原文章链接:https://docs.nvidia.com/cuda/cuda-programming-guide/02-basics/writing-cuda-kernels.html
1.线程的层次结构
SIMT模型允许每个线程保持自身状态和控制流。从功能角度而言,每个线程可以执行独立的代码路径。但需要注意,通过减少同一warp内线程执行不同代码路径的情况,可以显著提升内核代码的性能表现。
经典线程的层次结构包含grid-block-thread,其中尺寸与索引访问的相关函数如下所示

使用多维线程块和网格仅出于便利考虑,不影响性能。线程块内的线程以可预测的方式线性排列:索引x的变化速度最快,其次是y,最后是z。(类似于x是秒针、y是分针、z是时针)
2.GPU设备内存空间
CUDA 设备包含多个可由内核中的 CUDA 线程访问的内存空间。下表总结了常见内存类型及其线程作用域和生命周期。

2.1 全局内存
全局内存(也称设备内存 / Device Memory)是 GPU 上最主要的存储空间,其地位和作用等同于 CPU 系统的 RAM。它的核心特性是网格级完全可见(Grid-wide accessible),这意味着在核函数(Kernel)运行期间,GPU 上启动的所有线程都可以自由地读取和写入这块内存区中的数据。
全局内存的数据具有持久性(Persistent),它的生命周期贯穿于整个应用程序,不会随着核函数的结束而消失。开发者必须手动接管它的生老病死,涉及的核心 CUDA API 包括:
- 分配:使用
cudaMalloc(标准显存分配)或cudaMallocManaged(统一内存分配)开辟空间。 - 搬运:使用
cudaMemcpy在主机(CPU)和全局内存(GPU)之间双向传输数据。 - 销毁:使用完毕后必须严格调用
cudaFree释放内存空间,或者通过调用cudaDeviceReset直接重置当前设备并清空所有分配。
在 CUDA 编程模型中,主机端启动的核函数(Kernel)的返回值类型强制要求为 void。因此,全局内存是 GPU 将计算结果传回主机,或者将中间数据传递给下一个核函数的“唯一物理载体”。但也正是因为所有线程都能并发访问这块区域,开发者必须对底层执行保持敬畏,采取合理的内存合并或同步策略,严防多线程并发读写导致的数据竞争(Data Races)。
__global__ void vecAdd(float* A, float* B, float* C, int vectorLength)
{
int workIndex = threadIdx.x + blockIdx.x*blockDim.x;
if(workIndex < vectorLength)
{
C[workIndex] = A[workIndex] + B[workIndex];2.2 共享内存
共享内存是一种位于流多处理器(SM, Streaming Multiprocessor)内部的片上(On-chip)内存,在物理层面与 L1 缓存共享硬件资源。共享内存的带宽极高且延迟极低,其可见性与生命周期被严格限制在线程块级别。其内存空间在核函数(Kernel)启动时分配(为每个线程块分配一个独立的共享内存空间),数据在整个核函数执行期间持续存在(Persist)。它仅对同一个线程块内的所有线程可见,其他线程块绝对无法访问。
鉴于块内所有线程均可并发读写共享内存,如果不加干预,极易引发读写冲突与数据竞争(Data Races)。为保证内存一致性,必须通过调用 __syncthreads() 内置函数进行强制同步。该函数充当块级执行屏障(Barrier),它会阻塞先到达的线程,直到块内所有线程都执行到此代码点,以确保此前的共享内存读写操作已全部完成并对所有线程可见。
// assuming blockDim.x is 128
__global__ void example_syncthreads(int* input_data, int* output_data) {
__shared__ int shared_data[128];
// Every thread writes to a distinct element of 'shared_data':
shared_data[threadIdx.x] = input_data[threadIdx.x];
// All threads synchronize, guaranteeing all writes to 'shared_data' are ordered
// before any thread is unblocked from '__syncthreads()':
__syncthreads();
// A single thread safely reads 'shared_data':
if (threadIdx.x == 0) {
int sum = 0;
for (int i = 0; i < blockDim.x; ++i) {
sum += shared_data[i];
}
output_data[blockIdx.x] = sum;
}
}共享内存的具体容量上限严格依赖于 GPU 的微架构(Architecture)。在物理层面,共享内存与 L1 缓存共享同一块片上存储(On-chip SRAM)。这使得两者在容量分配上构成“零和博弈”:核函数(Kernel)使用的共享内存越多,留给 L1 缓存的空间就越小;反之,若核函数完全不使用共享内存,L1 缓存将独占该物理区域的全部容量。
为了保证代码在不同 GPU 架构上的鲁棒性,开发者应避免硬编码(Hardcode)内存上限,而必须通过调用 cudaGetDeviceProperties 函数进行动态查询。在返回的 cudaDeviceProp 结构体中,必须重点审查两个属性:
sharedMemPerMultiprocessor:单个流多处理器(SM)所能提供的共享内存总容量上限(决定了该 SM 能并发驻留多少个线程块)。sharedMemPerBlock:单个线程块(Thread Block)所能申请的共享内存最大限制。
开发者可通过调用 cudaFuncSetCacheConfig 函数,向 CUDA 运行时(Runtime)显式提交共享内存与 L1 缓存的容量划分倾向(例如偏好更大的共享内存,或偏好更大的 L1 缓存)。关键注意:该配置仅作为“性能偏好建议(Preference)”,而非强制性指令。CUDA 运行时拥有最终裁量权,会结合当前可用硬件资源与核函数的实际需求进行最终调配。
静态共享内存适用于在编译期即可确定数据规模的场景。
- 声明语法:在核函数(Kernel)内部,使用
__shared__修饰符声明定长数组(例如:__shared__ float smem[1024];)。 - 行为特征:该数组被分配在当前线程块的物理共享内存中,其生命周期与核函数执行周期一致。块内所有线程均持有对该数组的访问权限,因此在进行并发读写时,仍需显式调用
__syncthreads()以防止数据竞争。
动态共享内存适用于规模依赖输入数据、需在运行期(Run-time)决定的场景(如处理变长序列)。
