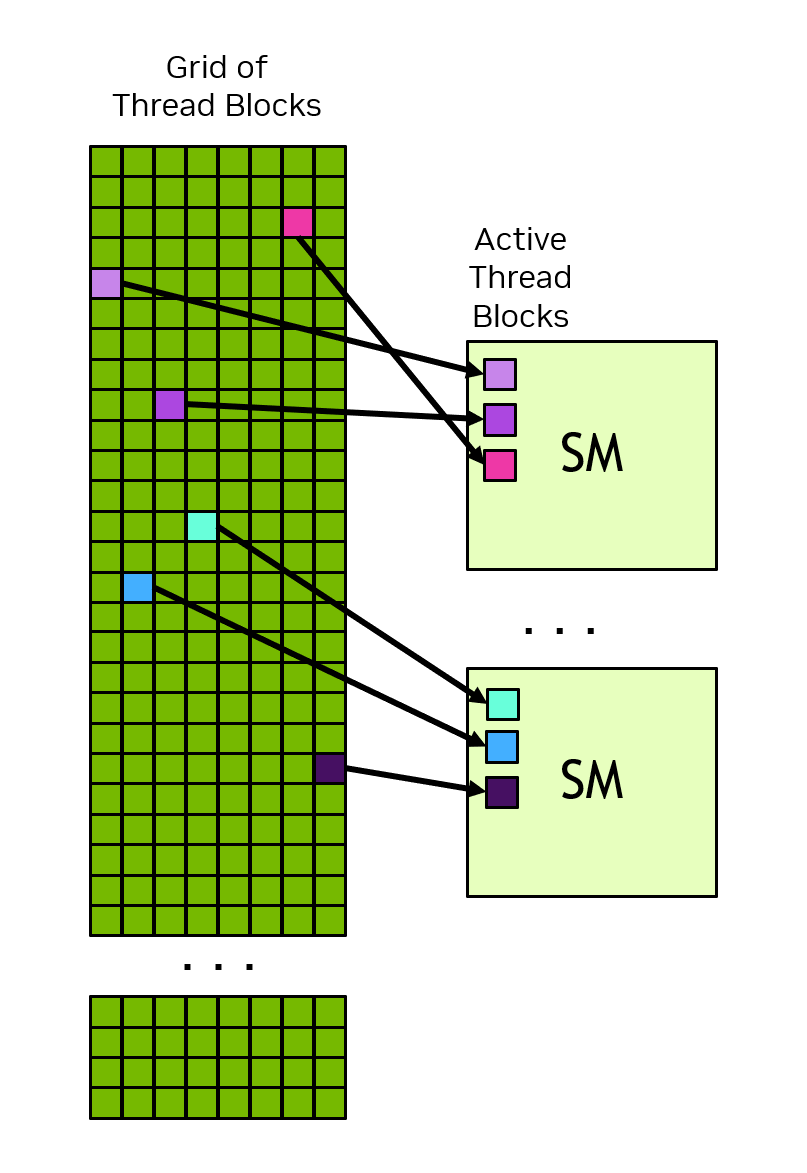
CUDA编程模型能够实现任意大规模的计算网格在任何大小的GPU上运行,无论GPU只有一个流多处理器(SM)还是拥有数千个SM。为实现这一点,除少数特例外,CUDA编程模型要求不同线程块之间的线程不能存在数据依赖关系。也就是说,一个线程不应依赖于同一网格中不同线程块内其他线程的计算结果,也不应与它们进行同步操作。
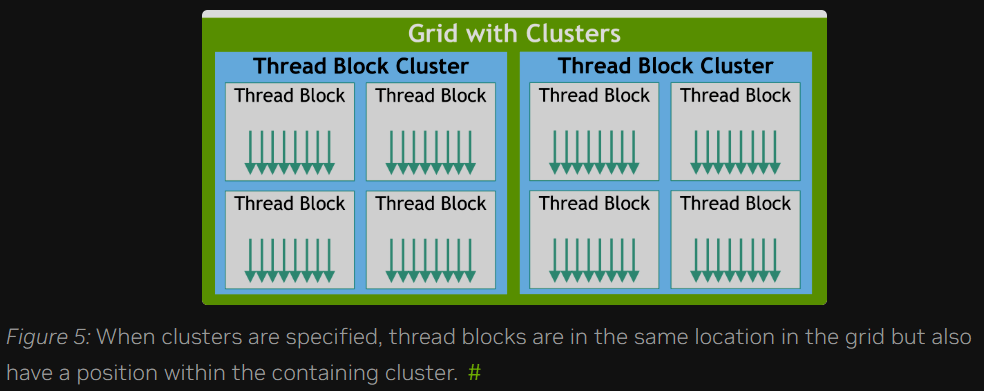
除了线程块之外,具备计算能力9.0及更高版本的GPU还引入了一种可选的分组层级,称为集群(thread block cluster)。集群是一组线程块,就像线程块和网格一样,可以按一维、二维或三维的方式排布。图5展示了一个既被组织成线程块网格,又被进一步划分为集群的示例。指定集群不会改变网格的维度,也不会改变线程块在网格中的索引。
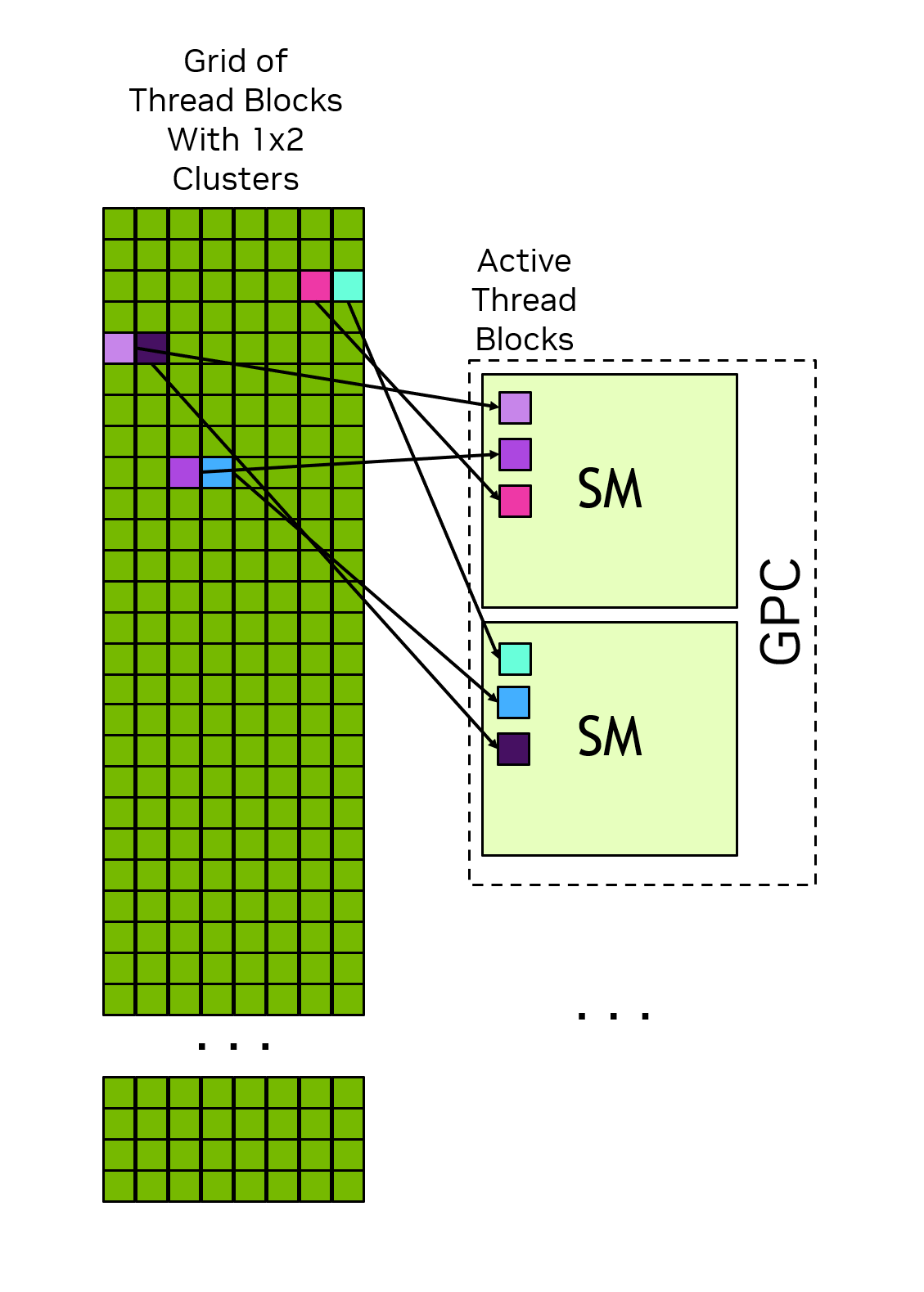
集群中的所有线程块在单个GPC内执行如图6展示,这样属于同一集群但不同线程块内的线程可以利用协作组(Cooperative Groups)提供的软件接口相互通信和同步,集群内的线程可以访问该集群中所有线程块的共享内存,这被称为分布式共享内存。集群的最大大小取决于硬件,并且在不同设备间有所差异。
线程块内包含称为warp的线程组(每组32个线程)。Warp以单指令多线程(SIMT)方式执行,即所有线程执行同一指令序列,但可根据数据条件进入不同的控制流分支。当分支条件在warp内不满足一致时,不进入当前分支的线程会被屏蔽,只有活跃线程继续执行,这种现象称为warp发散。它会降低并行效率,因此保持warp内的控制流一致性是最大化GPU利用的关键。
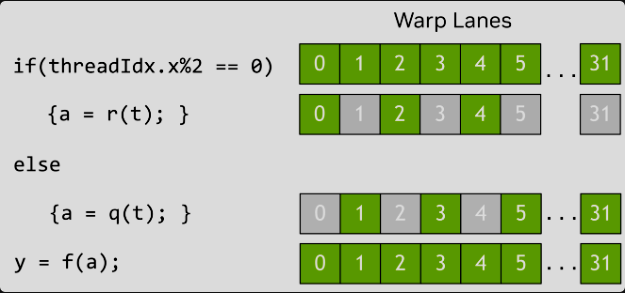
在CUDA的SIMT模型中,一个Warp(通常为32个线程)内的所有线程是同步执行的,这是编程模型的基础。虽然硬件实现可能有透明优化,但程序若违反此同步假设,将导致未定义行为。理解Warp模型对优化全局内存合并访问和共享内存体访问至关重要。一个关键的最佳实践是:将线程块的总线程数设置为32的倍数,以避免最后一个Warp出现未使用的线程通道,从而防止功能单元利用率和内存访问效率的下降。
