前言
MinHash LSH 是一种高效的近似近邻搜索算法,结合了 MinHash 签名和 Locality-Sensitive Hashing(局部敏感哈希,LSH) 两种技术,核心目标是在大规模高维数据集(如文本、图像特征、用户行为向量)中,快速找到相似度高的元素对,同时大幅降低计算和存储成本。
参考资料:
- RS推荐系统-LSH最近邻查找+MiniHash
- LLM洗数据[MinHash LSH去重] 总结笔记
- 一文读懂局部敏感哈希(LSH)算法
- Min-Hash & LSH
- Milvus week | 官宣:Milvus2.6发布MinHash LSH ,低成本去重百亿文档,加速大模型训练
算法过程介绍
算法总览
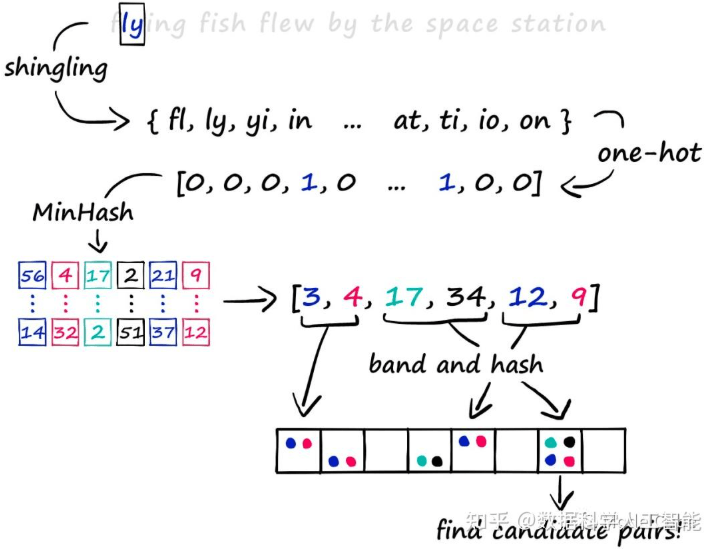
算法的总体流程如上图所示,大体包含三个步骤:
- 通过shingling和one-hot将一段文本转换为布尔向量(维度是n)
- 通过MinHash将上述布尔向量转换为哈希签名(维度是m,且m远小于n从而达到降维的目的)
- 通过LSH将每个哈希签名映射到不同的桶中
shingling+one-hot
Shingle(子串 / 词片):指从文本或序列中截取的连续长度为 k 的子单元,子单元可以是字符或单词
k-shingling:对目标文本提取所有不重复的 k-shingle,构成一个集合(集合特性:元素无序、无重复),这个集合就是该文本的 k-shingle 特征表示。
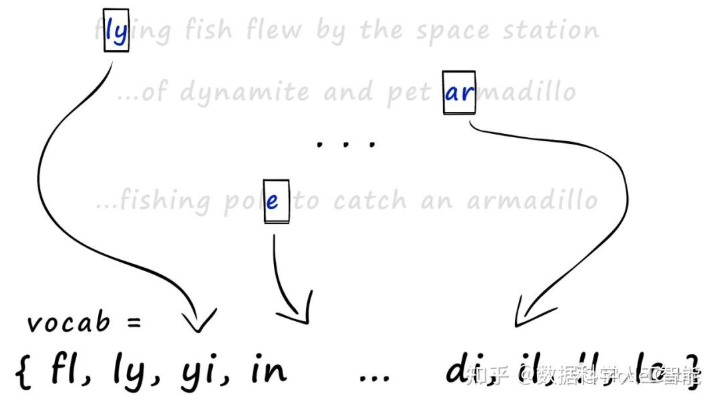
比如有一段很长的文本,我们可以通过shingling得到这个文本的词表(或者成为词袋),如下所示(词表需要进行去重)
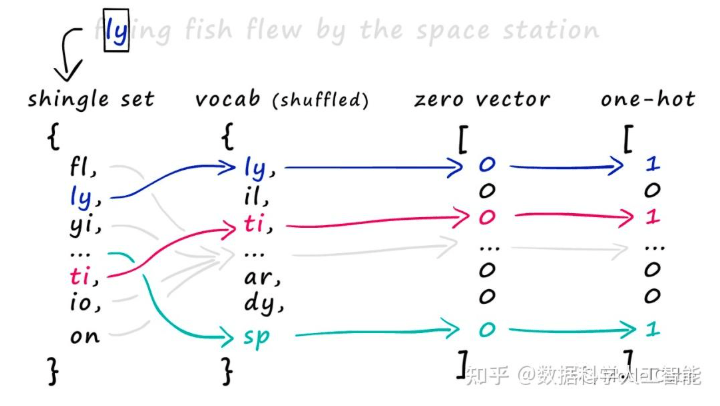
创建词表之后,对于一段文本t,我们就可以通过对照词表,使用one-hot编码,将文本t转换为布尔向量v
一个例子见下图,对于一段文本,我们将其shingling成集合shingle set后,对照词表vocab进行one-hot编码,由于shingle set中包含"ly"这个shingle,故对应于vocab的one-hot编码的第一个位置就为1,同理,shingle set中包含"ti"这个shingle,故对应于vocab的one-hot编码的第一个位置就为1,以此类推,我们就得到一个很长的01向量,向量维度就是词表中shingle的个数
Jaccard相似度
如果我们量化两个文本t1和t2的相似度,就可以按照shingling+one-hot的方法,将文本先分别转换为两个布尔向量v1和v2,然后再求Jaccard相似度,其公式为:
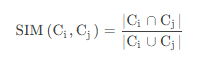
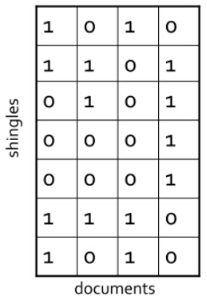
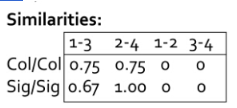
直接用例子来说明,现在有四个文本,对应表格中的每一列,现在求前两个文本的相似度,使用上述公式,分子为2(同时为1的次数),分母为5,因此最终相似度为0.4
MinHash
当词表中不重复的shingle过多时,上述得到的布尔向量的维度就会很大,在向量检索时,求不同向量间的Jaccard相似度开销就会变大。MinHash则可以通过将上述布尔向量转换为多个哈希签名来进行降维。