- 配置语法:必须在主机端(Host)发起核函数调用时,通过执行配置的第三个参数指定所需内存的字节数(Bytes)(例如:
kernel<<<grid, block, sharedMemBytes>>>(...);)。 - 声明语法:在核函数内部,必须配合
extern关键字声明未定长数组(例如:extern __shared__ float smem[];)。
当核函数内部需要同时使用多个不同类型的动态共享内存数组时,CUDA 底层仅允许存在一个 extern __shared__ 声明。开发者必须手动进行内存池的切分(Memory Partitioning)。
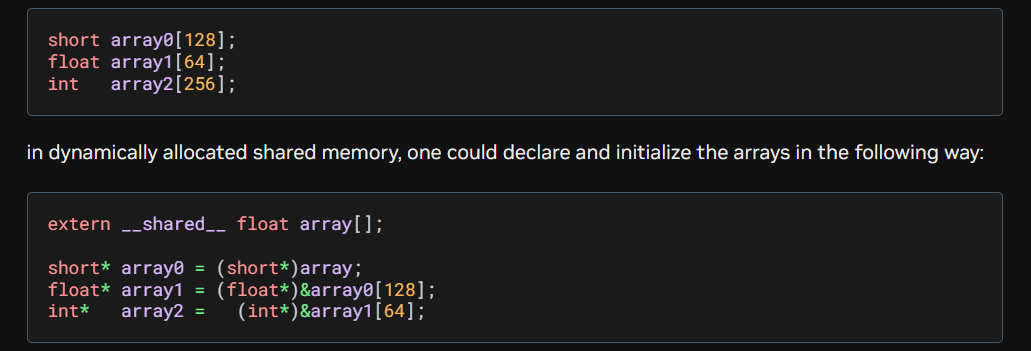
特定类型的指针必须指向其数据类型大小的整数倍地址。例如,float 或 int 类型的指针必须对齐到 4 字节边界。错误示例:若前一个数组的结束地址未对齐(如 &arr0[127] 并非 4 的倍数),将其强制转换为 float* 会导致硬件级的未对齐内存访问(Unaligned Memory Access),这将引发严重的性能降级甚至程序崩溃。开发者必须手动填充补齐(Padding)以满足对齐要求。
extern __shared__ float array[];
short* array0 = (short*)array;
float* array1 = (float*)&array0[127];2.3 寄存器
寄存器物理驻留于SM内部,具有严格的线程私有作用域。其分配与生命周期完全由编译器负责隐式管理,专门用于在核函数执行期间作为线程局部存储使用。属于受限的底层核心资源,其物理上限决定了硬件的并发承载力。开发者必须通过查阅 GPU 的设备属性来获取硬件的具体限制,其中必须重点关注两个核心指标:regsPerMultiprocessor(限定单个 SM 上可用的寄存器总数)以及 regsPerBlock(限定单个线程块可分配的寄存器总数)。
在编译阶段,开发者可通过 NVCC 编译器的 -maxrregcount 选项显式设定单个核函数可使用的寄存器数量上限。这是一项关键的性能调优权衡策略:人为压低寄存器的使用上限,能够释放物理资源从而允许更多的线程块在 SM 上并发调度(提升占用率);但其核心代价是可能引发严重的寄存器溢出(Register Spilling),导致数据被迫迁移至更慢的局部内存层级,进而大幅拖累执行性能。
2.4 局部内存
局部内存在逻辑作用域上属于线程私有,其分配与生命周期由 NVCC 编译器隐式管理,行为上类似于寄存器。然而,必须深刻理解的是,“局部”一词仅指代其逻辑可见性,其物理存储位置实际上位于全局/设备内存空间中。正因为物理上驻留于片外显存,局部内存的访存延迟与带宽完全等同于全局内存。
局部内存通常作为寄存器资源的补充或作为寄存器溢出的退路。NVCC 编译器会在以下三种特定场景下,自动将局部自动变量降级放入局部内存中:
- 编译器无法在编译期确定其索引为常量值的数组。(如
arr[i]),而非固定的数字(如arr[0]) - 体积过于庞大,会导致消耗过量寄存器空间的结构体(Structures)或大数组。
- 核函数(Kernel)实际使用的寄存器总数超出了硬件物理可用上限,从而发生寄存器溢出。
尽管面临全局显存级别的高延迟,但局部内存的底层数据组织结构经过了专门优化:连续的 32 位字被映射到连续的线程 ID 上。得益于这种交错式的排列方式,只要同一个线程束(Warp)内的所有线程同时访问各自变量的同一个相对地址(例如访问数组的同一索引,或结构体的同一个成员),该访问操作就能实现完全的合并访存(Fully Coalesced Access),从而最大化利用显存带宽。例如:
2.5 常量内存
常量内存驻留于 GPU 设备端,具有网格级别(Grid scope)的全局可见性。其生命周期与创建它的 CUDA 上下文(Context)完全一致(即伴随应用程序的整个生命周期),且每个物理设备均维护一份独立的内存对象。在核函数(Kernel)执行期间,常量内存被严格限制为只读(Read-only)状态。
在编程范式上,常量内存变量必须在所有函数体外部,使用 __constant__ 修饰符进行全局声明,并且必须由主机端(Host)负责初始化。主机端无法直接通过标准指针访问它,必须调用专属的 CUDA 运行时库函数进行交互与数据搬运,这些核心函数包括:cudaGetSymbolAddress()(获取符号地址)、cudaGetSymbolSize()(获取符号大小)、cudaMemcpyToSymbol()(将数据从主机拷入常量内存)以及 cudaMemcpyFromSymbol()(将数据从常量内存拷回主机)。
常量内存的物理容量极其有限,通常每个设备仅提供 64KB的存储空间。开发者必须通过设备属性(Device Properties)中的 totalConstMem 字段来动态查询当前硬件的具体容量上限。基于其“容量小、全局只读”的物理与逻辑特性,常量内存的最佳工程适用场景是:存储需被网格中每个线程频繁共享读取的小型只读数据集(例如算法中的固定参数或查找表)。
// In your .cu file
__constant__ float coeffs[4];
__global__ void compute(float *out) {
int idx = threadIdx.x;
out[idx] = coeffs[0] * idx + coeffs[1];
}
// In your host code
float h_coeffs[4] = {1.0f, 2.0f, 3.0f, 4.0f};
cudaMemcpyToSymbol(coeffs, h_coeffs, sizeof(h_coeffs));
compute<<<1, 10>>>(device_out);2.6 缓存
GPU 在硬件底层采用了多级缓存架构(核心包含 L1 与 L2 缓存)。其中,L2 缓存(L2 Cache)驻留于设备端(Device),属于全局共享资源,被所有的流多处理器(SM)共同访问。在工程调优时,开发者必须通过调用 cudaGetDeviceProperties 函数,并提取其返回结构体中的 l2CacheSize 属性字段,来精准探查当前物理设备的 L2 缓存总容量,这是评估全局数据复用效率的硬件基础。
L1 缓存(L1 Cache)在物理层面上直接内嵌于每个单独的 SM 中。其最关键的底层特征是:L1 缓存与共享内存(Shared Memory)在硬件上完全占用同一块物理存储介质。这种设计意味着两者在容量分配上是互斥的——当核函数(Kernel)完全不申请使用共享内存时,该块物理空间的全部容量将被系统自动接管,100% 作为 L1 缓存使用,从而最大化常规显存读取的命中率。
2.7 分布式共享内存
