TCP/IP介绍
1.定义:TCP/IP(Transmission Control Protocol/Internet Protocol)是一套用于互联网及局域网的分层网络通信协议簇,包含 TCP(传输层协议)和 IP(网络层协议),以及链路层、应用层等配套协议,是当前互联网的基础通信标准。
2.核心特点:
- 可靠性保障:通过三次握手建立连接、四次挥手断开连接、序列号 / 确认应答(ACK)、重传机制、流量控制(滑动窗口)、拥塞控制(慢启动、拥塞避免)等机制,确保数据有序、无丢失、无重复传输。
- 分层处理:遵循 TCP/IP 五层模型(物理层、数据链路层、网络层、传输层、应用层),每层完成独立功能并向上层提供服务,例如:
- IP 层负责路由寻址,将数据包从源主机转发到目标主机;
- TCP 层负责端到端的可靠传输,处理数据的分段、重组和可靠性校验。
- 内核参与转发:数据传输时,需要经过操作系统内核的协议栈处理(如 TCP 头部解析、拥塞控制计算),再通过系统调用完成用户态与内核态的切换。
3.优缺点:
- 优点:
- 通用性强:支持所有网络拓扑和设备,是互联网的通用标准;
- 可靠性高:通过完整的校验和重传机制,适配复杂的公网环境;
- 兼容性好:几乎所有操作系统和网络设备都原生支持。
- 缺点:
- 开销大:内核协议栈处理、用户态 / 内核态切换、TCP 头部校验等会产生显著延迟
- CPU 占用高:协议栈的复杂计算会消耗大量 CPU 资源,难以满足超高吞吐和超低延迟场景
4.应用场景: 适用于对通用性和可靠性要求高于极致性能的场景,例如互联网网页访问、远程登录(SSH)、文件传输(FTP)
RDMA介绍
1.定义:RDMA(Remote Direct Memory Access,远程直接内存访问)是一种高性能网络通信技术,允许一台主机的应用程序直接访问另一台主机的内存,无需经过操作系统内核和 CPU 中转,从而实现超低延迟、高吞吐量的通信。
2.核心特点:
- 用户态直接通信:应用程序绕过内核协议栈,直接通过 RDMA 网卡(RNIC)完成数据传输,无用户态 / 内核态切换
- 远程内存直接访问:通过内存注册和地址映射,本地应用可直接读写远端主机的内存区域,无需远端 CPU 参与数据拷贝
- 无连接 / 连接两种模式:其中可靠连接RC类似TCP的可靠传输,适用于关键业务;无连接UD类似UDP不可靠传输,适用于低延迟广播场景
- 硬件卸载:将通信协议的校验、封装、拥塞控制等操作卸载到 RDMA 网卡,释放主机 CPU 资源
3.优缺点:
- 优点:
- 超低延迟:无内核中转和 CPU 参与,延迟可降至微秒级甚至亚微秒级
- 高吞吐量:硬件卸载和直接内存访问支持数十 Gbps 甚至上百 Gbps 的带宽
- CPU 占用低:通信操作由网卡硬件完成,主机 CPU 可专注于业务计算
- 缺点:
- 部署成本高:需要专用 RDMA 网卡和配套交换机(如 InfiniBand 交换机)
- 通用性差:不支持公网环境,主要用于数据中心内部
- 编程复杂度高:需要处理内存注册、队列管理等底层细节,开发门槛高于 TCP/IP
4.应用场景:适用于对延迟和吞吐量有极致要求的高性能计算和数据中心场景,例如分布式存储、高性能计算、AI训练集群
通信流程案例
我们以A 主机应用程序向 B 主机内存写入数据为例,分别拆解 TCP/IP 和 RDMA 的完整通信流程,清晰呈现二者的核心差异
TCP/IP通信流程
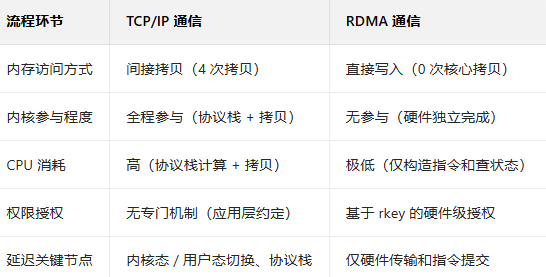
TCP/IP 通信中,A 无法直接访问 B 的内存,需通过 “应用层数据交互 + 内核 / 用户态拷贝” 间接实现,整体流程分为连接建立、数据传输、连接断开三个阶段,涉及多层协议栈和多次内存拷贝。
step1.前期准备:
A主机:应用程序在用户态分配发送缓冲区,写入待传输数据,调用 socket() 接口创建 TCP 套接字,绑定端口并调用 connect() 发起连接请求