SIMT 和 SIMD 的核心区别在于控制流。SIMD 遵循单一控制流,所有数据必须同步执行相同指令;而 SIMT 允许每个线程拥有独立控制流,线程间可以执行不同的分支。因此,SIMT 不像 SIMD 那样受限于固定的数据宽度,具有更高的灵活性。
GPU内存
GPU和CPU均配有直连的DRAM芯片,在GPU中被称为“全局内存”(可被GPU内所有流多处理器访问),在CPU中则称为“系统内存”或“主机内存”。两者共享统一的虚拟内存空间,但各自拥有独立且唯一的地址范围,使得系统能够精确识别任何虚拟地址所属的物理位置(具体GPU或CPU)。CUDA提供了丰富API,用以灵活分配CPU/GPU内存、在设备间或设备内复制数据,并支持显式控制数据的本地性。此外,统一内存机制可由运行时或硬件自动管理内存布局,进一步简化编程。
除了全局内存,GPU的每个流多处理器(SM)都配备有高速的片上内存,包括寄存器文件和共享内存。寄存器文件用于存储线程局部变量,由编译器分配;共享内存则允许同一线程块或集群内的所有线程快速交换数据。这两者的大小都有限,且与SM的L1缓存一起被线程块内所有线程共享。关键限制在于:调度线程块到SM时,每个线程所需寄存器数乘以线程块总线程数不得超过SM可用寄存器总量,否则内核将无法启动,必须减少线程块规模。同时,共享内存是在线程块级别统一分配的,而不像寄存器那样按线程独立分配(解释:寄存器分配是分别为每个线程开辟空间,不同线程不能访问彼此寄存器;共享内存是给线程块直接分配一个大的空间并被该线程块的所有线程共用)
GPU 还拥有 L1 和 L2 两级缓存。每个流式多处理器(SM)都配有一个 L1 缓存,它属于统一数据缓存的一部分。而一个更大的 L2 缓存则由 GPU 内的所有 SM 共享,GPU 还拥有 L1 和 L2 两级缓存。每个流式多处理器(SM)都配有一个 L1 缓存,它属于统一数据缓存的一部分。而一个更大的 L2 缓存则由 GPU 内的所有 SM 共享。