在计算能力 9.0中,CUDA 引入了由协作组(Cooperative Groups)支持的线程块集群(Thread Block Clusters)特性。该机制允许集群内的所有线程跨越传统物理边界,直接访问集群内其他线程块的共享内存,从而构建出分布式共享内存(Distributed Shared Memory)地址空间。在此空间内,线程可对本地或远程线程块的地址自由执行读取、写入及原子操作(Atomics)。在资源分配上,无论是静态还是动态声明,共享内存的配置基准依然是“单个线程块”。分布式共享内存的总物理容量严格等于“集群内的线程块总数”乘以“单个线程块的共享内存大小”。
跨块访问分布式共享内存的核心硬件约束是:所有相关的线程块必须在物理上同时存活(Exist)。为了保证内存安全,开发者必须调用 cluster_group 类下的 cluster.sync() 函数。该函数具备双重重要作用:一是在执行初期确保集群内的所有线程块均已成功启动;二是在执行末期充当生命周期屏障,强制确保所有针对分布式共享内存的读写操作完全结束后,才允许任何线程块退出,从而严防因目标线程块提前销毁而导致的非法远程内存访问。
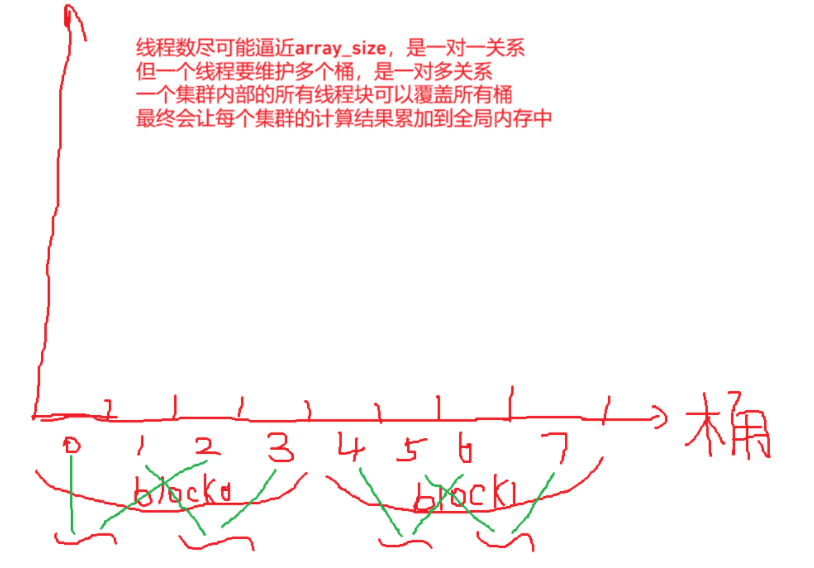
2.7.1 直方图案例
在传统的直方图计算中,开发者通常先在单块共享内存中局部统计,再通过全局内存原子操作进行汇总。然而,由于单块共享内存容量极小,一旦直方图桶(Bins)的数量超出限制,算法只能被迫退化为直接操作低效的全局内存。分布式共享内存的出现填补了这一架构空白。它为存储分配提供了一个大容量的高速“中间层”,使得程序能够根据 Bins 的具体规模,在单块共享内存、容量呈倍数扩展的分布式共享内存,以及全局显存之间进行灵活、自适应的计算降级与优化。具体代码与注释如下所示:
核函数:
#include <cooperative_groups.h>
// 参数说明:
// bins: 指向全局显存的指针,用于存储最终的直方图统计结果。
// nbins: 直方图的总桶数(例如 1024 种不同的像素值)。
// bins_per_block: 每个线程块(Block)在分布式共享内存中负责维护的桶的数量。
// input: 指向输入数据的全局显存指针。__restrict__ 关键字向编译器保证没有其他指针会修改这块内存,从而优化读取速度。
// array_size: 输入数据数组的总长度
__global__ void clusterHist_kernel(int *bins, const int nbins, const int bins_per_block, const int *__restrict__ input,
size_t array_size)
{
// 1. 动态共享内存声明 (Dynamic Shared Memory)
// extern 与 [] 结合,表明该共享内存的大小是在启动核函数时(Host端)动态指定的。
// 在这里,它将作为当前线程块负责的那部分直方图桶的“局部高速缓存”。
extern __shared__ int smem[];
namespace cg = cooperative_groups;
// 2. 获取全局线程唯一索引 (Global Thread Rank)
// 计算当前线程在整个 Grid(网格)中的绝对线性编号。
// 作用类似于传统的 (blockIdx.x * blockDim.x) + threadIdx.x,但支持更复杂的多维结构。
int tid = cg::this_grid().thread_rank();
// 3. 创建一个代表当前集群的对象。只有处于同一个集群内的线程块,才能互相访问共享内存。
cg::cluster_group cluster = cg::this_cluster();
// 获取当前线程块(Block)在当前集群(Cluster)内的排名(编号)。
// 例如,如果集群大小为 8,则该值为 0 到 7 之间的整数。
// 这个排名决定了当前块要负责直方图的哪一段区域。
unsigned int clusterBlockRank = cluster.block_rank();
// 获取当前集群在 X 维度上包含的线程块总数(在此直方图算法中,我们使用的是一维集群)。
int cluster_size = cluster.dim_blocks().x;
// 4. 并行初始化局部共享内存 (Parallel Initialization via Block-Stride Loop)
// 让当前线程块内的所有线程共同协作,把当前块分配到的共享内存清零。
// 使用 blockDim.x 作为步长(跨步循环),不仅能处理桶数大于线程数的情况,
// 还能保证同一个 Warp 内的线程访问连续的内存地址,实现内存合并(Memory Coalescing),达到最高带宽。
for (int i = threadIdx.x; i < bins_per_block; i += blockDim.x)
{
smem[i] = 0;
}
// 5. 极其关键的第一次集群同步 (Cluster Barrier - Initialization Phase)
// 必须确保两件事:
// 第一,集群内所有的线程块都已经成功调度到 SM 上(并发存在)。
// 第二,所有块的共享内存都已经彻底清零完毕。
// 如果不同步,跑得快的线程块可能会提前去写跑得慢的块的共享内存,导致数据被后续的清零操作覆盖。
cluster.sync();
// 6. 全局数据读取与处理 (Grid-Stride Loop)
// 经典的网格跨步循环。不管输入数据有多庞大(array_size),也不管 GPU 启动了多少个线程,
// 所有的线程都会像流水线工人一样,处理完一个数据后,向后跳过一个“全网格线程总数”的跨度,继续处理下一个数据。
for (int i = tid; i < array_size; i += blockDim.x * gridDim.x)
{
int ldata = input[i]; // 从全局显存读取一个数据点
// 7. 数据合法性边界截断 (Clamping)
// 防止脏数据导致后续计算出的内存地址越界,引发非法内存访问错误。
int binid = ldata;
if (ldata < 0)
binid = 0; // 负数全部归入第 0 个桶
else if (ldata >= nbins)
binid = nbins - 1; // 超过最大值的全部归入最后一个桶
// 8. 核心路由计算:确定数据该去哪个块的哪块内存 (Distributed Routing)
// 因为完整的直方图被切分并均匀分布在集群内多个块的共享内存中:
// dst_block_rank: 计算这个数据所属的桶,归集群里的几号线程块管?
int dst_block_rank = (int)(binid / bins_per_block);
// dst_offset: 计算这个数据,应该放在目标线程块共享内存的哪个具体偏移位置?
