前言
FEMU(Flash Emulator)是一个基于 QEMU 开发的、开源的高性能 SSD 模拟器,主要用于闪存存储系统的学术研究和原型设计。它能够模拟多种 SSD 内部架构(如通道、存储体级并行性)和高级特性(如 Open-Channel SSD、ZNS 以及计算存储),并通过高度优化的内部逻辑提供极低的模拟延迟,使其既能像真实硬件一样运行真实的操作系统和应用程序,又能通过参数配置方便地测试不同的闪存管理算法(FTL)
FEMU的开源仓库为:https://github.com/MoatLab/FEMU
本文重要的参考资料为:https://jianyue.tech/posts/femu/#%E7%BC%96%E8%AF%91%E5%92%8C%E8%BF%90%E8%A1%8C
本文前提知识:
- NVMe协议
- 计算机体系结构
注:本文所涉及到的代码分析均以blackbox ssd为例
环境配置
大体上跟着官方仓库的步骤去做即可,分享两个踩过的坑:
- grub文件是在VM中修改的,千万不要修改宿主机上的grub
- 配置完成并启动
./run_blackbox.sh之后,在另一个终端窗口输入ssh -p 8080 username@localhost无法连接,可以尝试使用指令ssh -v -p 8080 -o PubkeyAuthentication=no -o PreferredAuthentications=password -o PasswordAuthentication=yes -t femu@127.0.0.1去连接
fio测试
在VM中安装fio之后,推荐采用以下命令进行fio测试:
# 延迟测试,延迟测得最小 sudo fio --ioengine=libaio --numjobs=1 --direct=1 --time_based --group_reporting --size=4G --bs=4k --iodepth=1 --filename=/dev/nvme0n1 --name=4krandwrite --rw=randwrite # 带宽测试,带宽测得最大 sudo fio --ioengine=libaio --numjobs=1 --direct=1 --time_based --group_reporting --size=4G --bs=128k --iodepth=128 --filename=/dev/nvme0n1 --name=4krandwrite --rw=randwrite # iops测试,iops测得最大 sudo fio --ioengine=libaio --numjobs=1 --direct=1 --time_based --group_reporting --size=4G --bs=4k --iodepth=128 --filename=/dev/nvme0n1 --name=4krandwrite --rw=randwrite
为什么按照上面的配置进行测试?
- 延迟测试:
- 目的:测量一次 I/O 穿透整个软硬件栈的“绝对物理底噪”
- 小块数据:4KB 是现代操作系统页大小和闪存页(Page)读写的最小标准单位。数据量越小,花费在“搬运数据”(DMA/
memcpy)上的时间就越少,测出来的就纯粹是命令处理的时间 + 闪存介质寻址的物理时间。 - 单请求:
iodepth=1保证了整个测试过程中绝对没有排
- 带宽测试:
- 目的:榨干总线(PCIe)传输能力和闪存内部的数据吞吐极限
- 大块数据:任何一次 I/O 都有额外开销(比如敲门铃、发中断的
slat)。如果你用 4K 跑,大部分时间都用在了上述额外开销上 - 深队列:深队列保证了底层的控制器不会闲着,它会提前准备好下一个 128K
- iops测试:
- 目的:测试主控芯片的多任务并发调度能力和闪存 LUN(Die)的并行度
- 小块数据:因为我们要拼的是“处理次数”,而不是“运送重量”。数据越小,单次执行越快,在一秒内能完成的“笔数”才可能冲到最高
- 深队列:果
iodepth=1,每次只有一个 LUN 在工作,其他 LUN 都处于空闲。 当你把iodepth瞬间打到 128,这 128 个 4K 小请求会被 FTL 均匀地分配到 SSD 内部的 32 个或 64 个 LUN 上。
首先使用fio进行时延测试
fio:sudo fio --name=max_bw_test --filename=/dev/nvme0n1 --rw=write --bs=4k --direct=1 --ioengine=libaio --iodepth=1 --numjobs=16 --group_reporting --size=256M --offset_increment=128M
结果:
| type | pd_wr_lat(纳秒) | BW(MB/s) | IOPS | Lat(ns) | avg_clat(ns) | slat(ns) |
|---|---|---|---|---|---|---|
| write | 200000 | 18.2 | 4443 | 235974 | 201614 | 21490 |
| write | 20000 | 87.7 | 21.4k | 48995 | 23763 | 21360 |
| write | 0 | 135 | 33k | 31730 | 6719 | 21740 |
踩过的坑: 启动femu时,nvme01还是一个空盘,第一次做fio测试时,一定要先用写操作而不是读操作!否则无论如何修改./run_blackbox.sh的pg_rd_lat都不会看到clat变化!
具体也可以看ftl.c::ssd_read的代码,当映射表查询不到时,根本不会去使用参数pg_rd_lat去计算时延!