B主机:应用程序在用户态分配接收缓冲区,用于存储最终数据,调用 socket() 创建套接字,绑定端口后调用 listen() 监听连接,再调用 accept() 等待客户端连接
step2.建立连接:(TCP三次握手)
A 向 B 发送SYN 报文,请求建立连接、B 收到后回复SYN+ACK 报文,确认同步并同步自身序列号、A 再回复ACK 报文,TCP 连接正式建立。此阶段全程由内核协议栈处理,不涉及用户应用程序
step3.数据传输:
A 主机用户态→内核态拷贝:A 应用调用 send() 系统调用,将用户态发送缓冲区的数据拷贝到内核态的 TCP 发送缓冲区,触发用户态 / 内核态切换。
A 主机内核协议栈处理:内核对数据进行 TCP 分段、添加 TCP/IP 协议头、计算校验和,再将数据包传递到数据链路层,封装成以太网帧后通过网卡发送。
B 主机接收与协议栈处理:B 网卡收到以太网帧后,先传递到内核链路层,逐层剥离协议头(以太网→IP→TCP),校验通过后将数据存入内核态的 TCP 接收缓冲区。
B 主机内核态→用户态拷贝:B 应用调用 recv() 系统调用,触发用户态 / 内核态切换,内核将接收缓冲区的数据拷贝到应用的用户态接收缓冲区,完成数据写入。
step4.连接断开:
A 调用 close() 发送FIN 报文,请求断开连接、B 回复ACK 报文确认,同时自身若无数据发送则发送FIN 报文、1. A 回复ACK 报文,连接正式断开。
RDMA通信流程
RDMA 支持 A 应用绕过内核直接读写 B 的内存,以可靠连接(RC)模式为例,流程分为资源初始化、内存注册与授权、数据传输三个阶段,无内核中转和多余拷贝。
step1.前期准备:
A/B主机通用步骤:1. 初始化 RDMA 环境,加载 Verbs 驱动,获取 RDMA 网卡(RNIC)的设备上下文、2.创建保护域(PD):隔离不同应用的 RDMA 资源,避免冲突、3.创建队列对(QP):每个 QP 包含发送队列(SQ)和接收队列(RQ),用于收发 RDMA 指令 4.创建完成队列(CQ):用于通知应用程序 RDMA 操作的完成状态
step2.内存注册与地址授权
B主机:在用户态分配目标内存区域(MR)、调用 ibv_reg_mr() 注册该内存,RNIC 会锁定此内存区域(防止被系统换出),并生成内存键(rkey) 和 内存句柄(lkey) 、通过带外通道(如 TCP/IP 或共享配置),将该内存的远程地址(VA)、内存长度和rkey发送给 A 主机(rkey 是 A 访问该内存的权限凭证)、调用 ibv_modify_qp() 将 QP 状态切换为 “可连接”,等待 A 建立 RDMA 连接
A主机:接收 B 发送的内存地址、长度和 rkey,保存到本地、调用 ibv_modify_qp() 向 B 发起 QP 连接请求,双方完成 RDMA 连接建立(类似 TCP 握手,但由硬件完成)
step3.数据传输
- A 主机构造 RDMA 写指令:A 应用在用户态构造RDMA_WRITE 请求,指定参数:本地待发送数据的内存地址和长度、B 主机的目标内存地址、rkey;将该请求提交到本地 QP 的发送队列(SQ)
- RNIC 硬件执行传输:A 的 RNIC 直接读取本地用户态内存的数据,通过 RDMA 网络发送到 B 的 RNIC,全程无用户态 / 内核态切换,无主机 CPU 参与
- B 主机 RNIC 写入内存:B 的 RNIC 收到数据后,通过 rkey 验证访问权限,直接将数据写入已注册的目标内存区域,无需 B 的 CPU 和内核介入
- 完成通知:B 的 RNIC 向 CQ 发送完成事件,B 应用通过轮询或中断感知到内存写入完成,可直接访问该内存数据
step4.后续清理
通信结束后,双方调用接口释放 QP、PD、MR 等资源,断开 RDMA 连接
总体比较