int dst_offset = binid % bins_per_block;
// 9. 建立分布式共享内存指针 (Mapping Remote Shared Memory)
// Hopper 架构的专属硬件魔法。把计算出的“目标块排名(dst_block_rank)”和本地指针传入,
// 硬件会通过内部高速互联网络(SM Fabric),返回一个直接指向目标线程块共享内存的物理地址指针。
int *dst_smem = cluster.map_shared_rank(smem, dst_block_rank);
// 10. 执行分布式共享内存原子加法 (Distributed Atomic Update)
// 直接对目标地址执行原子加 1 操作。
// 这比写全局显存快得多,极大地缓解了海量线程竞争同一地址带来的性能瓶颈。
atomicAdd(dst_smem + dst_offset, 1);
}
// 11. 极其关键的第二次集群同步 (Cluster Barrier - Execution Phase)
// 退出保护机制(Exit Protection)。
// 必须确保集群内所有的跨块读写操作彻底完成。如果没有这个同步,
// 某个块可能率先算完并退出,导致它名下的物理共享内存被硬件回收。
// 此时如果其他块还有“迟到”的数据想要投递到这个块,就会触发灾难性的显存寻址崩溃。
cluster.sync();
// 12. 最终结果汇总至全局显存 (Global Memory Aggregation)
// 各个线程块各自领回自己维护的那部分直方图桶,并将其累加到全局显存(Global Memory)中。
// cluster.block_rank() * bins_per_block 计算出当前块在全局大数组 bins 中的起始写入偏移量。
int *lbins = bins + cluster.block_rank() * bins_per_block;
// 同样使用块跨步循环(Block-Stride Loop)并行写出。
// 这里必须使用 atomicAdd,因为不同的集群(不同 Cluster)如果恰好在写同一个全局桶段,
// 普通加法会导致数据覆盖,原子操作保证了跨集群的最终正确性。
for (int i = threadIdx.x; i < bins_per_block; i += blockDim.x)
{
atomicAdd(&lbins[i], smem[i]);
}
}主机端调用
{
// 1. 初始化扩展启动配置结构体 (Extensible Launch Configuration)
// 这是 CUDA 9.0+ 引入的新标准,用于替代传统的 <<<grid, block, smem, stream>>> 语法,
// 它的存在是为了能够挂载极其复杂的硬件级属性(如 Cluster 配置)。
cudaLaunchConfig_t config = {0};
// 2. 配置网格与线程块维度 (Grid & Block Dimensions)
// config.gridDim: 设定启动的总线程块数量。这里依赖整除计算,实际工程中通常会向上取整,
// 但由于核函数内部使用了网格跨步循环(Grid-Stride Loop),即使向下取整截断,也不会导致程序崩溃。
config.gridDim = array_size / threads_per_block;
// config.blockDim: 设定每个线程块包含的线程数(例如 256 或 512)。
config.blockDim = threads_per_block;
// 3. 定义集群规模 (Define Cluster Size)
// 决定了一个“集群(Cluster)”内包含多少个“线程块(Block)”。
// 硬件约束:属于同一个 Cluster 的 Block 会被强制调度到同一个显存处理器集群(GPC)内。
// 逻辑意义:如果设为 1,则退化为传统模式(无分布式共享内存);设为 2 及以上,则开启硬件高速互联。
int cluster_size = 2; // 此处设为 2,代表每 2 个 Block 结对成一个集群,共享彼此的物理内存。
// 4. 计算分布式任务切分 (Partition Histogram Bins)
// nbins 是直方图的总桶数。此处将其平均分配给集群内的各个线程块。
// 例如:总共 1024 个桶,cluster_size 为 2,那么每个 Block 只需在其共享内存中维护 512 个桶。
int nbins_per_block = nbins / cluster_size;
// 5. 计算并设置单块动态共享内存容量 (Dynamic Shared Memory Allocation)
// 极其重要的底层概念:无论是否开启分布式共享内存,物理内存的申请依然是“按单个 Block”为单位的!
// 分布式共享内存的总容量 = cluster_size * (每个 Block 申请的 dynamicSmemBytes)。
config.dynamicSmemBytes = nbins_per_block * sizeof(int);
// 6. 提权申请突破默认内存限制 (Bypass Default Shared Memory Limits)
// 默认情况下,CUDA 为了向后兼容,将单个 Block 的共享内存上限锁死在 48KB。
// 当我们需要处理大规模直方图时,所需的共享内存会轻易超过这个限制。
// cudaFuncSetAttribute:向 CUDA 驱动申请“特批”,允许当前核函数使用更大的动态共享内存。
// 如果不加这一句,稍后启动核函数时如果超出默认上限,程序会直接报错崩溃。
CUDA_CHECK(::cudaFuncSetAttribute((void *)clusterHist_kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, config.dynamicSmemBytes));
// 7. 配置集群专属硬件属性 (Configure Cluster Hardware Attributes)
// 创建一个属性数组(目前只需配置 1 个属性,即集群维度)。
cudaLaunchAttribute attribute[1];
// 声明当前属性的 ID 为“集群维度 (Cluster Dimension)”。
attribute[0].id = cudaLaunchAttributeClusterDimension;
// 设定集群的三维物理布局。
// 为了计算的高效性与寻址的简单性,通常直方图这种线性数据结构采用一维(X维度)排布即可。
attribute[0].val.clusterDim.x = cluster_size; // 将 X 维度设为我们之前定义的规模(例如 2)