除了上述时延测试之外,还对其进行了带宽测试
先读预热:sudo fio --name=warmup --filename=/dev/nvme0n1 --rw=write --bs=1M --size=4G --direct=1
fio:sudo fio --name=max_bw_test --filename=/dev/nvme0n1 --rw=read --bs=128k --direct=1 --ioengine=libaio --iodepth=128 --numjobs=16 --group_reporting --size=4G
修改fio选项得到以下三组数据:
| pd_rd_lat(ns) | size | Lat(ms) | BW(MB/s) | avgslat(ms) | avgclat(ms) |
|---|---|---|---|---|---|
| 800000 | 4G×16 | 209711 | 328 | 0.071 | 818 |
| 40000 | 4G×16 | 47688 | 1441 | 0.034 | 175 |
| 0 | 4G×16 | 37428 | 1836 | 0.031 | 136 |
备注:带宽=总数据量除以总时延
slat:提交时延-从用户态程序(如 fio)发起 IO 系统调用开始,到该请求成功提交给 Guest 内核驱动,并通知到模拟硬件(FEMU)为止的时间。包含
- Guest 内核开销:NVMe 驱动封装指令、管理队列。
- 虚拟化陷阱 (VM-Exit):Guest CPU 切换到 Host CPU 的物理损耗。
- 上下文切换:KVM 模块通知 QEMU 进程,FEMU 轮询线程被唤醒。
决定因素:宿主机的 CPU 性能。
clat:完成时延-请求成功提交给硬件开始,到硬件处理完数据并向 CPU 发送“任务完成”中断为止的时间。包含
- 物理搬运时间:我们讨论过的
backend_rw执行memcpy的时间。 - FTL 逻辑计算:地址映射、垃圾回收逻辑执行。
- 时延拦截 (Timing):FEMU 故意“憋”着请求,直到达到你配置的
pg_rd_lat。
决定因素:你的 SSD 配置参数 和 宿主机内存带宽。
从上面两组测试中,我们可以发现,在模拟器(尤其是基于 QEMU 的 FEMU)中,性能测试往往会碰到一个“天花板”,例如,即使把虚拟机的通道数加到无限大、延迟调到 1ns,带宽、时延等结果也无法突破某个数值。
这种“慢设备无法模拟快设备”的现象,本质上受限于软件模拟器的指令集循环开销与宿主机物理时钟的分辨率。在 FEMU 这样的模拟器中,每一个虚拟的 NVMe 寄存器操作或数据拷贝指令,最终都要转化为宿主机物理 CPU 上的多条实际指令。当你在软件中将延迟设定为 10\text{ns} 时,由于 CPU 逻辑跳转、内存上下文切换以及虚拟化层(KVM/QEMU)的中断拦截开销,宿主机处理这笔请求所需的物理时间往往已经达到了数百纳秒甚至微秒级别。
从时钟同步的角度来看,由于宿主机操作系统的调度颗粒度(通常在微秒量级)远粗于你所设定的纳米级延迟,模拟器内部的定时器精度成为了第二道锁。即使模拟逻辑在指令层面“认为”只过去了 10\text{ns},但在等待宿主机硬件产生时钟中断来唤醒 IO 线程时,真实的物理时间已经流逝了成千上万个时钟周期。这种“时间膨胀”效应导致模拟器在单位时间内能处理的 IO 数量被锁死在宿主机的单核处理能力上。
此外,数据通路的序列化瓶颈也限制了带宽的无限增长。虽然物理 SSD 可以通过增加 NAND 通道实现并行加速,但在模拟器内部,即便你配置了 16 个通道,这些通道的逻辑往往仍是在宿主机的少数几个线程中串行或分时竞争执行的。由于 QEMU 存在全局锁机制或单线程 IO 派发限制,多出来的虚拟通道只是增加了软件逻辑的复杂度,并不能真正突破宿主机内存带宽与总线处理的单点物理瓶颈。因此,当你看到的带宽卡在 2.2\text{GB/s} 左右时,那其实已经触碰到了宿主机 CPU 模拟 NVMe 协议栈并进行内存数据搬运的“物理极限”,再增加模拟侧的并发参数也只是在原地空转。
代码分析
FEMU的三种地址空间
PCI配置空间
相当于PCI设备的身份证,在实际场景中,它是烧录在 PCIe 设备芯片内部的一小块寄存器(传统 256 字节,PCIe 扩展到 4KB),包含了设备的 Vendor ID、Device ID 等只读信息,以及 6 个 BAR(基址寄存器)等可写信息。当主板 BIOS 和操作系统开机时,通过读取这里来发现设备,并向 BAR 中写入地址,完成设备的内存映射分配。
在FEMU中,是 QEMU 进程内存中的一段 C 语言结构体,FEMU 默认不干预它,直接使用 QEMU 底层通用的 PCI 协议代码来应对操作系统的扫描。但开发者可以通过重写 pc->config_write 函数,拦截操作系统分配地址的瞬间,以注入自定义逻辑。
PCI BAR MMIO空间
相当于消息触发器,在实际场景中,它不消耗真实的内存条容量,而是占据了 CPU 物理地址空间中的一段(地址编码),内存控制器会将发往这段地址的电信号,直接路由到 PCIe 总线上,直达 NVMe 控制器的内部寄存器,对于 NVMe,它通常只有 16KB,分为前 4KB 的“全局配置寄存器”和后面12KB的“门铃寄存器(Doorbell)”,每对门铃寄存器需要8B,每个门铃寄存器只使用低16位,也就是可以包含65536个指令。
在FEMU中,是向 QEMU 注册的一块虚拟内存区域,当虚拟机 OS 往这段地址写数据时,会触发 VM Exit,QEMU 捕获后会调用 FEMU 提前绑定的回调函数:nvme_mmio_read() 和 nvme_mmio_write()。FEMU 在这两个函数里解析“是在改配置”还是“在敲门铃”。
DMA空间
是真正存放指令和海量数据的“物理仓库”。在实际场景中,它是实实在在插在主板上的 RAM上存储的内容,无论是 64 字节的指令(SQE)、16 字节的状态反馈(CQE),还是几 MB、几 GB 的实际文件数据,都存放在这里。NVMe 硬件内部的 DMA 引擎会通过 PCIe 总线直接读写这片内存,全程不需要 CPU 搬运数据。