在CUDA编程中,显式分配的GPU或CPU内存只能被运行在对应设备上的代码访问,数据需通过CUDA API在设备间显式复制。虽然统一内存功能允许CPU和GPU共享内存空间,由运行时或硬件自动管理数据位置,但要获得最优性能,仍需尽量减少内存迁移,并尽可能让处理器访问本地内存。系统的硬件特性决定了内存空间间的数据交换机制,而不同类别的统一内存系统及其详细行为将在后面进行阐述。
CUDA平台
计算能力(CC)与流处理器版本
每款NVIDIA GPU都有一个计算能力(CC)编号,它标识了该GPU支持的功能特性,并规定了该GPU的一些硬件参数。计算能力以主、次版本号的格式X.Y表示,其中X是主版本号,Y是次版本号。例如,CC 12.0的主版本号为12,次版本号为0。计算能力直接对应于SM的版本号。例如,计算能力为12.0的GPU,其内部的SM版本为sm_120。此版本号用于标记二进制文件。(如何查询和确定系统中GPU计算能力见:[计算能力查询](https://docs.nvidia.com/cuda/cuda-programming-guide/05-appendices/compute-capabilities.html) ;所有NVIDIA GPU及其计算能力列表见:[nvidia gpu](https://developer.nvidia.com/cuda/gpus))
CUDA工具包和官方驱动
NVIDIA 驱动程序(driver)是必须安装在主机操作系统上的基础软件,它充当 GPU 的“操作系统”,支持包括 CUDA、Vulkan 和 Direct3D 在内的所有 GPU 使用方式,是实现 GPU 功能的基石。而 CUDA 工具包(Toolkit)则是一个独立的软件产品,它提供库、头文件和工具,用于编写和构建 GPU 计算软件。其中,CUDA 运行时(runtime)作为 CUDA 工具包提供的一个特殊库,通过其 API 和语言扩展,简化了内存管理、数据传输和内核启动等常见任务。不同 GPU、驱动程序与 CUDA 工具包版本之间的具体兼容性细节,则由专门的 [CUDA 兼容性文档](https://docs.nvidia.com/deploy/cuda-compatibility/index.html)详细说明。