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
// 8. 将属性挂载到启动配置上 (Attach Attributes to Configuration)
config.numAttrs = 1; // 告知系统当前挂载了 1 个扩展属性
config.attrs = attribute; // 绑定属性数组指针
// 9. 正式发射核函数 (Launch the Kernel)
// 使用增强版 API 发射核函数。此时,GPU 调度器会严格按照我们设定的 Cluster 规则,
// 将具有内部互联能力的线程块组派发到 Hopper 架构的计算核心上。
// 参数依次为:配置结构体指针, 核函数名, 接下来是传给核函数的实际业务参数。
cudaLaunchKernelEx(&config, clusterHist_kernel, bins, nbins, nbins_per_block, input, array_size);
}一个示意图以及相关思考如下所示:
3.内存表现
3.1 合并全局内存访问
全局内存是通过 32 字节的内存事务(Memory Transactions) 进行访问的。当一个 CUDA 线程从全局内存请求一个数据字(Word)(例如4个字节)时,相关的线程束(Warp)会将该线程束内所有线程的内存请求合并(Coalesce) 为满足请求所需的最小数量的内存事务。具体生成的事务数量,取决于每个线程访问的数据字大小,以及这些内存地址在各线程间的物理分布情况。
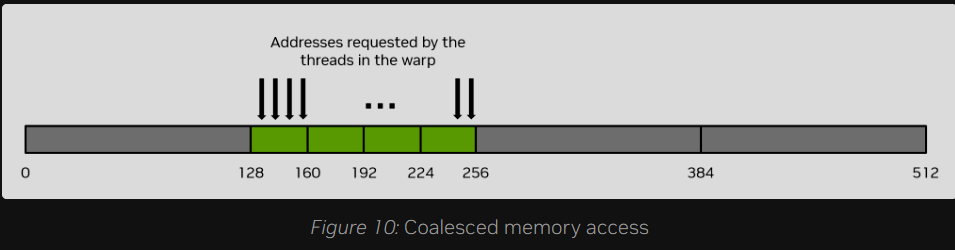
例如,如果一个线程请求一个 4 字节的数据字,该线程束实际向全局内存发起的内存事务总量将是 32 字节。为了最高效地利用内存系统,线程束应当尽可能消耗掉单次内存事务中抓取回来的全部数据。换言之,如果一个线程请求了 4 字节数据,而底层事务大小不可避免地是 32 字节,只要该线程束内的其他线程也能用得上这 32 字节事务里的其他 4 字节数据,就能实现内存系统的最优化利用。
举一个简单的例子:如果线程束中连续的线程请求内存中连续的 4 字节数据字,那么整个线程束总共需要 128 字节的内存。这 128 字节的需求将被打包,通过 4 次 32 字节的内存事务来完美获取。这种访问模式实现了 100% 的内存系统利用率。也就是说,所有的内存总线流量都被该线程束榨干了,没有任何带宽被浪费。图 10 展示了这种完美合并访存的经典示例。
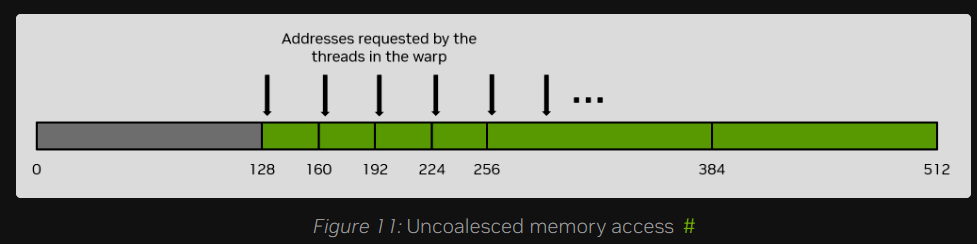
反之,最糟糕的病态场景是:线程束(Warp)内连续的线程所访问的数据元素,在内存中彼此相距 32 字节或更远。在这种情况下,线程束将被迫为每一个线程都发起一次独立的 32 字节内存事务。这样一来,总的内存流量将达到:32 字节 × 32 个线程/线程束 = 1024 字节。
然而,实际被有效利用的数据量仅为 128 字节(线程束内每个线程仅请求 4 字节),因此内存利用率仅为 128 / 1024 = 12.5%。这是一种对内存系统极其低效的利用方式。图 11 展示了这种非合并内存访问的示例。
实现合并访存最直接的方法,是让连续的线程访问内存中连续的元素。例如,对于一个使用一维线程块启动的核函数,下面的 VecAdd(向量加法)核函数就能实现合并访存。请观察线程索引 workIndex 是如何访问这三个数组的:连续的线程(由连续的 workIndex 值表示)访问的是数组中物理连续的元素。
__global__ void vecAdd(float* A, float* B, float* C, int vectorLength)
{
int workIndex = threadIdx.x + blockIdx.x*blockDim.x;
if(workIndex < vectorLength)
{
C[workIndex] = A[workIndex] + B[workIndex];需要注意的是,实现合并访存并不强制要求连续线程必须访问连续的内存元素,这仅仅是达到合并的最典型方式。只要线程束(Warp)中的所有线程,能够以某种线性或排列(Permuted) 的方式,访问同一个 32 字节内存分段内的元素,就会发生合并访存。
3.1.1 矩阵转置案例
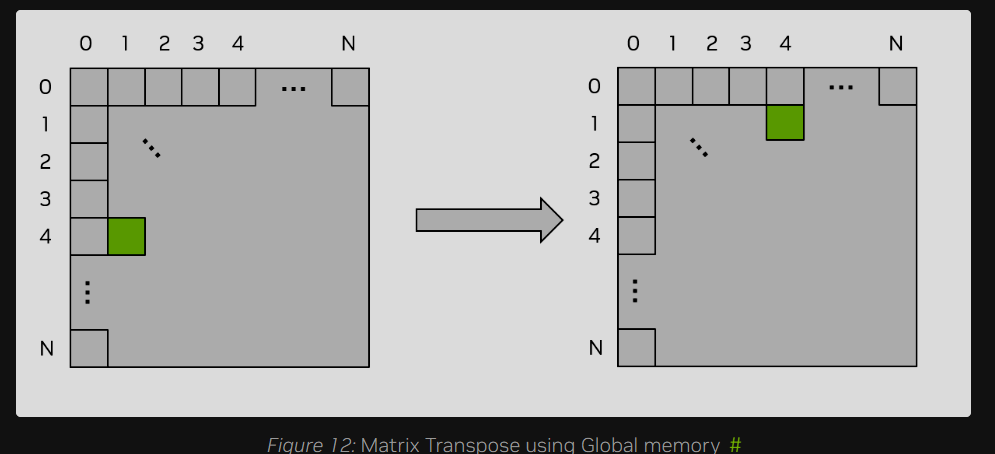
作为一个简单的例子,考虑一个异地(Out-of-place) 矩阵转置核函数。该函数将一个大小为 $N \times N$ 的 32 位浮点数方阵从矩阵 a 转置到矩阵 c。
本例使用二维网格(2D Grid),并假设启动的是 32 × 32 线程的二维线程块。也就是说,blockDim.x = 32 且 blockDim.y = 32。因此,每个二维线程块将负责操作矩阵中一个 32 × 32 的分块(Tile)。
由于每个线程都操作矩阵中一个唯一的元素,因此不需要进行显式的线程同步(Synchronization)。图 12 展示了这一矩阵转置操作的过程,图后附有核函数的源代码。
/* macro to index a 1D memory array with 2D indices in row-major order */
/* ld is the leading dimension, i.e. the number of columns in the matrix */
#define INDX( row, col, ld ) ( ( (row) * (ld) ) + (col) )
/* CUDA kernel for naive matrix transpose */
__global__ void naive_cuda_transpose(int m, float *a, float *c )
{
int myCol = blockDim.x * blockIdx.x + threadIdx.x;
int myRow = blockDim.y * blockIdx.y + threadIdx.y;
if( myRow < m && myCol < m )
{
c[INDX( myCol, myRow, m )] = a[INDX( myRow, myCol, m )];
} /* end if */
return;
} /* end naive_cuda_transpose */评估合并访存(Coalesced Memory Access) 的核心准则是最快变化维度(threadIdx.x)是否严格映射至连续的物理内存地址。具体而言,当 threadIdx.x(通常表现为列索引 myCol)作为一维寻址宏 INDX 的第二个参数时,连续线程能读取连续地址,从而实现完美的合并读取(例如对矩阵 a 的操作);然而,若在矩阵转置等场景中将其作为 INDX 的第一个参数写入目标矩阵 c,连续线程的物理寻址步长将被拉长为 ld(主维度长度,Leading Dimension)。当矩阵规模导致 ld > 32 时,这种跨步访存将演变为极度低效的非合并写入(病态场景)。针对这种不可避免的显存读写不对称瓶颈,底层架构的终极解法是引入共享内存(Shared Memory) 作为高速中转缓存,以此消除全局显存的非合并惩罚。