在FEMU中,它是宿主机(Host OS)分配给 QEMU 进程的一大块普通虚拟内存,FEMU 利用同一进程地址空间的优势,通过带有 _hva(宿主机虚拟地址)后缀的 C 语言指针,直接调用 memcpy 或者直接赋值操作来读写这块内存。这种“伪 DMA”绕过了复杂的总线模拟,是 FEMU 能够实现极高 IOPS 的核心原因。
完整例子:
第一阶段:建联与扩建 —— “划分多条独立车道” (DMA & MMIO)
假设操作系统分配了 4 个 CPU 核心来处理存储任务。为了不让这 4 个核心互相打架(锁竞争),驱动程序会为它们各自建立一条专线。(核心数不一定等于io队列数,但理想情况下应该相同)
1. 主存划分(DMA空间):驱动程序在 RAM 中开辟了 4 对相互独立的 IO 队列:SQ1/CQ1, SQ2/CQ2, SQ3/CQ3, SQ4/CQ4。
2. 门铃分配(MMIO空间):驱动程序将这 4 个队列的物理基地址告诉硬盘;16KB 的 MMIO 空间中,立刻被激活了 4 对专属门铃。它们的地址是错开的:核心 1 专属:0x1008 (SQ1 门铃);核心 2 专属:0x1010 (SQ2 门铃);核心 3 专属:0x1018 (SQ3 门铃);核心 4 专属:0x1020 (SQ4 门铃)
第二阶段:批量起草运单 —— “挑战队列深度” (写 DMA 空间)
现在,这 4 个核心同时接到了一大批并发读写任务(比如压测工具瞬间下发了大量随机读请求)。
- 局部堆积指令:核心 1 不会写 1 条指令就去按门铃。它在 RAM 的
SQ1中连续写下 32 条指令(占据 32 \times 64 = 2048 字节的主存空间),分别指向 32 个不同的数据缓冲区;同时,核心 2 在SQ2中连续写了 64 条指令;核心 3 在SQ3中连续写了 16 条指令;核心 4 在SQ4中连续写了 32 条指令。
第三阶段:同时扣动扳机 —— “多声部交响乐” (写 MMIO 空间)
指令在主存里备齐了,接下来是 16KB MMIO 空间的“高光时刻”。
- 多重瞬时写入:核心 1 向 MMIO
0x1008写入数字32(意思是:我的尾指针到 32 了,这 32 条你全拿走);核心 2 向 MMIO0x1010写入数字64;核心 3 向 MMIO0x1018写入数字16;核心 4 向 MMIO0x1020写入数字32。
第四阶段:多路并发海量搬运 —— “火力全开” (硬件 DMA 执行)
此时,硬盘控制器(或 FEMU 的处理线程)看到 4 个门铃同时响了,且数字都不小。真正的性能怪兽苏醒了。
- 批量吸取指令(控制流DMA):硬盘启动内部的 DMA 引擎,顺着 4 个队列的基地址,分别去 RAM 里把那 32 条、64 条、16 条、32 条指令(共 144 条 SQE)全部抓取到硬盘内部的缓存中。
- 闪存并发读取(数据流DMA):硬盘内部的控制器打乱这些指令的顺序,利用其内部多达几十个闪存通道(Channels)和晶粒(Dies),同时去底层物理介质的 144 个不同位置取货;只要取出一块数据,DMA 引擎就立刻将其“射入”指令指定的主存数据缓冲区中。此时的主板内存总线上,数据如狂风暴雨般涌入。
- 批量交差(写CQ与门铃反馈):核心 1 的 32 个任务完成后,硬盘向 RAM 的
CQ1连续写入 32 个完成状态(CQE),然后向主机发一个中断;主机核心 1 醒来,处理完这 32 个结果后,它需要向 MMIO 的完成队列门铃 (CQ1 Head Doorbell, 比如0x100C)写入32,告诉硬盘:“这 32 个结果我看到了,你可以把 RAM 里对应的 CQ 槽位清空了。”
NVMe shadow Doorbell Buffer
在纯物理世界中,主机(CPU/内存)和 SSD(NVMe 控制器)是两个不同的物理实体,它们各自有不同的地址空间。主机必须通过 PCIe 总线上的 MMIO(内存映射 I/O) 去跨界敲击 SSD 芯片上的物理寄存器,而MMIO本身会触发VM Exit,产生较大的开销。
但在虚拟化(如 FEMU/QEMU)中,虚拟机的内存(Host RAM)和模拟的 NVMe 控制器(FEMU 进程)其实都在宿主机的同一块物理内存条上,没有必要假装走耗时MMIO,于是主机直接在自己的RAM里划出一块普通内存,作为与NVMe控制器的连接点,由于写普通RAM不会触发VM Exit,因此避开了虚拟化最大的性能开销。
上述这段内存划分成两个数组:shadow doorbell buffer和eventidx buffer。前者被主机写:当主机产生新的I/O请求(SQE)时,不再真正地去通过MMIO敲SSD内的门铃,而是直接把最新的队列尾指针写到这个内存数组中;后者被NVMe控制器(FEMU)写,用来记录控制器目前已经看到并准备处理的SQ Tail进度。
假设主机准备提交新任务。提交前,当前的尾指针是 db_tail_old,主机放入任务后,新的尾指针变成了 db_tail_new,此时看一眼控制器留下的进度牌:eventidx_tail,那么当db_tail_old <= eventidx_tail < db_tail_new时,才会触发真正地通过MMIO按门铃。例如,当eventidx_tail < db_tail_old,控制器既然还在处理旧任务,它处理完旧任务后,必然会顺手去读取一下 Shadow Doorbell,它自然而然就会发现新增的任务。提前吵醒它毫无意义,反而浪费 CPU。
总之,在极高负载(比如每秒百万次随机读写,1M IOPS)的情况下:
- 没有这个特性:主机每秒要执行 100 万次 MMIO 写,触发 100 万次 VM Exit。宿主机 CPU 全部用来处理上下文切换,系统直接崩溃。
- 有这个特性:主机一直往 Shadow Doorbell 写数据,而 NVMe 控制器一直在后台疯狂轮询。因为
eventidx_tail总是落后于进度,所以那条“唤醒不等式”永远不成立。结果是:100 万次 I/O,触发的 VM Exit 次数几乎等于 0!