CUDA运行时API构建在一个名为CUDA驱动API的底层API之上,而后者是由NVIDIA驱动程序提供的接口。本文主要聚焦于CUDA运行时API所暴露的接口。如果需要,仅通过驱动API也能实现同样的功能,且部分特性仅能通过驱动API使用。应用程序可以单独或同时使用这两种API,并可实现两者的互操作。相关相互操作内容参见后续内容。
完整的CUDA运行时API函数参考文档请参阅[《CUDA Runtime API Documentation》](https://docs.nvidia.com/cuda/cuda-runtime-api/index.html)。
完整的CUDA驱动API参考文档请参阅[《CUDA Driver API Documentation》](https://docs.nvidia.com/cuda/cuda-driver-api/index.html)。
并行线程执行(PTX)
CUDA平台存在一个基本但有时不易察觉的层面,即并行线程执行(PTX)虚拟指令集架构。PTX是一种用于NVIDIA GPU的高级汇编语言,为实际GPU硬件的物理指令集提供了抽象层。与其他平台类似,应用程序可直接用此汇编语言编写,但这样做可能会给软件开发带来不必要的复杂性和难度。
领域专用语言和高级语言的编译器可将PTX代码生成作为中间表示,随后利用NVIDIA的离线或即时编译工具(JIT)生成可执行的二进制GPU代码。这使得CUDA平台不仅限于NVIDIA提供的工具(如NVCC:NVIDIA CUDA编译器)所支持的语言,而是可以通过多种语言进行编程。
随着GPU功能的演进与扩展,PTX虚拟指令集架构规范会进行版本迭代。PTX版本与SM版本相似,均对应特定的计算能力。例如,完全支持计算能力8.0所有特性的PTX版本被称为compute_80。
Cubins和Fatbins