3.2 共享内存访问模式
共享内存的物理底层由 32 个存储体(Banks) 交错组织而成。其核心内存映射规则为:连续的多个32 位数据字会被依次分布到连续的存储体中。在理想状态下,每个存储体在单个时钟周期内仅能提供 32 位的数据访问带宽。
触发存储体冲突的核心条件是:当同一个线程束(Warp) 内的多个线程,尝试并发访问同一个存储体中的不同数据元素时。一旦发生冲突,硬件无法在单个时钟周期内处理该存储体上的多个独立请求,从而被迫将这些访问操作串行化(Serialized)。系统必须排队等待,直至所有请求该存储体数据的线程都完成访问,这种强制的串行化会导致极大的性能惩罚。
上述冲突规则存在明确的例外情况。当同一线程束内的多个线程尝试访问共享内存的同一个内存位置(无论是读或写)时,不会触发存储体冲突及串行化惩罚:
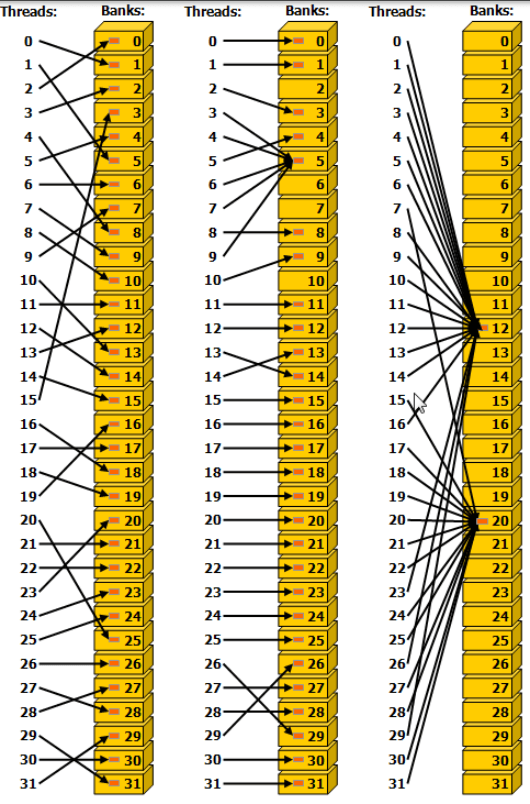
- 读操作豁免:当多线程读取同一地址时,硬件会触发广播(Broadcast) 机制,将该数据字在一个时钟周期内同时发送给所有发出请求的线程。
- 写操作豁免:当多线程写入同一地址时,该共享内存地址最终仅会被其中一个线程成功写入(需要注意的是,具体由哪个线程完成此次写入操作,在架构层面是未定义的)。
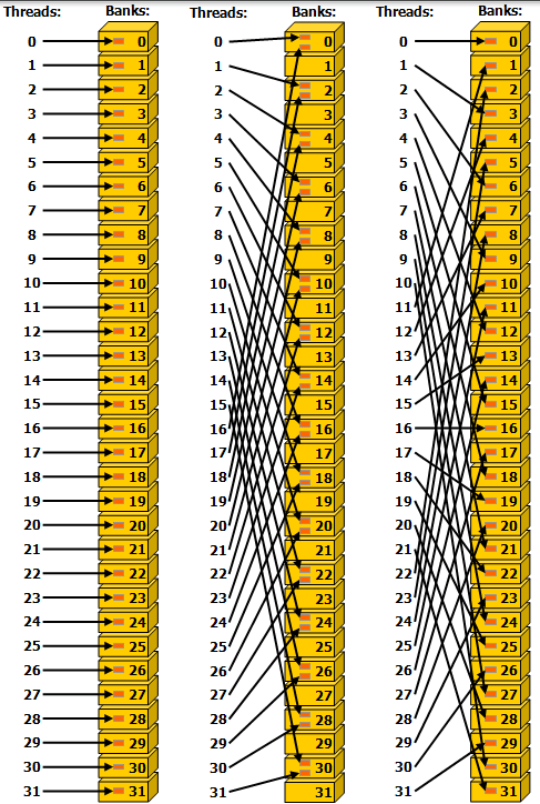
上图为32位存储体模式下的跨步共享内存访问,左图是步长为一个数据字(32位)的线性寻址,无冲突;中图是步长为两个数据字的线性寻址,存在两路存储体冲突;右图步长为三,无冲突
下图展示了一些涉及广播机制的内存读取访问示例。存储体(Bank)内部的红色方框代表共享内存中的一个唯一位置。如果多个箭头指向同一个位置,则该数据将广播给所有请求它的线程。
3.2.1 矩阵转置案例
在前面的“基于全局内存的矩阵转置示例”中,展示了一种朴素(Naive)的矩阵转置实现方法。尽管该方法在功能逻辑上是正确的,但由于对目标矩阵 c 的写入操作未能实现正确的合并访存,因此并未针对全局内存的高效利用进行优化。在本示例中,共享内存将被视为一种由用户自主管理的缓存。它被用来暂存(Stage)来自全局内存的读取(Loads)和写入(Stores)操作,从而确保对全局内存的读取和写入均能实现合并访问。
/* definitions of thread block size in X and Y directions */
#define THREADS_PER_BLOCK_X 32
#define THREADS_PER_BLOCK_Y 32
/* macro to index a 1D memory array with 2D indices in row-major order */
/* ld is the leading dimension, i.e. the number of columns in the matrix */
#define INDX( row, col, ld ) ( ( (row) * (ld) ) + (col) )
/* CUDA kernel for shared memory matrix transpose */
__global__ void smem_cuda_transpose(int m, float *a, float *c )
{
/* declare a statically allocated shared memory array */
__shared__ float smemArray[THREADS_PER_BLOCK_X][THREADS_PER_BLOCK_Y];
/* determine my row tile and column tile index */
const int tileCol = blockDim.x * blockIdx.x;
const int tileRow = blockDim.y * blockIdx.y;
/* read from global memory into shared memory array */
smemArray[threadIdx.x][threadIdx.y] = a[INDX( tileRow + threadIdx.y, tileCol + threadIdx.x, m )];
/* synchronize the threads in the thread block */
__syncthreads();
/* write the result from shared memory to global memory */
c[INDX( tileCol + threadIdx.y, tileRow + threadIdx.x, m )] = smemArray[threadIdx.y][threadIdx.x];
return;
} /* end smem_cuda_transpose */上述示例中所展示的根本性性能优化,在于确保在访问全局内存时,内存访问能够被正确地合并。在执行数据拷贝操作之前,每个线程都会计算其对应的 tileRow(分块行)和 tileCol(分块列)索引。这些索引定义了当前线程块所要操作的具体分块(Tile)位置,并且这些分块索引是基于正在执行的线程块编号计算得出的。
同一线程块中的所有线程都拥有相同的 tileRow 和 tileCol 值,因此这两个值可以被视为该特定线程块负责操作的分块起始位置。
随后,核函数开始执行拷贝操作:每个线程块负责通过以下语句,将矩阵中一个 32 × 32 的分块从全局内存拷贝到共享内存。由于一个线程束(Warp)的大小为 32 个线程,这次拷贝操作将由 32 个线程束共同完成(即 $32 \times 32 \div 32 = 32$),且这些线程束之间的执行顺序是不确定的。
smemArray[threadIdx.x][threadIdx.y] = a[INDX( tileRow + threadIdx.y, tileCol + threadIdx.x, m )];请注意,由于 threadIdx.x 出现在 INDX 宏的第二个参数中,连续的线程正在访问内存中的连续元素,因此对数组 a 的读取操作是完美合并的。