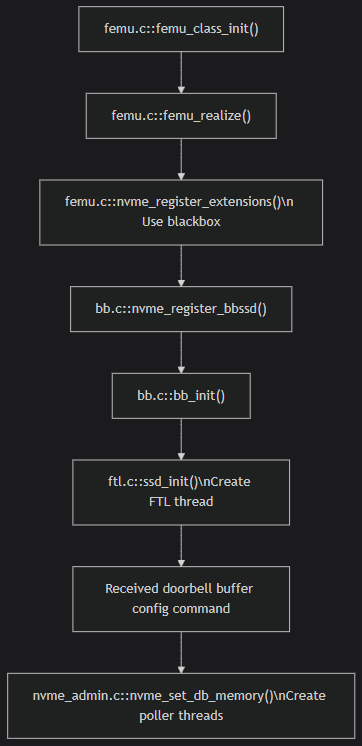
FEMU的初始化流程
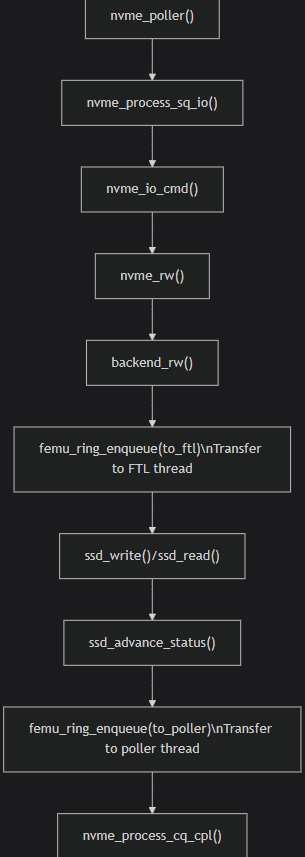
FEMU的IO流程
这一部分的具体代码注释见附录
附录:IO处理流程核心代码全注释
nvme-io.c::nvme_poller
/** * NVMe poller线程函数 * 功能:不断检查虚拟机是否提交了SQ,并检查后端是否返回了CQ */ void *nvme_poller(void *arg) { // 从参数中获得控制器对象和当前poller线程的索引 FemuCtrl *n = ((NvmePollerThreadArgument *)arg)->n; int index = ((NvmePollerThreadArgument *)arg)->index; int i;/** * 根据是否开启了多轮询器模式进入不同的处理逻辑 * 如果开启,每个poller线程只处理对应索引的一组SQ/CQ * 如果不开启,一个poller线程要处理所有的SQ/CQ */ switch (n->multipoller_enabled) { case 1: while (1) { // 如果虚拟机还没完全启动或NVMe还没初始化好,就先睡眠一段时间,防止空转 if ((!n->dataplane_started)) { usleep(1000); continue; } // 在多线程模式下,Poller[index]只负责SQ[index]和CQ[index] NvmeSQueue *sq = n->sq[index]; NvmeCQueue *cq = n->cq[index]; // 队列激活并有新指令的情况下,处理SQ的IO请求 if (sq && sq->is_active && cq && cq->is_active) { nvme_process_sq_io(sq, index); } // 看FTL线程有没有已经完成的任务 nvme_process_cq_cpl(n, index); } break; default: while (1) { if ((!n->dataplane_started)) { usleep(1000); continue; } // 遍历所有IO队列,依次每个队列是否有新指令需要处理 for (i = 1; i <= n->nr_io_queues; i++) { NvmeSQueue *sq = n->sq[i]; NvmeCQueue *cq = n->cq[i]; if (sq && sq->is_active && cq && cq->is_active) { // 所有的SQ请求都在这个index线程里处理,可能会有性能瓶颈,但实现简单 nvme_process_sq_io(sq, index); } } nvme_process_cq_cpl(n, index); } break; } return NULL;
}
nvme-io.c::nvme_process_sq_io
/** * 处理SQ的IO指令 * @opaque: 传入的参数,实际是NvmeSQueue指针 * @index_poller: 当前poller线程的索引,用于区分多线程下的不同to_ftl队列 */ static void nvme_process_sq_io(void *opaque, int index_poller) { NvmeSQueue *sq = opaque; FemuCtrl *n = sq->ctrl;uint16_t status; hwaddr addr; // 存储指令在虚拟机物理内存的地址 NvmeCmd cmd; // 局部变量,用于存储从虚拟机内存中抓取的64字节SQE NvmeRequest *req; // 指向FEMU内部的请求结构体,用于后续处理和记录请求状态 int processed = 0; // 记录本轮轮询处理的指令条数 // 更新尾指针,检查虚拟机是否写入了新的Doorbell,从而更新控制器内存中的tail nvme_update_sq_tail(sq); while (!(nvme_sq_empty(sq))) { // 提取指令(SQE)地址,支持物理连续和非连续两种情况 if (sq->phys_contig) { // 情况A:队列在物理内存中是连续的 // 计算指令地址:队列基地址 + (head索引 * SQE大小) 其中sq->dma_addr是虚拟机的物理地址(gpa),sq->dma_addr_hva是FEMU映射到宿主机的虚拟地址(hva) addr = sq->dma_addr + sq->head * n->sqe_size; // 直接从宿主机映射的虚拟地址复制64字节 nvme_copy_cmd(&cmd, (void *)&(((NvmeCmd *)sq->dma_addr_hva)[sq->head])); } else { // 情况B:队列在物理内存中是非连续的,使用PRP列表进行地址转换,具体暂不注释 addr = nvme_discontig(sq->prp_list, sq->head, n->page_size, n->sqe_size); nvme_addr_read(n, addr, (void *)&cmd, sizeof(cmd)); } // 更新头指针,准备处理下一个指令 nvme_inc_sq_head(sq); // 内部req对象初始化 // 从预分配的请求空闲链表中取出一个托盘 req = QTAILQ_FIRST(&sq->req_list); QTAILQ_REMOVE(&sq->req_list, req, entry); // 重置请求状态,清除之前的旧数据 memset(&req->cqe, 0, sizeof(req->cqe)); req->dsm_ranges = NULL; req->dsm_nr_ranges = 0; req->dsm_attributes = 0; // 记录关键时间戳,用于后续的时延模拟 // stime:记录请求开始被处理的时间点(纳秒) // expire_time:初始等于开始时间,后续ftl会在此基础上加上模拟的闪存延迟 /* Coperd: record req->stime at earliest convenience */ req->expire_time = req->stime = qemu_clock_get_ns(QEMU_CLOCK_REALTIME); // 绑定id和操作码 req->cqe.cid = cmd.cid; // 命令id,完工时回传给虚拟机 req->cmd_opcode = cmd.opcode; // 操作码,记录操作类型 memcpy(&req->cmd, &cmd, sizeof(NvmeCmd)); if (n->print_log) { femu_debug("%s,cid:%d\n", __func__, cmd.cid); } // 分发指令进行初步处理,对于不同类型的ssd,绑定了不同的处理函数,在nvme_register_extensions中设置 status = nvme_io_cmd(n, &cmd, req); if (status == NVME_SUCCESS) { req->status = status; // 