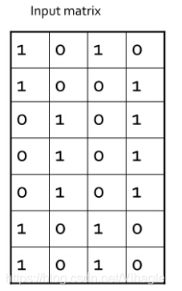
假设有4个文本,每个文本原来的布尔向量维度是7,且我们想通过MinHash将这个7维降为3维,那么MinHash的步骤如下:(下图展现的是原始的布尔向量矩阵,每一列代表一个文本)
step1.随机生成3个1-7的全排列
例如:
h1:3 1 6 2 7 4 5
h2:3 2 4 1 6 5 7
h3:......
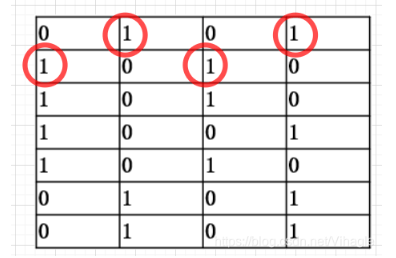
step2.分别将原来的布尔向量矩阵的行依次按照每个全排列进行重排,例如,对于h1和h2重排后因此得到下面两个矩阵mh1和mh2

step3.每个矩阵通过取出每列首个为1的行数就可以生成一行哈希签名,以mh1为例,第1列首个1的行数为2,第2列首个1的行数为1,第3列为2,第4列为1,所以最终可以得到(2121)这个hash后的数值
重复step3,生成m个hash后的数值,从而得到下面的哈希签名矩阵
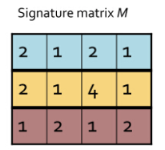
得到这个有什么用呢,发现如果此时我们去比较不同哈希签名间的jaccard相似度只需要处理3个维度,而不是原来布尔向量的7个维度,但哈希签名的jaccard相似度可以取代布尔向量的jaccard吗,我们可以验证一下
如下图所示,第1行为原输入矩阵的Jaccard相似度,第2行为通过MiniHash降维后得到的Signature Metrix的Jaccard相似度。可以看出降维前后的相似度差距不是很大,但是两者之间的计算时间+空间量级得到了大大压缩。精度换时间,何乐而不为~
LSH
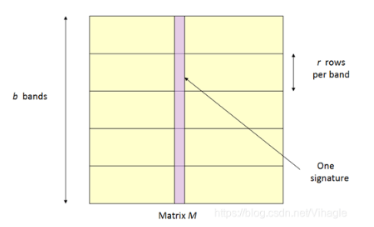
假设有很多文本经过了前两步得到了一个很大的哈希签名矩阵,矩阵的每个列代表原来的一段文本。
需要将这个矩阵分成b组(b个bands),每一组有r行,且每一个band拥有独立的桶空间。
然后对每一组的所有列分别进行hash,映射到不同的桶中。对于两个列,只要任意一组能够hash到同一个桶中,那么这两个列就可以成为相似项
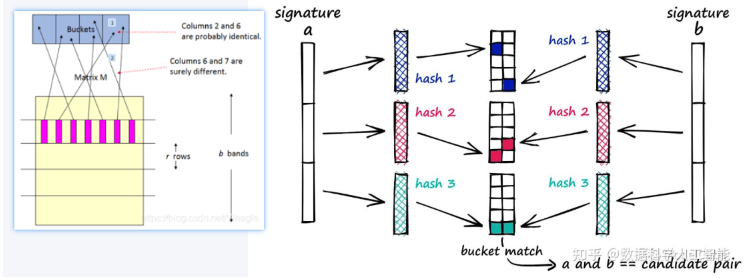
举一个简单的例子
有两个文章,文章 A和文章B
设置哈希签名的维数num_perm=128,经过前两个步骤后,可以得到各自的minHash签名:
-
文章 A 的签名: [5, 7, 3, 9, ..., 42](128个数字)
-
文章 B 的签名: [5, 7, 4, 9, ..., 43](128个数字)
接下来进行LSH,设band=32,则每个band中有4个值
文章A的签名 [5, 7, 3, 9, ..., 42] 分段:Band 1:[5, 7, 3, 9](前 4 位)... Band 32:[最后 4 位,比如 39, 41, 43, 42]
文章B的签名 [5, 7, 4, 9, ..., 43] 分段:Band 1:[5, 7, 4, 9](前 4 位)... Band 32:[最后 4 位,比如 39, 41, 42, 43]
每个Band有不同的桶空间:
对于第一个桶空间(Band1),对A的Band1进行哈希(此处的哈希函数简单设为各数相加)得到24,对B的Band1进行哈希得到25,设桶的个数100,A的Band1在桶24中,B的Band1在桶25中,不在一个桶
...