核函数的下一步是调用 __syncthreads() 函数。该函数确保线程块中的所有线程在继续执行后续代码之前,都已完成了前面代码的运行,从而保证将 a 写入共享内存的操作在进入下一步之前已经彻底完成。这一点至关重要,因为接下来的步骤涉及线程从共享内存中读取数据。如果没有 __syncthreads() 调用,就无法保证线程块中的所有线程束在某些线程束向代码深处推进之前,都已经完成了将数据存入共享内存的操作。
此时,在核函数内部,每个线程块的 smemArray(共享内存数组)都存储了一个 32 × 32 的矩阵分块,其排列顺序与原始矩阵完全一致。为了确保分块内的元素被正确转置,线程在读取 smemArray 时交换了 threadIdx.x 和 threadIdx.y 的位置。同时,为了确保整个分块被放置在目标矩阵 c 中的正确位置,在写入 c 时也交换了 tileRow 和 tileCol 索引。为了确保写入时的合并性(Coalescing),threadIdx.x 被用作 INDX 宏的第二个参数,如下面的语句所示。
c[INDX( tileCol + threadIdx.y, tileRow + threadIdx.x, m )] = smemArray[threadIdx.y][threadIdx.x];该核函数展示了共享内存的两种常见用途:
- 数据暂存以实现合并访存:共享内存被用作从全局内存到处理核心之间的中转站,以确保对全局内存的读取和写入操作都能正确实现合并。
- 块内数据共享:共享内存被用于允许同一个线程块(Thread Block)中的线程之间相互共享数据。
3.2.2 共享内存块冲突问题
上面我们描述了共享内存的存储体结构。在之前的矩阵转置示例中,我们成功实现了往返于全局内存的正确合并访存,但并未考虑是否存在共享内存存储体冲突,请考虑以下二维共享内存声明:
__shared__ float smemArray[32][32];由于一个线程束(Warp)包含 32 个线程,在同一个线程束中,所有线程的 threadIdx.y 值是固定的,而 threadIdx.x 的取值范围则为 $0 \le threadIdx.x < 32$。
图 15 的左侧面板展示了当线程束中的线程访问 smemArray 的某一列时的情况。此时,线程束 0 正在访问从 smemArray[0][0] 到 smemArray[31][0] 的内存位置。在 C++ 多维数组的存储顺序中,最后一个索引变化最快(行主序),因此线程束 0 中的连续线程所访问的内存位置在物理上相隔了 32 个元素。如图中所示,颜色代表不同的存储体(Banks);线程束 0 这种纵贯整列的访问模式导致了 32 路存储体冲突。
图 15 的右侧面板展示了当线程束中的线程访问 smemArray 的某一行时的情况。此时,线程束 0 正在访问从 smemArray[0][0] 到 smemArray[0][31] 的内存位置。在这种情况下,线程束 0 中的连续线程所访问的是彼此相邻的内存位置。如图中所示,颜色代表不同的存储体;线程束 0 这种横跨整行的访问模式不会产生任何存储体冲突。理想的场景是让线程束中的每个线程都访问带有不同颜色的共享内存位置。
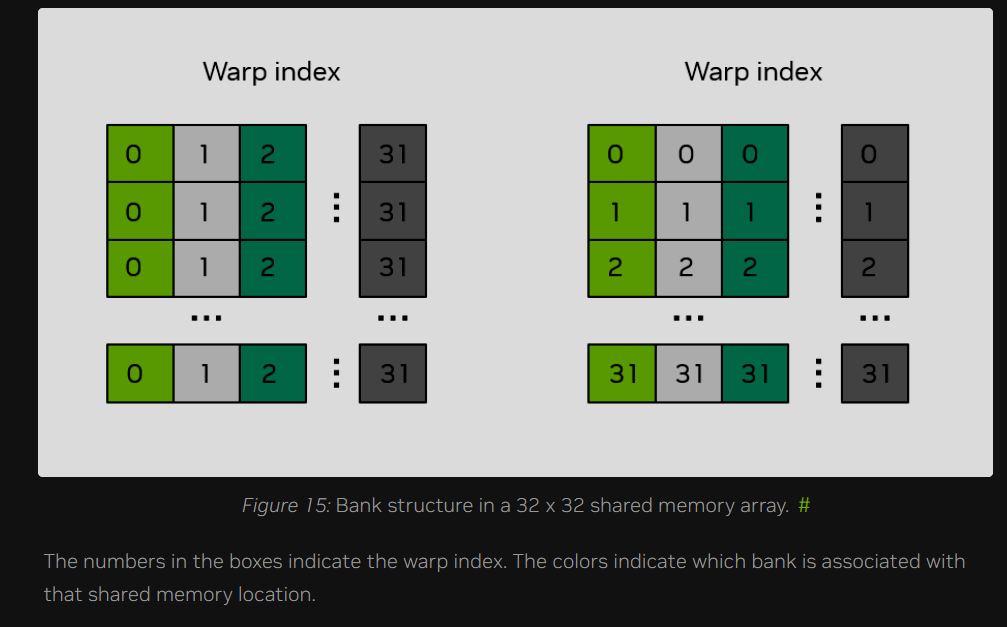
回到 3.2.1 节的示例,我们可以通过检查共享内存的使用情况,来确定是否存在存储体冲突。
1. 写入阶段:产生冲突 共享内存的首次使用,是将数据从全局内存存储到共享内存中: smemArray[threadIdx.x][threadIdx.y] = a[INDX( tileRow + threadIdx.y, tileCol + threadIdx.x, m )];
由于 C++ 数组是按行主序存储的,同一线程束(Warp)中连续的线程(由连续的 threadIdx.x 值表示)将以 32 个元素为步长访问 smemArray。这是因为 threadIdx.x 被用作了该数组的第一个索引(行索引)。这种访问模式会导致 32 路存储体冲突,如图 15 的左侧面板所示。
2. 读取阶段:无冲突 共享内存的第二次使用,是将数据从共享内存写回全局内存: c[INDX( tileCol + threadIdx.y, tileRow + threadIdx.x, m )] = smemArray[threadIdx.y][threadIdx.x];
在这种情况下,由于 threadIdx.x 成为了 smemArray 数组的第二个索引(列索引),同一线程束中的连续线程将以 1 个元素为步长访问 smemArray(即访问相邻地址)。这种模式不会产生任何存储体冲突,如图 15 的右侧面板所示。
因此,上述矩阵转置核函数中包含一次无冲突的共享内存访问,以及一次引发 32 路存储体冲突的访问。为了避免此类冲突,一个通用的修复方案是对共享内存进行填充(Pad),即在数组的列维度上增加 1,声明如下:
__shared__ float smemArray[THREADS_PER_BLOCK_X][THREADS_PER_BLOCK_Y + 1];
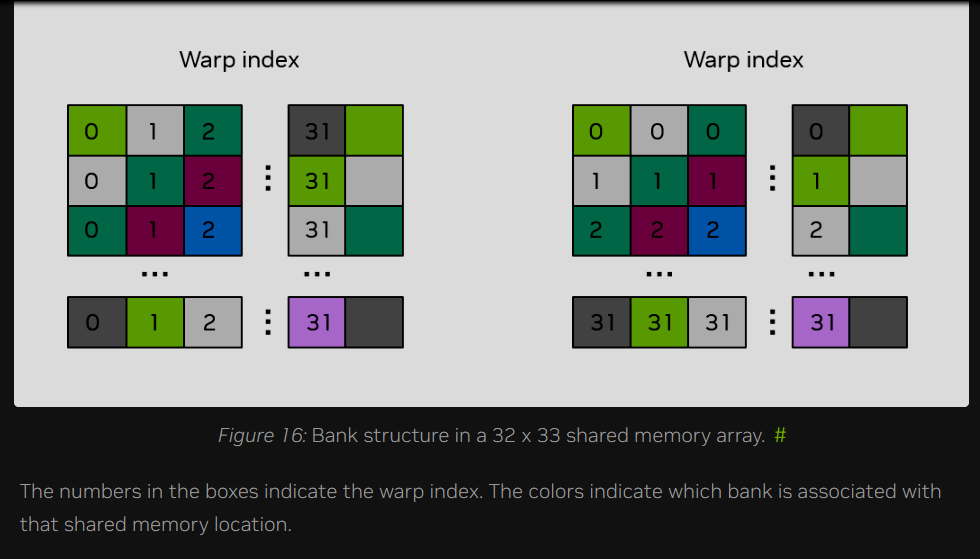
对 smemArray 的声明进行这一微小的调整,即可彻底消除存储体冲突。为了说明这一点,请参考图 16,其中共享内存数组的大小被声明为 32 × 33。可以观察到,无论同一个线程束(Warp)中的线程是沿着整列访问还是横跨整行访问该共享内存数组,存储体冲突都已不复存在——也就是说,同一线程束中的线程所访问的内存位置对应着不同的颜色(即不同的存储体)。
4.原子性操作
高性能 CUDA 核函数的构建基石在于最大化算法的并行度与维持线程的独立性。然而,在复杂的算法场景中,线程间的数据交互不可避免。虽然 CUDA 允许单一线程块内的线程通过共享内存实现同步,但在架构层面,不存在能够直接同步整个网格中所有线程的机制。
为了突破网格级别的同步限制并安全访问全局内存,CUDA 引入了原子函数。该机制允许单个线程在特定的全局内存地址上获取排他性的“锁”,进而执行不可分割的“读取-修改-写入”操作。在锁被持有的生命周期内,硬件严格禁止任何其他线程访问该目标地址,从而从根本上避免了多线程并发写入时的数据竞争与覆盖。
CUDA 提供了与 C++ 标准库原子操作行为一致的 cuda::std::atomic 和 cuda::std::atomic_ref。此外,CUDA 还提供了扩展的 C++ 原子操作 cuda::atomic 和 cuda::atomic_ref,它们允许用户指定原子操作的线程作用域(Thread Scope)。有关原子函数的详细细节将在“原子函数”章节中涵盖。
下面是一个使用 cuda::atomic_ref 执行设备范围(Device-wide)原子加法的示例。其中 array 是一个浮点数数组,而 result 是指向全局内存位置的浮点数指针,该位置将用于存储数组的总和。
__global__ void sumReduction(int n, float *array, float *result) {
...