将处理好的请求放入到对应的to_ftl队列中,等待后续的时延模拟和完成处理 // 具体处理逻辑可以看ftl_thread函数 int rc = femu_ring_enqueue(n->to_ftl[index_poller], (void *)&req, 1); if (rc != 1) { // 如果队列满了,需紧急清理资源防止内存泄漏 femu_err("enqueue failed, ret=%d\n", rc); // Clean up DSM ranges on enqueue failure if (req->dsm_ranges) { g_free(req->dsm_ranges); req->dsm_ranges = NULL; req->dsm_nr_ranges = 0; } } } else { femu_err("Error IO processed! opcode=0x%x, status=0x%x\n", cmd.opcode, status); req->status = status; // Clean up DSM ranges on error if (req->dsm_ranges) { g_free(req->dsm_ranges); req->dsm_ranges = NULL; req->dsm_nr_ranges = 0; } } processed++; } nvme_update_sq_eventidx(sq); sq->completed += processed;
}
nvme-io.c::nvme_io_cmd
static uint16_t nvme_io_cmd(FemuCtrl *n, NvmeCmd *cmd, NvmeRequest *req) { NvmeNamespace *ns; uint32_t nsid = le32_to_cpu(cmd->nsid);if (nsid == 0 || nsid > n->num_namespaces) { femu_err("%s, NVME_INVALID_NSID %" PRIu32 "\n", __func__, nsid); return NVME_INVALID_NSID | NVME_DNR; } req->ns = ns = &n->namespaces[nsid - 1]; switch (cmd->opcode) { case NVME_CMD_FLUSH: if (!n->id_ctrl.vwc || !n->features.volatile_wc) { return NVME_SUCCESS; } return nvme_flush(n, ns, cmd, req); case NVME_CMD_DSM: if (NVME_ONCS_DSM & n->oncs) { return nvme_dsm(n, ns, cmd, req); } return NVME_INVALID_OPCODE | NVME_DNR; case NVME_CMD_COMPARE: if (NVME_ONCS_COMPARE & n->oncs) { return nvme_compare(n, ns, cmd, req); } return NVME_INVALID_OPCODE | NVME_DNR; case NVME_CMD_WRITE_ZEROES: if (NVME_ONCS_WRITE_ZEROS & n->oncs) { return nvme_write_zeros(n, ns, cmd, req); } return NVME_INVALID_OPCODE | NVME_DNR; case NVME_CMD_WRITE_UNCOR: if (NVME_ONCS_WRITE_UNCORR & n->oncs) { return nvme_write_uncor(n, ns, cmd, req); } return NVME_INVALID_OPCODE | NVME_DNR; default: if (n->ext_ops.io_cmd) { //在这里进入下一个io函数 return n->ext_ops.io_cmd(n, ns, cmd, req); } femu_err("%s, NVME_INVALID_OPCODE\n", __func__); return NVME_INVALID_OPCODE | NVME_DNR; }
}
nvme-io.c::nvme_rw
/** * 处理读写指令的函数 * @n:当前控制器对象 * @ns:当前命名空间对象 * @cmd:从虚拟机内存中抓取的指令数据, * @req:FEMU内部的请求对象,用于记录请求状态和后续处理 */ uint16_t nvme_rw(FemuCtrl *n, NvmeNamespace *ns, NvmeCmd *cmd, NvmeRequest *req) { // 1.将通用命令结构体转换为读写命令专用的结构体 NvmeRwCmd *rw = (NvmeRwCmd *)cmd;// 2.提取并转换字节序(从虚拟机小端格式转为主机cpu格式) uint16_t ctrl = le16_to_cpu(rw->control); uint32_t nlb = le16_to_cpu(rw->nlb) + 1; // 本次IO要读写的逻辑块数量,NVMe协议中是0-based,所以要加1 uint64_t slba = le64_to_cpu(rw->slba); // 起始ssd逻辑块地址 uint64_t prp1 = le64_to_cpu(rw->prp1); // 物理区域页指针1,指向guest内存存放数据的第一个4KB物理页 uint64_t prp2 = le64_to_cpu(rw->prp2); // 物理区域页指针2或PRP列表指针 // 从命名空间获取lba格式索引,根据这个索引获取每个lba的大小(ms) const uint8_t lba_index = NVME_ID_NS_FLBAS_INDEX(ns->id_ns.flbas); // lba后面的元数据大小 const uint16_t ms = le16_to_cpu(ns->id_ns.lbaf[lba_index].ms); // 逻辑块的大小的位数 const uint8_t data_shift = ns->id_ns.lbaf[lba_index].lbads; // 本次IO设计的总数据长度(单位:字节),例如如果nlb=7,data_shift=12,那么data_size=7*4096=28672字节 uint64_t data_size = (uint64_t)nlb << data_shift; // 起始地址在ssd中绝对字节位置 uint64_t data_offset = slba << data_shift; // 元数据总大小 uint64_t meta_size = nlb * ms; uint64_t elba = slba + nlb; uint16_t err; int ret; req->is_write = (rw->opcode == NVME_CMD_WRITE) ? 