对于第三十二个桶空间(Band32),对A的Band32进行哈希(此处的哈希函数简单设为各数相加)得到165,对B的Band1进行哈希得到165,设桶的个数100,A的Band1在桶65中,B的Band1在桶65中,在一个桶
因此A和B是相似候选对
对LSH的理解
MinHash-LSH的第三步LSH的目的就是减少要与查询向量(实际上是哈希签名)进行jaccard相似度计算的向量总数(实际上是哈希签名)。
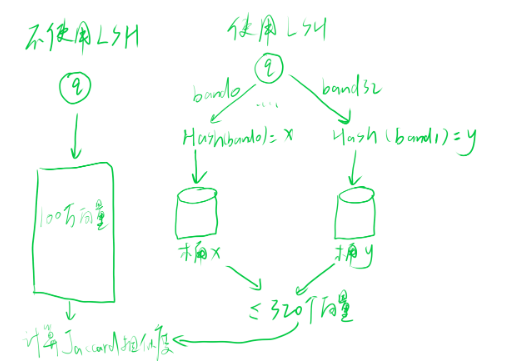
如下图所示,假设现在向量数据库中已经存储了100万个向量(哈希签名),如果不使用LSH,需要对一个查询向量计算100万次jaccard相似度,如果使用LSH:假设一个哈希签名有32个band,不同band拥有独立的桶空间,每个band有10万个桶,(平均一个桶中映射10个向量),则总共有320万个桶。此时,对一个查询向量的32个band各自会映射到一个桶中,平均可以取到320个向量(实际情况远低于320,因为每个band对应的桶中的向量id存在大量重复的),此时就只需要计算320次jaccard相似度。
使用MinHash-LSH进行向量检索总结
在通过上述过程构建了完整的LSH之后,对于一个要查询的向量,首先会计算其哈希签名,然后得到所在多个桶(每个band各一个)的id,然后就可以获取所有候选向量的哈希签名,之后就是计算该查询向量的哈希签名与所有候选向量的哈希签名的Jaccard相似度,最终排序得到top-K返回结果。
算法适用场景与局限性
适用场景
MinHash-LSH 是为集合 / 布尔向量和Jaccard 相似度度量设计的检索技术,在向量数据库中主要适配以下场景:
- 文档/数据去重:MinHash-LSH在向量数据库中的存储是基于词袋的,可以快速识别表明意思重复或冗余的文档
- 粗筛预处理:在语义检索场景中,MinHash-LSH可作为前置粗筛模块,先通过词汇重叠度筛选出与查询文本词汇相关的候选向量,再将候选集送入 HNSW、IVF 等适配语义 embedding 的 ANNS 索引做精准检索,大幅缩小后续检索范围
局限性
- 仅适配 Jaccard 相似度,不兼容语义检索:无法处理基于余弦 / 欧式距离的语义 embedding 向量。对于 “同义不同词” 的语义关联(如 “新能源车” 和 “电动汽车”),因其词汇集合重叠度低,会被判定为不相似,无法满足语义检索需求。如果想作为前置粗筛模块,后续与embedding索引结合,则向量数据库通常需要存储两套向量表示
- 不适配稠密实数向量的直接检索:对语义 embedding 这类稠密实数向量,需先将其转化为集合 / 布尔向量才能处理,该转化过程会丢失语义信息,导致后续检索失去语义关联性,因此无法作为稠密向量的核心检索算法