tid = threadIdx.x + blockIdx.x * blockDim.x;
cuda::atomic_ref<float, cuda::thread_scope_device> result_ref(result);
result_ref.fetch_add(array[tid]);
...
}5.核函数启动与占用率
当 CUDA 核函数启动时,硬件调度器(Scheduler)根据执行配置将线程块分配至各个流多处理器(SM)。开发者必须明确:应用程序无法控制或查询特定的线程块被分配到哪个 SM,且调度器不提供任何执行顺序保证。这种设计要求算法逻辑必须具备高度的独立性,严禁依赖任何特定的调度顺序或预设的执行方案来维持结果的正确性。
一个 SM 能同时承载的线程块数量并非固定值,而是取决于资源匹配度:
- 资源约束:单个线程块所需的寄存器数量、共享内存大小以及线程总数,必须与 SM 现有的空闲硬件资源相匹配。
- 分配逻辑:核函数启动初期,调度器会扫描所有 SM,只要某 SM 拥有足够的未占用资源,就会持续向其压入线程块。
调度过程遵循动态负载均衡。当所有 SM 的资源容量均达到饱和、无法再接纳新的线程块时,调度器将进入等待状态。直到某 SM 完成并释放了先前分配的线程块资源,调度器才会立即填补空缺,将后续的线程块压入该 SM。这一“执行-释放-再分配”的循环过程,是确保 GPU 大规模并行任务能够有序推进至最终完成的关键底层逻辑。
cudaGetDeviceProperties 函数允许应用程序通过设备属性(Device Properties) 来查询每个流多处理器(SM)的硬件限制。需要注意的是,这些限制分为每 SM 级和每线程块级两个层面。
maxBlocksPerMultiProcessor:每个 SM 能够同时驻留(Resident)的最大线程块数量。sharedMemPerMultiprocessor:每个 SM 可用的共享内存总量(单位:字节)。regsPerMultiprocessor:每个 SM 可用的 32 位寄存器总数。maxThreadsPerMultiProcessor:每个 SM 能够同时驻留的最大线程总数。sharedMemPerBlock:单个线程块可以分配的最大共享内存量(单位:字节)。regsPerBlock:单个线程块可以分配的最大 32 位寄存器数量。maxThreadsPerBlock:单个线程块允许包含的最大线程数量。
CUDA 核函数的占用率(Occupancy) 是指:活跃线程束的数量与 SM 所能支持的最大活跃线程束数量之比。通常情况下,保持尽可能高的占用率是一项良好的编程实践,因为这有助于隐匿指令延迟并提升整体性能。
为了计算占用率,开发者需要了解前文所述的 SM 资源限制,同时还需要明确该 CUDA 核函数本身所消耗的资源量。为了确定每个核函数的资源使用情况,在程序编译阶段,可以使用 nvcc 编译器的 --resource-usage 选项。该选项将显示该核函数运行所需的寄存器数量和共享内存大小。
为了进一步说明,请考虑一个计算能力(Compute Capability)为 10.0 的设备,其设备属性详见表 2。
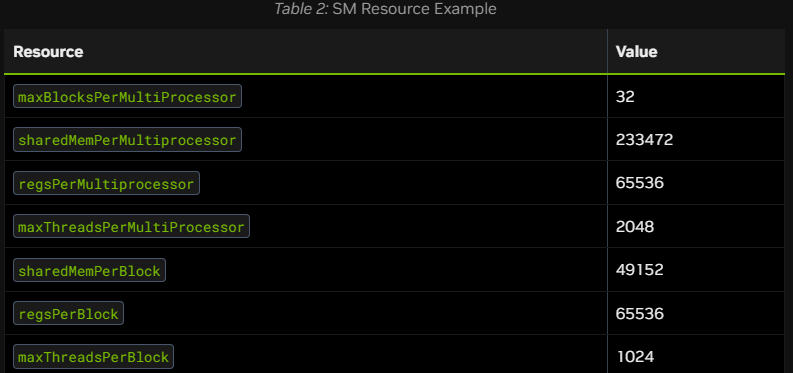
如果一个核函数以 testKernel<<<512, 768>>>() 的配置启动(即每块 768 个线程),每个 SM 每次只能执行 2 个线程块。调度器无法为每个 SM 分配超过 2 个块,因为 maxThreadsPerMultiProcessor(每 SM 最大线程数)的限制是 2048。在这种情况下,占用率将是 $(768 \times 2) / 2048 = 75%$。
如果核函数以 testKernel<<<512, 32>>>() 的配置启动(即每块 32 个线程),虽然每个 SM 不会触及 maxThreadsPerMultiProcessor 的限制,但由于 maxBlocksPerMultiProcessor(每 SM 最大线程块数)的限制是 32,调度器每个 SM 只能分配 32 个线程块。由于每个块只有 32 个线程,SM 上驻留的总线程数将是 $32 \text{ 块} \times 32 \text{ 线程/块} = 1024$ 个总线程。对于计算能力 10.0 的 SM,其最大驻留线程数为 2048,因此在这种情况下,占用率仅为 $1024 / 2048 = 50%$。
同样的分析也适用于共享内存。例如,如果一个核函数使用 100KB 的共享内存,调度器每个 SM 只能分配 2 个线程块。因为如果分配第 3 个线程块,该 SM 将需要额外的 100KB(总计 300KB),这超出了每 SM 可用的 233,472 字节(约 228KB)的限制。
每个线程块的线程数和每个线程块的共享内存使用量是由程序员显式控制的,可以进行调整以达到理想的占用率。程序员对寄存器使用量的控制相对有限,因为编译器和运行时会尝试优化寄存器的分配。然而,程序员可以通过 nvcc 的 --maxrregcount 选项指定每个线程可用的最大寄存器数量。如果核函数需要的寄存器超过了此设定值,多出的数据可能会溢出(Spill)到局部内存(Local Memory)中,这将改变核函数的性能特征。在某些情况下,尽管发生了溢出,但限制寄存器数量可以允许调度更多的线程块,从而提高占用率,并可能带来最终的性能净增长。