1 : 0; // 检查请求是否合法,包括防止越界、对其检查等内容 err = femu_nvme_rw_check_req(n, ns, cmd, req, slba, elba, nlb, ctrl, data_size, meta_size); if (err) return err; // 将虚拟机提供的PRP地址转换为femu可以直接使用的sglist结构,方便后续直接进行DMA读写 if (nvme_map_prp(&req->qsg, &req->iov, prp1, prp2, data_size, n)) { nvme_set_error_page(n, req->sq->sqid, cmd->cid, NVME_INVALID_FIELD, offsetof(NvmeRwCmd, prp1), 0, ns->id); return NVME_INVALID_FIELD | NVME_DNR; } assert((nlb << data_shift) == req->qsg.size); req->slba = slba; req->status = NVME_SUCCESS; req->nlb = nlb; ret = backend_rw(n->mbe, &req->qsg, &data_offset, req->is_write); if (!ret) { return NVME_SUCCESS; } return NVME_DNR;
}
dram.c::backend_rw
/** * 执行底层的DMA数据读写 * @b:指向SSD后端存储的指针,包含了模拟内存分配的宿主机的DRAM空间 * @qsg:记录了数据在虚拟机内存中分散的物理地址片段 * @lbal:记录了数据在SSD后端内存中的逻辑地址 * @is_write:标识当前操作是读还是写 */ int backend_rw(SsdDramBackend *b, QEMUSGList *qsg, uint64_t *lbal, bool is_write) { // 当前正在处理sglist中的第几个内存片段 int sg_cur_index = 0;// 当前所在的内存片段内部,已经处理了多少字节 // 为什么要写?因为QEMU的底层dma_memory_rw 可能无法一次性拷完一个完整的片段 dma_addr_t sg_cur_byte = 0; // cur_addr:正在操作的虚拟机物理地址gpa // cur_len:本次准备拷贝的字节长度 dma_addr_t cur_addr, cur_len; // 数据在FEMU后端DRAM空间中的起始字节偏移量 uint64_t mb_oft = lbal[0]; // 指向FEMU为这个SSD申请的整块DRAM空间的起始虚拟地址(HVA) void *mb = b->logical_space; DMADirection dir = DMA_DIRECTION_FROM_DEVICE; if (is_write) { dir = DMA_DIRECTION_TO_DEVICE; } while (sg_cur_index < qsg->nsg) { // 正在操作的虚拟机物理地址 = 当前sg片段的起始地址 + 已经处理的字节数 cur_addr = qsg->sg[sg_cur_index].base + sg_cur_byte; // 当前片段还剩下多少字节没有搬运 cur_len = qsg->sg[sg_cur_index].len - sg_cur_byte; // QEMU提供的安全DMA访问接口:负责把虚拟机地址(cur_addr)和宿主机FEMU进程地址(mb+mb_oft)之间的数据搬运 // 为什么使用这个接口而不是memcpy?因为HVA需要经过IOMMU映射 if (dma_memory_rw(qsg->as, cur_addr, mb + mb_oft, cur_len, dir, MEMTXATTRS_UNSPECIFIED)) { femu_err("dma_memory_rw error\n"); } sg_cur_byte += cur_len; if (sg_cur_byte == qsg->sg[sg_cur_index].len) { sg_cur_byte = 0; ++sg_cur_index; } if (b->femu_mode == FEMU_OCSSD_MODE) { mb_oft = lbal[sg_cur_index]; } else if (b->femu_mode == FEMU_BBSSD_MODE || b->femu_mode == FEMU_NOSSD_MODE || b->femu_mode == FEMU_ZNSSD_MODE) { mb_oft += cur_len; } else { assert(0); } } qemu_sglist_destroy(qsg); return 0;
}
ftl.c::ftl_thread
/** * ftl核心线程 * femu后端仿真引擎,不断从前端poller线程接受请求,模拟闪存的各类操作 * 计算出对应的物理延迟,然后将请求送回前端 */ static void *ftl_thread(void *arg) { FemuCtrl *n = (FemuCtrl *)arg; struct ssd *ssd = n->ssd; NvmeRequest *req = NULL; uint64_t lat = 0; int rc; int i;while (!*(ssd->dataplane_started_ptr)) { usleep(100000); } /* FIXME: not safe, to handle ->to_ftl and ->to_poller gracefully */ ssd->to_ftl = n->to_ftl; ssd->to_poller = n->to_poller; while (1) { for (i = 1; i <= n->nr_pollers; i++) { if (!ssd->to_ftl[i] || !femu_ring_count(ssd->to_ftl[i])) continue; // 从生产者那里拿走已经经过DMA搬运好的请求 rc = femu_ring_dequeue(ssd->to_ftl[i], (void *)&req, 1); if (rc != 1) { printf("FEMU: FTL to_ftl dequeue failed\n"); } ftl_assert(req); // 物理行为仿真 // 这些函数不再板运输局(因为数据已经在前端backend_rw搬完了) // 它们只负责:1.更新映射表2.计算NAND内存的物理延迟(纳秒) switch (req->cmd.opcode) { case NVME_CMD_WRITE: lat = ssd_write(ssd, req); break; case NVME_CMD_READ: lat = ssd_read(ssd, req); break; case NVME_CMD_DSM: if (req->dsm_ranges && req->dsm_nr_ranges > 0) { lat = ssd_trim(ssd, req); } break; default: // ftl_err("FTL received unkown request type, ERROR\n"); ; } req->reqlat = lat; req->expire_time += lat; // 将请求送回前端poller线程,完成一次完整的IO请求处理 // poller线程会不断检查现在的系统时间是否已经超过了req->expire_time,只有时间到了,poller才会向虚拟机发送中断 rc = femu_ring_enqueue(ssd->to_poller[i], (void *)&req, 1); if (rc != 1) { ftl_err("FTL to_poller enqueue failed\n"); } /* clean one line if needed (in the background) */ if (should_gc(ssd)) { do_gc(ssd, false); } } } return NULL;