CUDA应用程序和库通常采用高级语言编写,其编译流程是:首先编译为PTX中间代码,再针对具体GPU的SM架构(如sm_120)生成对应的CUDA二进制文件(cubin)。而实际的可执行文件或库文件中,GPU代码以fatbin容器的形式封装,其中可包含面向多种GPU架构(即不同SM版本)的cubin和PTX代码,从而确保在运行时能为目标GPU自动选择最匹配的二进制版本。Fatbin文件也可以包含一个或多个版本的GPU代码PTX文件,其用途在后续说明。图8展示了一个应用程序或库二进制文件的示例,其中包含多个版本的GPU代码cubin文件以及一个版本的PTX代码。

NVIDIA GPU 的二进制兼容性遵循特定规则:在同一计算能力主版本内,次版本号大于或等于 cubin 构建目标版本的 GPU 能够加载并执行该 cubin(例如,为 sm_86 构建的代码可在 8.6 或 8.9 的设备上运行,但无法在 8.0 上运行);而不同主版本之间则完全不兼容(例如 sm_86 代码无法在 9.0 设备上运行)。在表述上,常使用如 "sm_86" 这样的简写来指代针对特定计算能力版本编译的二进制代码。二进制兼容性仅适用于由 NVIDIA 工具(如 nvcc)创建的二进制文件。不支持手动编辑或为 NVIDIA GPU 生成二进制代码。如果二进制文件以任何方式被修改,兼容性承诺将失效。
GPU代码可以以二进制或PTX形式存储在可执行文件中,它们分别封装在Cubin和Fatbin中。当应用程序存储的是GPU代码的PTX版本时,该PTX代码可以在应用程序运行时,针对计算能力不低于该PTX代码计算能力的任何架构进行即时编译。例如,如果应用程序包含了针对compute_80的PTX代码,那么该代码可以在应用程序运行时,即时编译为更高的SM版本,例如sm_120。这使得应用程序或库无需重新构建,就能实现与未来GPU的前向兼容。
应用程序运行时加载的PTX代码由设备驱动程序通过即时编译转换为二进制代码,这种机制虽然会增加应用加载时间,但能使应用受益于驱动更新带来的编译器改进,并支持在编译后出现的新设备上运行。设备驱动程序会自动缓存编译生成的二进制代码,此计算缓存会在驱动升级时失效,以确保应用总是使用最新的编译器。随着CUDA的发展,即时编译的时机和方式已变得更加灵活,可通过选项或环境变量进行控制,同时也可选择使用NVRTC在运行时直接将CUDA C++代码编译为PTX。