}
ftl.c::ssd_write(ssd_read类似,不再写)
/** * 模拟SSD的写入操作 * 返回值:执行这次写入请求的最大延迟(纳秒) */ static uint64_t ssd_write(struct ssd *ssd, NvmeRequest *req) {uint64_t lba = req->slba; // 起始逻辑块地址(这里的块是扇区) struct ssdparams *spp = &ssd->sp; // SSD的硬件参数(如每页多少个扇区、每块多少个页) int len = req->nlb; // 本次操作涉及的逻辑块总数 uint64_t start_lpn = lba / spp->secs_per_pg; // 将扇区地址转换为页地址(LPN),因为FTL是以页为单位进行映射的,例如如果每页有8个扇区,那么LBA 0-7对应LPN 0,LBA 8-15对应LPN 1,以此类推。 uint64_t end_lpn = (lba + len - 1) / spp->secs_per_pg; // 结束逻辑页号 struct ppa ppa; // 定位了这个页在物理中的实际位置 uint64_t lpn; uint64_t curlat = 0, maxlat = 0; int r; if (end_lpn >= spp->tt_pgs) { ftl_err("start_lpn=%" PRIu64 ",tt_pgs=%d\n", start_lpn, ssd->sp.tt_pgs); } // 触发垃圾回收 while (should_gc_high(ssd)) { /* perform GC here until !should_gc(ssd) */ r = do_gc(ssd, true); if (r == -1) break; } // for (lpn = start_lpn; lpn <= end_lpn; lpn++) { // 处理旧数据(闪存不可覆盖) // 查找映射表看这个逻辑页之前有没有写过 ppa = get_maptbl_ent(ssd, lpn); if (mapped_ppa(&ppa)) { // 如果之前有数据,不能覆盖,只能把旧物理页标记为无效,从而让gc回收 /* update old page information first */ mark_page_invalid(ssd, &ppa); // 更新反向映射表,记录该屋里也不再对应任何逻辑页 set_rmap_ent(ssd, INVALID_LPN, &ppa); } /* new write */ // 分配一个新的物理页来写入新数据 ppa = get_new_page(ssd); /* update maptbl */ // 记录LPN现在对应到了新的ppa set_maptbl_ent(ssd, lpn, &ppa); /* update rmap */ // 记录ppa属于哪个lpn,gc搬运数据时需要这个信息 set_rmap_ent(ssd, lpn, &ppa); // 将新页标记为有效 mark_page_valid(ssd, &ppa); // 更新ssd内部的分配位置 /* need to advance the write pointer here */ ssd_advance_write_pointer(ssd); // 硬件时延模拟 struct nand_cmd swr; swr.type = USER_IO; swr.cmd = NAND_WRITE; swr.stime = req->stime; /* get latency statistics */ // 最核心的时延计算函数 curlat = ssd_advance_status(ssd, &ppa, &swr); // 这一批page是并行/串行写入的,整个请求完成的时间取决于最慢的那一笔闪存操作 maxlat = (curlat > maxlat) ? curlat : maxlat; } return maxlat;
}
ftl.c::ssd_advance_status
/** * 模拟NAND硬件状态推进,计算物理操作延迟 * 通过维护LUN的“下一次空闲时间”来模拟排队论 * 返回值:从指令下发到操作完成的总耗时(纳秒) */ static uint64_t ssd_advance_status(struct ssd *ssd, struct ppa *ppa, struct nand_cmd *ncmd) { int c = ncmd->cmd; // 提取NAND命令类型:READ,WRITE,ERASE// 计算命令下发时间,如果用户没有指定stime,则使用当前时间 uint64_t cmd_stime = (ncmd->stime == 0) ? qemu_clock_get_ns(QEMU_CLOCK_REALTIME) : ncmd->stime; uint64_t nand_stime; // 本次nand操作实际开始的时间 struct ssdparams *spp = &ssd->sp; // 定位物理资源:根据ppa地址找到这个操作落在了哪一个具体的LUN上 // LUN是闪存内部能独立并行的最小单元 struct nand_lun *lun = get_lun(ssd, ppa); uint64_t lat = 0; switch (c) { case NAND_READ: /* read: perform NAND cmd first */ // 如果LUN现在正在忙 // 那么本次操作必须等它忙完才能开始,如果LUN闲着那现在就开始 nand_stime = (lun->next_lun_avail_time < cmd_stime) ? cmd_stime : lun->next_lun_avail_time; // 更新LUN的下一次空闲时间:下一次空闲时间=开始时间+闪存页读取物理时延 lun->next_lun_avail_time = nand_stime + spp->pg_rd_lat; // 本次操作的总延时:忙完的时间点-最初下发指令的时间点 lat = lun->next_lun_avail_time - cmd_stime;#if 0
lun->next_lun_avail_time = nand_stime + spp->pg_rd_lat;/* read: then data transfer through channel */ chnl_stime = (ch->next_ch_avail_time < lun->next_lun_avail_time) ? \ lun->next_lun_avail_time : ch->next_ch_avail_time; ch->next_ch_avail_time = chnl_stime + spp->ch_xfer_lat; lat = ch->next_ch_avail_time - cmd_stime;#endif
break;case NAND_WRITE: /* write: transfer data through channel first */ // 与上面一样,如果LUN现在正在忙,那么本次操作必须等它忙完才能开始,如果LUN闲着那现在就开始 nand_stime = (lun->next_lun_avail_time < cmd_stime) ? cmd_stime : lun->next_lun_avail_time; if (ncmd->type == USER_IO) { lun->next_lun_avail_time = nand_stime + spp->pg_wr_lat; } else { lun->next_lun_avail_time = nand_stime + spp->pg_wr_lat; } lat = lun->next_lun_avail_time - cmd_stime;#if 0
chnl_stime = (ch->next_ch_avail_time < cmd_stime) ? cmd_stime :
ch->next_ch_avail_time;
ch->next_ch_avail_time = chnl_stime + spp->ch_xfer_lat;/* write: then do NAND program */ nand_stime = (lun->next_lun_avail_time < ch->next_ch_avail_time) ? \ ch->next_ch_avail_time : lun->next_lun_avail_time; lun->next_lun_avail_time = nand_stime + spp->pg_wr_lat; lat = lun->next_lun_avail_time - cmd_stime;#endif
break;case NAND_ERASE: /* erase: only need to advance NAND status */ nand_stime = (lun->next_lun_avail_time < cmd_stime) ? cmd_stime : lun->next_lun_avail_time; lun->next_lun_avail_time = nand_stime + spp->blk_er_lat; lat = lun->next_lun_avail_time - cmd_stime; break; default: ftl_err("Unsupported NAND command: 0x%x\n", c); } return lat;
}
nvme-io.c::nvme_process_cq_cpl
/** * 推进CQ并处理已完成请求的函数 * 原理:检查ftl传回的请求,对比当前时间与请求的expire_time * 只有到点的请求才会正式结束并向guest发送中断 */ static void nvme_process_cq_cpl(void *arg, int index_poller) { FemuCtrl *n = (FemuCtrl *)arg; NvmeCQueue *cq = NULL; NvmeRequest *req = NULL;// rp:默认指向to_ftl队列,但如果是BBSSD/ZNSSD则指向to_poller队列 struct rte_ring *rp = n->to_ftl[index_poller]; // pq:按时间排序的一个优先队列,因为后到的请求可能比先到的请求更快完成,pq保证我们总是先检查最快完成的那个 pqueue_t *pq = n->pq[index_poller]; uint64_t now; int processed = 0; int rc; int i; // 如果是BBSSD/ZNSSD,数据是从ftl计算完延迟之后通过to_poller队列送回来的 if (BBSSD(n) || ZNSSD(n)) { rp = n->to_poller[index_poller]; } // 收割已完成的请求并存入优先队列 while (femu_ring_count(rp)) { req = NULL; rc = femu_ring_dequeue(rp, (void *)&req, 1); if (rc != 1) { femu_err("dequeue from to_poller request failed\n"); } assert(req); pqueue_insert(pq, req); } while ((req = pqueue_peek(pq))) { now = qemu_clock_get_ns(QEMU_CLOCK_REALTIME); // 如果当前时间还没到请求的到期时间,说明硬件“还没忙完”。 // 因为 pq 是排序的,如果最快的一个都没到期,后面的肯定也没到期,直接跳出循环。 if (now < req->expire_time) { break; } cq = n->cq[req->sq->sqid]; if (!cq->is_active) continue; // 填充 CQE (Completion Queue Entry) 并通知虚拟机 nvme_post_cqe(cq, req); // 将 req 放回 submission queue 的空闲列表中,供下次 IO 使用。 QTAILQ_INSERT_TAIL(&req->sq->req_list, req, entry); pqueue_pop(pq); processed++; n->nr_tt_ios++; // 原理:理想情况下 now 应该等于 expire_time。 // 如果 diff > 20,000ns (20微秒),说明 FEMU 的轮询线程太忙了,处理晚了。 if (now - req->expire_time >= 20000) { n->nr_tt_late_ios++; if (n->print_log) { femu_debug("%s,diff,pq.count=%lu,%" PRId64 ", %lu/%lu\n", n->devname, pqueue_size(pq), now - req->expire_time, n->nr_tt_late_ios, n->nr_tt_ios); } } n->should_isr[req->sq->sqid] = true; } if (processed == 0) return; switch (n->multipoller_enabled) { case 1: nvme_isr_notify_io(n->cq[index_poller]); break; default: for (i = 1; i <= n->nr_io_queues; i++) { if (n->should_isr[i]) { nvme_isr_notify_io(n->cq[i]); n->should_isr[i] = false; } } break; }
}